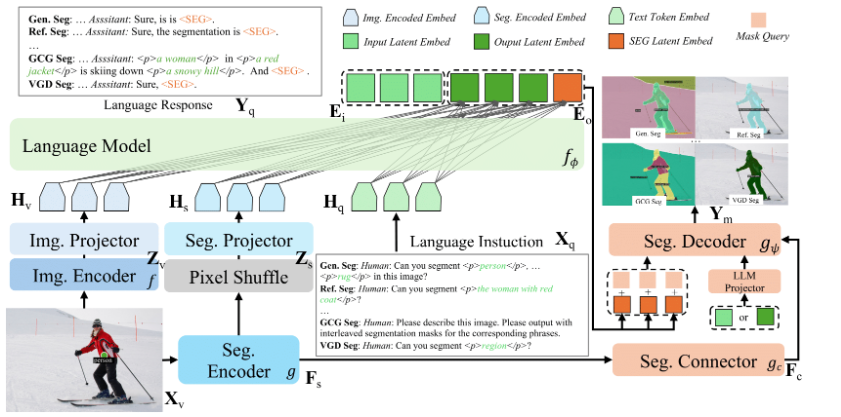
Hi Lab de Xiaohongshu ha lanzado recientemente y ha abierto al público su primer modelo multimmódulo desarrollado internamente, dots.vlm1. Este modelo se basa en el codificador visual NaViT de 1.2 mil millones de parámetros y el modelo de lenguaje grande DeepSeek V3, y ha sido entrenado completamente desde cero. Su desempeño sobresaliente en comprensión y razonamiento visual multimmódulo ya se acerca al de los modelos cerrados líderes actuales, como Gemini2.5Pro y Seed-VL1.5, lo que marca un nuevo hito en el desempeño de los modelos multimmódulos de código abierto.
")
Innovación propia, desempeño líder
El punto destacado principal de dots.vlm1 es su codificador visual NaViT desarrollado internamente. A diferencia del método tradicional de ajuste fino con modelos maduros, NaViT se entrena desde cero y admite resoluciones dinámicas, lo que le permite adaptarse mejor a escenarios reales diversos de imágenes. Este modelo también mejora significativamente su capacidad de generalización mediante la combinación de la supervisión puramente visual y la supervisión visual textual, demostrando un excelente desempeño especialmente en imágenes estructuradas no típicas, como tablas, gráficos, fórmulas y documentos.
En cuanto a los datos, el equipo de Hi Lab ha construido un conjunto de entrenamiento de gran tamaño y limpio. Al reescribir datos de páginas web por su cuenta y utilizar la herramienta dots.ocr desarrollada internamente para procesar documentos PDF, han mejorado significativamente la calidad de alineación entre texto e imagen, sentando una base sólida para la capacidad de comprensión cruzada de modos del modelo.
Desempeño en evaluaciones, comparable a los modelos cerrados de élite
En conjuntos de evaluación multimmódulo internacionales principales, el desempeño integral de dots.vlm1 es notable. En varios benchmarks, como MMMU, MathVision y OCR Reasoning, alcanza un nivel comparable con Gemini2.5Pro y Seed-VL1.5. En aplicaciones como razonamiento en gráficos complejos, razonamiento matemático STEM y reconocimiento de escenas específicas de cola larga, dots.vlm1 demuestra una excelente capacidad de razonamiento lógico y análisis, siendo totalmente capaz de tareas de alto nivel como las de olimpiadas matemáticas.

Aunque aún existe cierta brecha con los modelos cerrados de estado del arte en tareas extremadamente complejas de razonamiento de texto, su capacidad de razonamiento matemático general y programación ya es comparable a la de los grandes modelos de lenguaje principales.
El equipo de Hi Lab declaró que seguirán optimizando el modelo. Planean ampliar la escala de datos cruzados multimodales y introducir algoritmos avanzados como el aprendizaje por refuerzo, para mejorar aún más la capacidad de generalización del razonamiento. A través de la apertura de dots.vlm1