Die chinesische AI-Firma MiniMax hat offiziell angekündigt, dass sie ihre neueste große Sprachmodell (LLM) MiniMax-M1 unter Opensource veröffentlichen wird. Das Modell hat weltweit Aufmerksamkeit erregt, insbesondere wegen seiner außergewöhnlichen Fähigkeit zur inferenzfähigen Analyse langer Kontexte und der effizienten Trainingskosten. AIbase sammelt die neuesten Informationen und bietet eine umfassende Interpretation von MiniMax-M1.
Bemerkenswertes Kontextfenster: 1 Million Eingaben, 80 Tausend Ausgaben
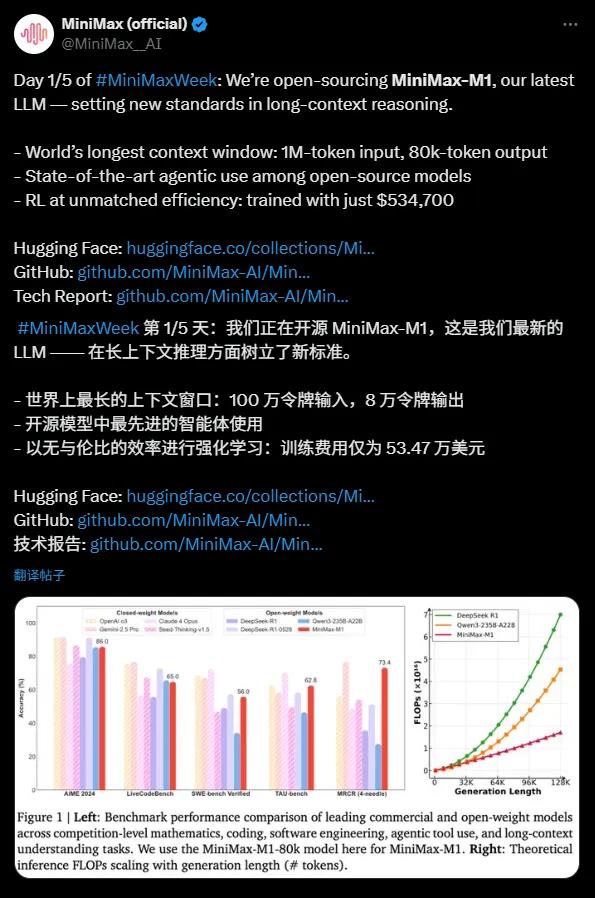
MiniMax-M1 ist mit einem erstaunlichen Kontextfenster von 1 Million Tokens Eingabe und 80 Tausend Tokens Ausgabe das derzeit bestmögliche Open-Source-Modell für lange Kontextinferenzen. Diese Fähigkeit ermöglicht es dem Modell, gleichzeitig Informationen zu verarbeiten, die der Größe eines Romans oder sogar einer ganzen Buchserie entsprechen, weit über dem Kontextfenster von OpenAI GPT-4o mit 128.000 Tokens hinaus. Ob es um komplexe Dokumentenanalyse, längere Codegenerierung oder mehrstufige Gespräche geht, MiniMax-M1 bewährt sich dabei souverän und bietet Unternehmen und Entwicklern ein starkes Werkzeug.
Pionier der Proxy-Kapazität in Open-Source-Modellen
MiniMax-M1 zeigt außerordentlich gute Leistungen im Umgang mit Proxy-Tools, wobei seine Leistung den Top-Commercial-Modellen wie OpenAI o3 und Claude4Opus nahekommt. Dank seiner Kombination aus dem Mixture-of-Experts-Modell (MoE) und dem Lightning-Attention-Mechanismus zeigt MiniMax-M1 bei komplexen Aufgaben wie Software-Ingenieurwesen, Toolaufruf und langen Kontextinferenzen eine Leistungsfähigkeit nahe dem aktuellen Stand der Technik. Diese starke Proxy-Kapazität des Open-Source-Modells bietet der globalen Entwicklercommunity neue Möglichkeiten.

Hohe Wirtschaftlichkeit: 534.700 USD für ein avantgardistisches LLM
Das Trainingsbudget von MiniMax-M1 ist bemerkenswert: lediglich 534.700 USD, verglichen mit 5 bis 6 Millionen USD für DeepSeek R1 und über 100 Millionen USD für OpenAI GPT-4. Dieser "günstige Meilenstein" wurde möglich durch effizientes verstärktes Lernen (RL) und nur 512 H800-GPUs. Zusätzlich verbesserte MiniMax mit seiner innovativen CISPO-Optimierungsalgorithmus die Inferenzleistung und reduzierte Kosten, während wichtige Informationen erhalten blieben.
Technische Highlights: 456 Milliarden Parameter und effiziente Architektur
MiniMax-M1 basiert auf MiniMax-Text-01 und hat insgesamt 456 Milliarden Parameter, wobei jeder Token etwa 45,9 Milliarden Parameter aktiviert. Mit der MoE-Architektur wird effizientes Rechnen erreicht. Das Modell unterstützt zwei Denkschranken von 40k und 80k Tokens, um unterschiedliche Anwendungsszenarien zu bedienen. Bei Benchmarktests für mathematische und kodierungsintensive Aufgaben übertrifft MiniMax-M1 Modelle wie DeepSeek R1 und Qwen3-235B-A22B.
Milestone für die Open-Source-Ekosysteme
MiniMax-M1 wird unter der Apache2.0-Lizenz veröffentlicht und ist auf der Hugging Face-Plattform für alle Entwickler weltweit kostenlos verfügbar. Dieser Schritt stellt nicht nur andere chinesische AI-Unternehmen wie DeepSeek heraus, sondern belebt auch das globale AI-Ekosystem. MiniMax kündigte an, weitere technische Details zu veröffentlichen, um Innovationen in der Open-Source-Community voranzutreiben.
Die Veröffentlichung von MiniMax-M1 markiert einen bedeutenden Durchbruch in der Kapazität für lange Kontextinferenzen und Proxyfähigkeiten in Open-Source-Modellen. Sein außergewöhnliches Kontextfenster, effiziente Trainingskosten und leistungsstarke Performanz bieten Unternehmen und Entwicklern kostengünstige Lösungen. AIbase glaubt, dass die Opensourcing von MiniMax-M1 die Anwendung von AI-Technologien in komplexen Szenarien beschleunigen und den globalen AI-Ekosystemen neue Höhen erreichen lassen wird.