हाल ही में, माइक्रोसॉफ्ट शोध दल ने आधिकारिक तौर पर BitNet b1.582B4T नामक एक ओपन-सोर्स बड़ा भाषा मॉडल जारी किया है। इस मॉडल में 2 बिलियन पैरामीटर हैं, और इसे एक अनोखे 1.58-बिट कम-परिशुद्धता आर्किटेक्चर का उपयोग करके मूल रूप से प्रशिक्षित किया गया है। पारंपरिक प्रशिक्षण-पश्चात् मात्राकरण विधियों की तुलना में, BitNet को कम्प्यूटेशनल संसाधनों की आवश्यकता में उल्लेखनीय कमी आई है। माइक्रोसॉफ्ट के अनुसार, गैर-एम्बेडेड मेमोरी उपयोग केवल 0.4GB है, जो बाजार में अन्य समान उत्पादों जैसे Gemma-31B के 1.4GB और MiniCPM2B के 4.8GB से काफी कम है।

BitNet का कुशल प्रदर्शन इसके नवीन आर्किटेक्चर डिज़ाइन के कारण है। मॉडल पारंपरिक 16-बिट संख्याओं को छोड़ देता है, बल्कि कस्टम BitLinear परत का उपयोग करता है, जो वज़न को -1, 0 और +1 तीन अवस्थाओं तक सीमित करता है, जिससे एक त्रिवर्गीय प्रणाली बनती है। इससे प्रत्येक वज़न को केवल लगभग 1.58 बिट्स सूचना संग्रहण की आवश्यकता होती है। इसके अतिरिक्त, परतों के बीच सक्रियण मानों को 8-बिट पूर्णांकों का उपयोग करके मात्राकरण किया जाता है, जिससे W1.58A8 कॉन्फ़िगरेशन बनता है। माइक्रोसॉफ्ट ने ट्रांसफॉर्मर आर्किटेक्चर में भी समायोजन किया है, जिसमें स्क्वेयर्ड ReLU सक्रियण फ़ंक्शन, मानक घूर्णन स्थिति एम्बेडिंग (RoPE) और subln सामान्यीकरण शामिल हैं, ताकि कम-बिट प्रशिक्षण की स्थिरता सुनिश्चित हो सके।

विकास प्रक्रिया में, BitNet तीन चरणों से गुजरा: सबसे पहले 4 ट्रिलियन टोकन के वेब डेटा, कोड और सिंथेटिक गणित डेटासेट का उपयोग करके पूर्व-प्रशिक्षण; फिर सार्वजनिक और सिंथेटिक निर्देश डेटासेट का उपयोग करके पर्यवेक्षित ठीक-ट्यूनिंग; और अंत में प्रत्यक्ष प्राथमिकता अनुकूलन (DPO) विधि का उपयोग करके, UltraFeedback जैसे डेटासेट का उपयोग करके मॉडल की वार्तालाप क्षमता और सुरक्षा में सुधार किया गया।
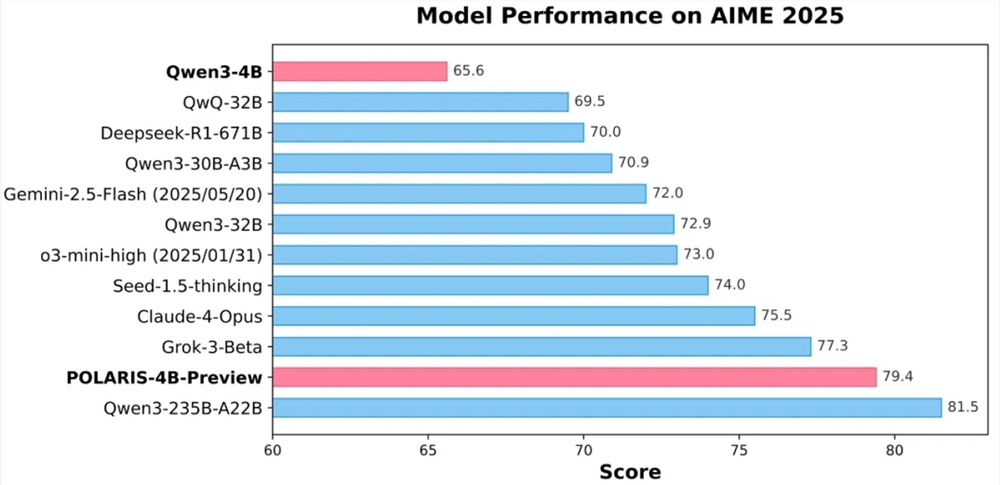
माइक्रोसॉफ्ट के परीक्षण परिणामों से पता चलता है कि BitNet GSM8K (गणित) और PIQA (भौतिक सामान्य ज्ञान) जैसे बेंचमार्क परीक्षणों में बहुत अच्छा प्रदर्शन करता है, और इसका समग्र प्रदर्शन मुख्यधारा के 1B-2B पैरामीटर पूर्ण-परिशुद्धता मॉडल के बराबर है, साथ ही ऊर्जा खपत (प्रति टोकन 0.028 जूल) और CPU डिकोडिंग विलंबता (29 मिलीसेकंड) में स्पष्ट लाभ है।
हालांकि BitNet ने बहुत बड़ी क्षमता दिखाई है, लेकिन इसकी दक्षता माइक्रोसॉफ्ट द्वारा प्रदान किए गए विशेष C++ ढांचे bitnet.cpp पर निर्भर करती है। Hugging Face ट्रांसफॉर्मर्स लाइब्रेरी जैसे सामान्य उपकरण इसकी गति और ऊर्जा खपत के लाभों को पूरी तरह से प्रदर्शित नहीं कर सकते हैं। माइक्रोसॉफ्ट भविष्य में GPU और NPU समर्थन को अनुकूलित करने, संदर्भ विंडो को 4096 टोकन तक विस्तारित करने और बड़े पैमाने पर मॉडल और बहुभाषी कार्यक्षमता का पता लगाने की योजना बना रहा है। वर्तमान में, BitNet b1.582B4T को MIT लाइसेंस के तहत Hugging Face प्लेटफॉर्म पर जारी किया गया है, ताकि व्यापक डेवलपर्स और शोधकर्ता परीक्षण और आवेदन कर सकें।
पेपर: https://arxiv.org/html/2504.12285v1
huggingface: https://huggingface.co/microsoft/bitnet-b1.58-2B-4T
मुख्य बातें:
🌟 इस मॉडल में 2 बिलियन पैरामीटर हैं, और मेमोरी उपयोग केवल 0.4GB है, जो समान उत्पादों से काफी कम है।
🔧 एक अभिनव आर्किटेक्चर का उपयोग करता है, पारंपरिक 16-बिट संख्याओं को छोड़कर, 1.58-बिट कम-परिशुद्धता वज़न भंडारण का उपयोग करता है।
🚀 Hugging Face पर जारी किया गया है, और माइक्रोसॉफ्ट मॉडल की कार्यक्षमता और प्रदर्शन को और बेहतर बनाने की योजना बना रहा है।