8月11日、智譜科技は最新の視覚理解モデル「GLM-4.5V」を正式にリリースしました。このモデルは、新世代のテキストモデル「GLM-4.5-Air」に基づいてトレーニングされ、前世代の視覚推論モデル「GLM-4.1V-Thinking」の技術路線を引き継いでおり、驚異的な1060億パラメータと120億アクティベーションパラメータを備えています。また、「思考モード」のスイッチ機能が新たに追加され、ユーザーはこのモードを有効または無効にすることができ、タスク処理時により柔軟に対応できます。
このモデルの視覚能力は注目を集めています。マクドナルドとケンタッキーのフライドチキンを簡単に区別でき、外観の色合いや質感など多角的な角度から詳細な分析が可能です。さらに、GLM-4.5Vは画像を使って場所を当てるチャレンジに参加し、大会で優れた成績を収め、99%の参加者を上回り、66位にランクインしました。智譜はこのモデルが42のベンチマークテストで優れた結果を示していることも紹介しており、ほとんどのテストでは同等規模の他のモデルを上回る得点を記録しています。
現在、GLM-4.5VはHugging Face、魔搭、GitHubなどのオープンソースプラットフォームで公開されており、ユーザーは無料でダウンロード・利用可能であり、FP8量化バージョンも提供されています。このモデルをより良く体験するために、智譜はデスクトップアシスタントアプリケーションをリリースしており、リアルタイムでのスクリーンショットや録画をサポートし、コード補助や文書解釈などのさまざまな視覚的推論タスクを支援します。
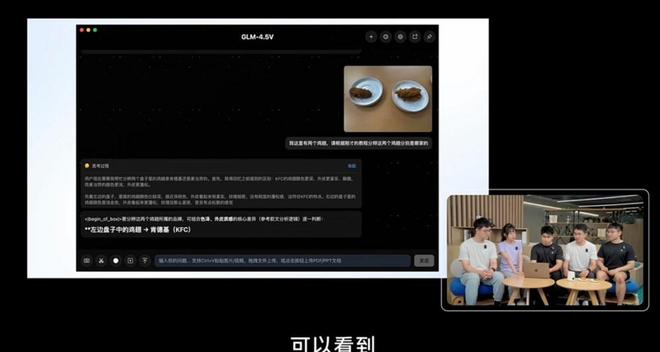
実際のテストでは、GLM-4.5Vはアップロードされた画像に基づいて位置を推測することができ、まれに小さな誤差が生じる場合もありますが、推論プロセスは非常に豊かです。ウェブコンテンツの処理においては、スクリーンショットを生成して類似度の高いページを作成でき、強力な再現能力を示しています。

GLM-4.5Vは視覚的理解分野だけでなく、エージェントアプリケーションの場面でも大きな可能性を示しています。この技術がさらに発展していくにつれて、私たちには今後、生活に多くの利便性をもたらすことを期待できるでしょう。







