Recientemente, el equipo de modelos de lenguaje grande Doubao de ByteDance anunció la publicación de código abierto de Multi-SWE-bench, el primer conjunto de datos de referencia para la reparación de código multilingüe de la industria, lo que supone un nuevo avance en la evaluación y mejora de la capacidad de los grandes modelos para "corregir errores automáticamente".
En el contexto del rápido desarrollo de la tecnología de grandes modelos, las tareas de generación de código se han convertido en un área clave para probar la inteligencia de los modelos. Los conjuntos de datos de referencia para la reparación de código, como SWE-bench, aunque pueden medir la inteligencia de programación de los modelos, presentan limitaciones significativas. Se centran únicamente en el lenguaje Python, lo que impide evaluar la capacidad de generalización entre lenguajes del modelo; además, la dificultad de las tareas es limitada, lo que dificulta la cobertura de escenarios de desarrollo complejos y restringe el desarrollo de la inteligencia de código de los grandes modelos.

Puntuaciones de evaluación de la capacidad de código de diferentes modelos
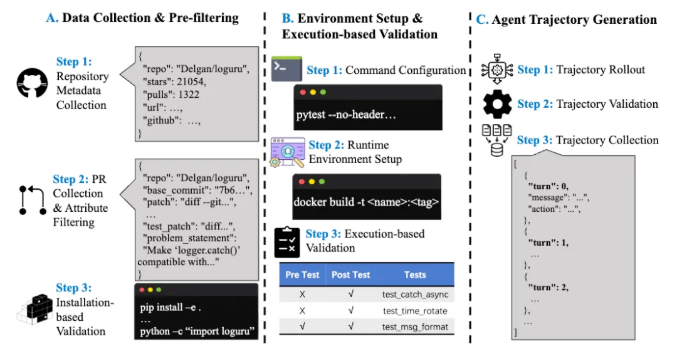
Multi-SWE-bench surge para solucionar estas limitaciones, superando significativamente a SWE-bench. Por primera vez, abarca 7 lenguajes de programación principales: Java, TypeScript, C, C++, Go, Rust y JavaScript, construyendo 1632 tareas de reparación procedentes de repositorios de código abierto reales. Estas tareas han sido rigurosamente seleccionadas y verificadas manualmente para garantizar su fiabilidad. Además, Multi-SWE-bench incorpora un mecanismo de clasificación de dificultad, dividiendo las tareas en tres niveles: fácil, medio y difícil, lo que permite una evaluación más completa del rendimiento del modelo en diferentes niveles de capacidad.
Los experimentos basados en este conjunto de datos muestran que los modelos de lenguaje grande actuales presentan un rendimiento aceptable en la reparación de código Python, pero la tasa de reparación media para otros lenguajes es inferior al 10%, lo que pone de manifiesto que la reparación de código multilingüe sigue siendo un desafío para los grandes modelos.

Algunos modelos principales muestran un rendimiento superior en Python, mientras que sus resultados son deficientes en otros lenguajes. Además, la tasa de reparación de los modelos disminuye a medida que aumenta la dificultad de la tarea.
Para facilitar la aplicación del aprendizaje por refuerzo en el ámbito de la programación automática, el equipo también ha publicado Multi-SWE-RL, que proporciona 4723 ejemplos y un entorno Docker reproducible, con funciones de inicio con un solo clic y evaluación automática, creando una base de datos estandarizada para el entrenamiento de RL. Además, el equipo ha lanzado un plan para la comunidad de código abierto, invitando a desarrolladores e investigadores a participar en la ampliación del conjunto de datos, la evaluación de nuevos métodos, etc., para promover conjuntamente el desarrollo del ecosistema RL for Code.
El equipo de modelos de lenguaje grande Doubao de ByteDance espera que Multi-SWE-bench impulse la tecnología de programación automática a nuevas cotas, y en el futuro seguirá ampliando su cobertura para ayudar a los grandes modelos a lograr mayores avances en el campo de la "ingeniería de software automatizada".