A empresa chinesa de IA MiniMax anunciou oficialmente a abertura do código-fonte de seu mais recente modelo grande de linguagem (LLM) chamado MiniMax-M1, que atraiu atenção global devido à sua capacidade de inferência em contexto ultralongo e custo eficiente de treinamento. A AIbase reuniu as informações mais recentes para oferecer uma interpretação abrangente sobre o MiniMax-M1.
Janela de contexto recorde: 1 milhão de tokens de entrada, 80 mil de saída
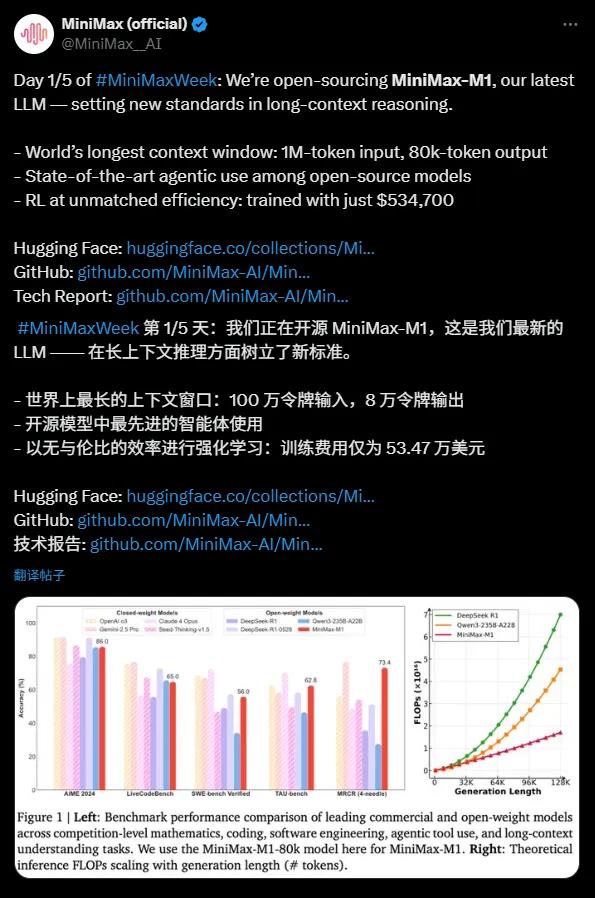
O MiniMax-M1 se destaca por sua impressionante janela de contexto com até 1 milhão de tokens de entrada e 80 mil tokens de saída, tornando-se o modelo de código aberto atual mais especializado em inferência em contexto longo. Essa capacidade significa que o modelo pode processar simultaneamente uma quantidade equivalente ao de um romance inteiro ou até uma série de livros, muito além da janela de contexto de 128.000 tokens do OpenAI GPT-4. Seja para análise de documentos complexos, geração de códigos longos ou conversas multirrounds, o MiniMax-M1 se sai com destreza, fornecendo ferramentas poderosas tanto para empresas quanto para desenvolvedores.
Pioneira em capacidades de agente entre modelos de código aberto
O MiniMax-M1 demonstra um desempenho excepcional ao utilizar ferramentas de agente, rivalizando modelos comerciais de elite como o OpenAI o3 e o Claude4Opus. Graças à combinação de sua arquitetura de modelo misto de especialistas (MoE) com o mecanismo de atenção Lightning, o MiniMax-M1 apresenta um desempenho próximo ao estado da arte em tarefas complexas como engenharia de software, chamada de ferramentas e inferência em contexto longo. Essa robusta capacidade de agente no modelo de código aberto traz oportunidades sem precedentes para a comunidade global de desenvolvedores.

Alto valor por desempenho: 534.700 dólares para criar um LLM de vanguarda
O custo de treinamento do MiniMax-M1 é impressionante, exigindo apenas 534.700 dólares, comparado aos 5 a 6 milhões de dólares do DeepSeek R1 e ao supermilhões de dólares do OpenAI GPT-4, tornando-o uma "maravilha econômica". Graças às tecnologias avançadas de aprendizado por reforço (RL) e ao suporte de hardware de apenas 512 GPUs H800, o MiniMax desenvolveu o modelo em apenas três semanas. Além disso, o algoritmo de otimização CISPO criado pela MiniMax aumentou ainda mais a eficiência da inferência, garantindo que informações importantes não sejam perdidas enquanto reduz custos de treinamento.
Destaques tecnológicos: 456 bilhões de parâmetros e arquitetura eficiente
O MiniMax-M1 foi desenvolvido com base no MiniMax-Text-01 e possui 456 bilhões de parâmetros totais, com cada token ativando cerca de 45,9 milhões de parâmetros, alcançando eficiência computacional por meio da arquitetura MoE. O modelo suporta dois modos de inferência com orçamentos mentais de 40k e 80k, atendendo diferentes necessidades de cenários. Em testes de benchmarking para tarefas intensivas de inferência, como matemática e codificação, o MiniMax-M1 demonstrou desempenho superior aos modelos DeepSeek R1 e Qwen3-235B-A22B.
Marcador histórico para ecossistema de código aberto
O MiniMax-M1 está licenciado sob a licença Apache2.0 e já está disponível na plataforma Hugging Face, onde os desenvolvedores globais podem usá-lo gratuitamente. Essa iniciativa não apenas desafia modelos de código aberto de empresas chinesas como a DeepSeek, mas também injeta nova energia no ecossistema global de IA. A MiniMax afirmou que divulgará mais detalhes técnicos no futuro, promovendo ainda mais a inovação na comunidade de código aberto.
O lançamento do MiniMax-M1 marca um grande avanço nos modelos de código aberto em termos de inferência em contexto longo e capacidades de agente. Sua janela de contexto ultralonga, custo eficiente de treinamento e alto desempenho oferecem soluções de alta qualidade e custo-benefício para empresas e desenvolvedores. A AIbase acredita que o código aberto do MiniMax-M1 acelerará a aplicação de tecnologia de IA em tarefas complexas, impulsionando o ecossistema global de IA a novos patamares.