埃隆·马斯克作为全球首富和资深游戏爱好者,近日在社交媒体上表达了对游戏行业现状的不满,并宣布其旗下公司xAI将成立一个新的AI游戏工作室,旨在复兴游戏行业。

马斯克批评当前许多游戏工作室被大公司收购,导致游戏内容受到商业和政治因素的影响,呼吁开发商专注于游戏本身的质量和乐趣,跳过觉醒说教。
马斯克的行动和言论表明,他希望通过技术创新和AI技术的应用,推动游戏行业回归其本质,提供更高质量的游戏体验。
埃隆·马斯克作为全球首富和资深游戏爱好者,近日在社交媒体上表达了对游戏行业现状的不满,并宣布其旗下公司xAI将成立一个新的AI游戏工作室,旨在复兴游戏行业。
马斯克批评当前许多游戏工作室被大公司收购,导致游戏内容受到商业和政治因素的影响,呼吁开发商专注于游戏本身的质量和乐趣,跳过觉醒说教。
马斯克的行动和言论表明,他希望通过技术创新和AI技术的应用,推动游戏行业回归其本质,提供更高质量的游戏体验。
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。

OceanBase于11月17日上线AI域名oceanbase.ai,页面仅显示“AI…全新的可能,11.18见”,预示其从“Data x AI”战略转向产品落地。此举强化品牌AI定位,暗示18日年度发布会可能推出AI原生核心产品,标志着技术布局的关键进展。

马斯克宣布xAI下一代模型Grok 5推迟至2026年Q1发布,参数量达6万亿,原生支持视频理解,号称“每GB智能密度”创纪录。采用多模态MoE架构,可解析长视频并回答时序问题,目标领跑通用AI竞赛。训练使用X平台实时数据,正扩建GPU集群。同时披露特斯拉Optimus人形机器人进展。

谷歌DeepMind AI在飓风季展现强大预测能力,成功预报五级飓风"梅丽莎"的快速增强。当风暴在海地南部活动时,美国国家飓风中心预报员首次明确预测其24小时内将发展为四级飓风并直扑牙买加,创下该机构历史纪录。

阿里巴巴推出千问APP公测版,基于Qwen3模型,与ChatGPT展开全面竞争。该应用已在各大商店上线,并计划推出国际版,旨在为用户提供AI服务,助力开发者洞悉技术趋势。
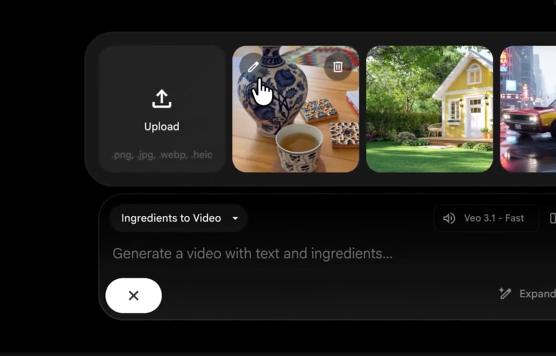
谷歌AI电影工具Flow新增图像编辑功能,集成Gemini2.5Flash模型,支持自然语言指令实现去背景、主体分离和场景替换,可生成8秒动态镜头。面向免费及以上用户开放,单张处理0.039美元,企业版同步上线Vertex AI。用户上传图片后输入提示词,即可获得PNG透明图或合成效果图。

国际能源署报告显示,2023年全球数据中心投资达5800亿美元,首次超过石油勘探支出(5400亿美元)。这凸显经济结构转变,尤其在生成式AI可能加剧气候变化的背景下,数据中心与石油产业对比引人关注。

苹果更新App审核指南,要求开发者在向第三方AI分享用户数据前,必须明确告知用户并征得同意。新规强调数据处理的透明度,确保用户知情权得到保障。

谷歌Gemini3通过Canvas功能提前展示多模态能力,可将《我的世界》与塔防游戏结合成网页,复刻Switch模拟器运行宝可梦,被誉“最强前端AI”。其他案例包括生成新粗野主义网页、黑洞可视化、交互风扇和YouTube克隆,均以单HTML文件实现,引爆开发者社群。

JetBrains推出业内首个开放式多语言基准测试平台DPAI Arena,旨在评估AI辅助工具在软件开发中的实际效果,解决行业挑战。该平台支持多框架和工作流,未来将由Linux Foundation管理,专注于衡量AI编码智能体在真实环境中的表现。
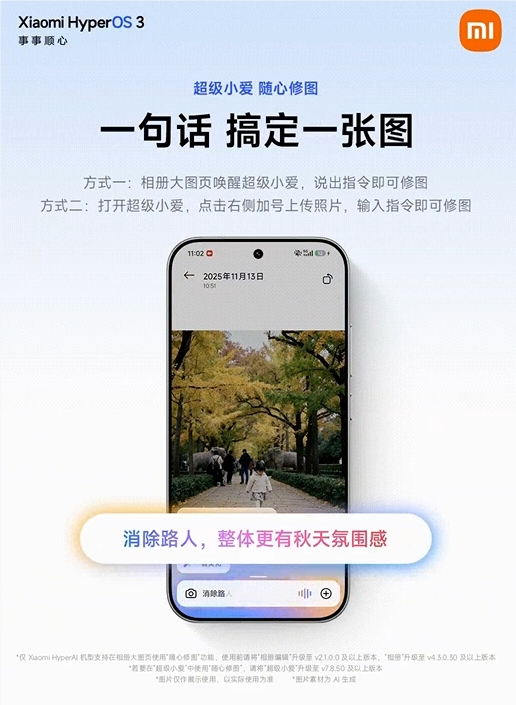
小米更新超级小爱至v7.8.50版,新增“随心修图”功能。用户可通过自然语言指令,利用AI模型自动修图,支持多模态交互识别屏幕和摄像头画面。操作方式包括在相册唤醒小爱或通过App上传照片并输入文字,系统自动完成色彩增强、背景虚化等处理。