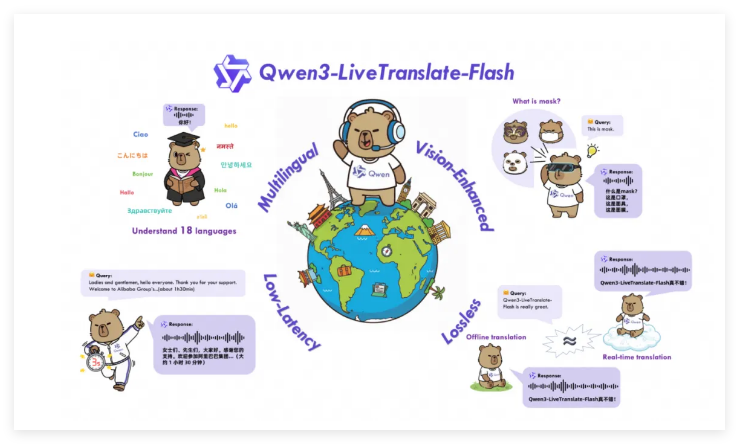
Die Methode der LLM-gestützten Videodiffusion (LVD) löst das Problem der Generierung komplexer, dynamischer Videos im Raum und in der Zeit, indem sie dynamische Szenenlayouts mithilfe von LLMs erstellt. LLMs zeigen überraschende Fähigkeiten und verbessern die Qualität der Text-zu-Video-Generierung, was neue Möglichkeiten in den Bereichen Content Creation und Videogenerierung eröffnet.
LLM-gestützte Videodiffusion (LVD): Ein bahnbrechender Ansatz zur Text-zu-Video-Generierung
站长之家
102
Dieser Artikel stammt aus dem AIbase-Tagesbericht
Willkommen im Bereich [KI-Tagesbericht]! Hier ist Ihr Leitfaden, um jeden Tag die Welt der künstlichen Intelligenz zu erkunden. Jeden Tag präsentieren wir Ihnen die Hotspots im KI-Bereich, konzentrieren uns auf Entwickler und helfen Ihnen, technologische Trends zu erkennen und innovative KI-Produktanwendungen zu verstehen.
—— Erstellt von der AIbase-Tagesberichtgruppe
© Alle Rechte vorbehalten AIbase-Basis 2024, klicken Sie hier, um die Quelle anzuzeigen -