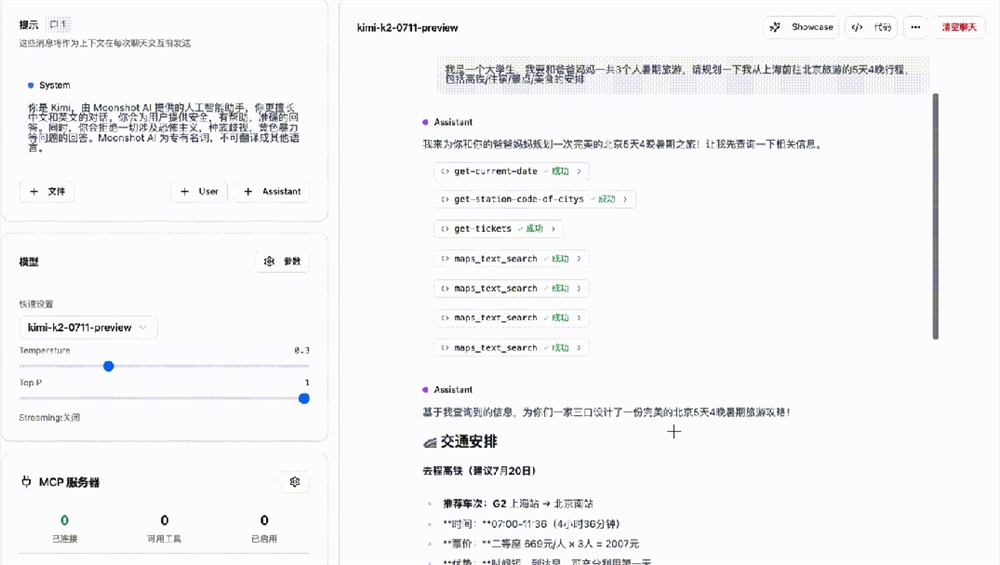
Recientemente, Quwan Technology lanzó un nuevo modelo de síntesis de voz (TTS) llamado MaskGCT, que ha logrado avances significativos en calidad de voz, similitud y controlabilidad, revolucionando la forma tradicional de síntesis de voz (TTS) y permitiendo que la IA se libere completamente de la dependencia de la anotación manual, logrando un verdadero "autoaprendizaje".

Los sistemas TTS tradicionales son como un niño mimado al que se le debe enseñar a hablar palabra por palabra manualmente, alineando primero el texto y el audio, luego prediciendo la duración de cada sílaba, para finalmente lograr una síntesis de voz entrecortada. Este método no solo es ineficiente, sino que también produce una voz que carece de ritmo natural y fluido.
Sin embargo, MaskGCT de Quwan Technology abandona por completo este antiguo modelo. Utiliza una arquitectura de transformador de codificador-decodificador generativo enmascarado. En pocas palabras, utiliza un modelo similar a BERT para convertir primero el audio en características semánticas, y luego, utilizando otro modelo, predice las características acústicas para finalmente sintetizar el audio.
El mayor atractivo de este método es que no requiere anotación manual. Se entrena directamente con 100,000 horas de datos de voz no etiquetados, permitiendo que el modelo aprenda por sí mismo la relación entre el texto y el audio a partir de una gran cantidad de datos.
Es como dejar a un niño en un entorno lingüístico para que explore y aprenda, dominando el lenguaje de forma natural.
Otra característica impresionante de MaskGCT es su capacidad para controlar la duración del audio de forma flexible, como lo haría una persona, pudiendo acelerar o ralentizar la velocidad. Esto es una gran ventaja para la doblaje o edición de audio.
Los resultados experimentales demuestran la potencia de MaskGCT. En cuanto a la calidad de audio, similitud, ritmo y claridad, supera a los sistemas TTS existentes, incluso alcanzando un nivel comparable al de un ser humano.
Lo que es aún más sorprendente es que MaskGCT no solo puede generar audio de alta calidad, sino que también puede imitar los estilos de diferentes hablantes e incluso realizar traducciones de voz entre idiomas, convirtiéndose en un verdadero todoterreno.
Por supuesto, MaskGCT aún presenta algunas limitaciones, como la posible aparición de imperfecciones al procesar la síntesis de voz con posturas faciales muy pronunciadas. Sin embargo, sus virtudes superan sus defectos. La aparición de MaskGCT ha abierto sin duda nuevas posibilidades en el campo de la TTS y ofrece un inmenso potencial para la experiencia futura de interacción humano-máquina.
Prueba online: https://huggingface.co/spaces/amphion/maskgct
Dirección del proyecto: https://github.com/open-mmlab/Amphion/tree/main/models/tts/maskgct
Dirección del sitio web: https://voice.funnycp.com/