La société chinoise d'intelligence artificielle MiniMax a officiellement annoncé l'ouverture du code de son tout dernier modèle de langue large (LLM) MiniMax-M1, qui s'est attiré une attention mondiale grâce à sa capacité exceptionnelle d'inférence avec de longues séquences contextuelles et ses coûts de formation efficaces. AIbase résume les informations les plus récentes pour vous offrir une analyse complète de MiniMax-M1.
Record de fenêtre contextuelle : 1 million d'entrées, 80 mille sorties
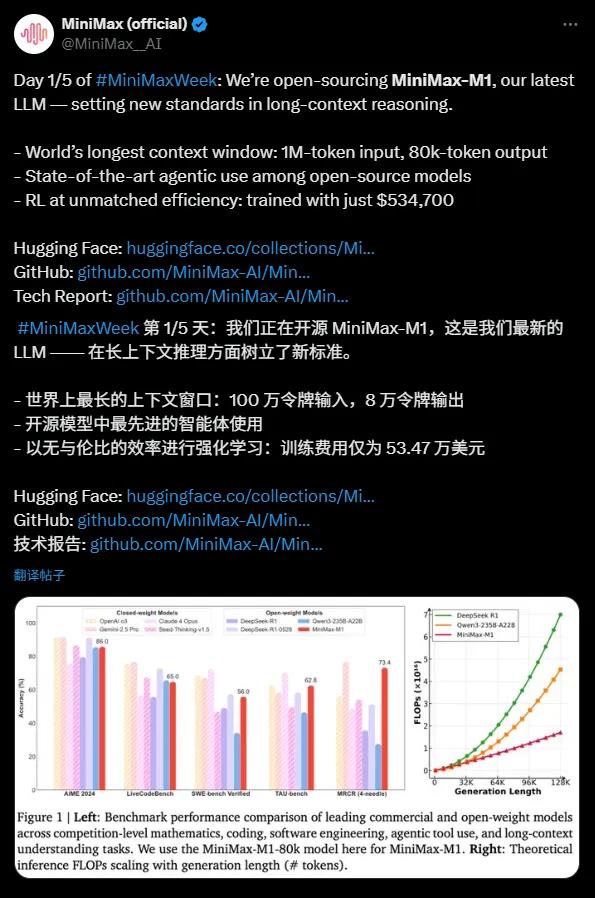
MiniMax-M1 se distingue par sa fenêtre contextuelle impressionnante, capable de traiter jusqu'à 1 million de tokens en entrée et 80 mille tokens en sortie. Cela en fait actuellement le meilleur modèle open source pour l'inférence avec de longues séquences. Cette capacité signifie que le modèle peut gérer simultanément une quantité d'informations équivalente à un roman entier, voire à toute une série de livres, surpassant largement la fenêtre contextuelle de 128 mille tokens d'OpenAI GPT-4. Que ce soit pour l'analyse de documents complexes, la génération de code longs ou les conversations multirondes, MiniMax-M1 s'en sort avec aisance, fournissant des outils puissants aux entreprises et développeurs.
Pionnier des capacités d'agent dans les modèles open source
MiniMax-M1 excelle également dans l'utilisation d'outils d'agents, performant presque à égalité avec des modèles commerciaux de premier plan comme OpenAI o3 et Claude4Opus. Grâce à son architecture mixte de modèles experts (MoE) combinée à la mécanique Lightning Attention, MiniMax-M1 affiche des performances proches de l'avant-garde dans des tâches complexes comme l'ingénierie logicielle, l'appel d'outils et l'inférence avec de longues séquences contextuelles. Cette capacité puissante pour les modèles open source offre aux communautés mondiales de développeurs des opportunités sans précédent.

Économie exceptionnelle : 534 700 dollars pour créer un LLM avant-gardiste
Le coût de formation de MiniMax-M1 est remarquable : seulement 534 700 dollars, comparé à 5 à 6 millions de dollars pour DeepSeek R1 et plus de 100 millions pour OpenAI GPT-4, ce qui en fait un véritable « miracle économique ». En utilisant des techniques efficaces d'apprentissage par renforcement (RL) et un matériel limité à 512 GPU H800, MiniMax a accompli le développement du modèle en seulement trois semaines. De plus, MiniMax a développé un algorithme d'optimisation CISPO qui améliore encore l'efficacité de l'inférence, tout en assurant la préservation des informations essentielles et en réduisant les coûts de formation.
Points techniques : 456 milliards de paramètres et architecture efficace
MiniMax-M1 est basé sur MiniMax-Text-01 et compte un total de 456 milliards de paramètres, avec environ 45,9 millions de paramètres activés par token, réalisant un calcul efficace via l'architecture MoE. Le modèle prend en charge deux modes d'inférence : 40 mille et 80 mille budgets de pensée, répondant ainsi aux besoins variés des scénarios. Dans les benchmarks pour des tâches intensives de raisonnement telles que les mathématiques et le codage, MiniMax-M1 s'est distingué et a surpassé des modèles comme DeepSeek R1 et Qwen3-235B-A22B.
Un jalon pour l'écosystème open source
MiniMax-M1 est disponible sous licence Apache2.0 et est accessible sur la plateforme Hugging Face, gratuite pour tous les développeurs mondiaux. Cette initiative remet en question les modèles open source d'autres entreprises chinoises comme DeepSeek et injecte une nouvelle vitalité dans l'écosystème mondial de l'IA. MiniMax a indiqué qu'il publiera davantage de détails techniques dans le futur, contribuant ainsi à innover dans la communauté open source.
La publication de MiniMax-M1 marque un grand bond en avant dans les capacités d'inférence avec de longues séquences et les compétences des agents dans les modèles open source. Sa fenêtre contextuelle étendue, ses coûts de formation efficients et ses performances exceptionnelles offrent des solutions très rentables aux entreprises et développeurs. AIbase pense que l'ouverture de MiniMax-M1 accélérera l'adoption de l'IA dans des tâches complexes, propulsant ainsi l'écosystème mondial de l'IA vers de nouveaux sommets.