バイトダンスは最近、LatentSyncという革新的な技術をオープンソース化しました。これは、オーディオ条件に基づく潜在的拡散モデルを用いた、エンドツーエンドのリップシンクフレームワークです。この技術は、中間的な動き表現を一切必要とせず、ビデオ内の人物の唇の動きとオーディオを正確に同期させることができます。従来のピクセル空間拡散や二段階生成によるリップシンク方法とは異なり、LatentSyncはStable Diffusionの強力な機能を直接活用することで、複雑な視聴覚関係をより効果的にモデル化できます。

研究によると、拡散ベースのリップシンク方法は、異なるフレーム間の拡散プロセスに不一致があるため、時間的一貫性に劣ることが分かっています。この問題を解決するために、LatentSyncは時間表現アライメント(TREPA)技術を導入しました。TREPAは大規模な自己教師ありビデオモデルから抽出した時間表現を利用して、生成されたフレームと実際のフレームをアライメントすることで、時間的一貫性を高めながら、リップシンクの精度を維持します。
さらに、研究チームはSyncNetの収束問題を深く研究し、広範な実証研究を通じて、モデルアーキテクチャ、トレーニングハイパーパラメータ、データ前処理方法など、SyncNetの収束に影響を与える重要な要素を特定しました。これらの要素を最適化することで、SyncNetのHDTFテストセットにおける精度は91%から94%へと大幅に向上しました。SyncNetの全体的なトレーニングフレームワークに変更を加えていないため、この経験は、SyncNetを利用する他のリップシンクやオーディオ駆動の人物アニメーション方法にも適用できます。
LatentSyncの利点
エンドツーエンドフレームワーク:中間的な動き表現を必要とせず、オーディオから直接同期した唇の動きを生成します。
高品質な生成:Stable Diffusionの強力な能力を利用して、ダイナミックでリアルな会話ビデオを生成します。
時間的一貫性:TREPA技術により、ビデオフレーム間の時間的一貫性を高めます。
SyncNetの最適化:SyncNetの収束問題を解決し、リップシンクの精度を大幅に向上させました。
動作原理
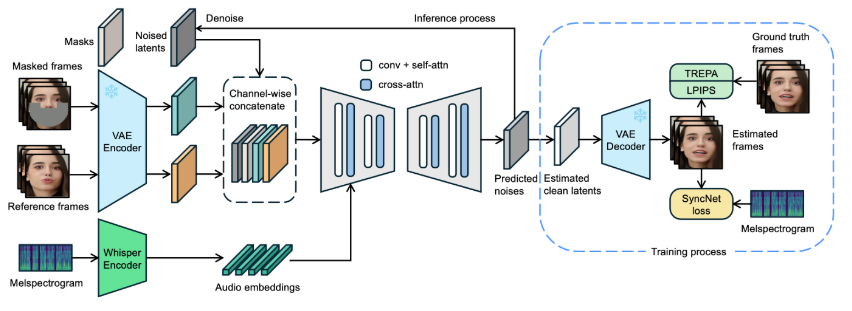
LatentSyncの中核は、画像から画像への修復技術に基づいており、マスク付きの画像を入力として参照する必要があります。元のビデオの人間の顔の視覚的特徴を統合するために、モデルは参照画像も入力します。これらの入力情報はチャネル連結された後、U-Netネットワークに入力され処理されます。
モデルは、事前学習済みのオーディオ特徴抽出器Whisperを使用してオーディオ埋め込みを抽出します。唇の動きは周囲のフレームのオーディオの影響を受ける可能性があるため、モデルは複数の周囲フレームのオーディオをまとめて入力し、より多くの時間情報を提供します。オーディオ埋め込みは、クロスアテンション層を通じてU-Netに統合されます。
SyncNetが画像空間入力を必要とする問題を解決するために、モデルはまずノイズ空間で予測を行い、次にシングルステップ法で推定されたクリーンな潜在空間を取得します。ピクセル空間でSyncNetを訓練する方が潜在空間で訓練するよりも効果的であることが判明しました。これは、VAEエンコーディングプロセスで唇領域の情報が失われる可能性があるためです。
トレーニングプロセスは2段階に分かれています。第1段階では、U-Netが視覚的特徴を学習し、ピクセル空間のデコードとSyncNet損失の追加は行いません。第2段階では、デコードされたピクセル空間の教師あり学習方法でSyncNet損失を追加し、LPIPS損失を使用して画像の視覚的品質を向上させます。モデルが時間情報を正しく学習できるように、入力ノイズにも時間的一貫性を持たせる必要があり、モデルは混合ノイズモデルを採用しています。さらに、データ前処理段階では、アフィン変換を使用して顔の正面化も行っています。
TREPA技術
TREPAは、生成された画像シーケンスと実際の画像シーケンスの時間表現をアライメントすることで、時間的一貫性を向上させます。この方法は、大規模な自己教師ありビデオモデルVideoMAE-v2を使用して時間表現を抽出します。画像間の距離損失のみを使用する方法とは異なり、時間表現は画像シーケンスの時間的関連性を捉えることができ、全体的な時間的一貫性を向上させます。研究によると、TREPAはリップシンクの精度を損なうどころか、向上させる可能性があることが分かりました。
SyncNetの収束問題
研究によると、SyncNetのトレーニング損失は0.69付近で停滞しやすく、それ以上減少することがありませんでした。広範な実験分析を通じて、研究チームは、バッチサイズ、入力フレーム数、データ前処理方法がSyncNetの収束に大きな影響を与えることを発見しました。モデルアーキテクチャも収束に影響を与えますが、その影響は比較的小さいです。
実験結果によると、LatentSyncは複数の指標において、他の最先端のリップシンク方法よりも優れています。特にリップシンクの精度においては、最適化されたSyncNetとオーディオクロスアテンション層のおかげで、オーディオと唇の動き間の関係をより適切に捉えることができます。さらに、TREPA技術を採用したことで、LatentSyncの時間的一貫性も大幅に向上しました。
プロジェクトアドレス:https://github.com/bytedance/LatentSync