先日、DeepSeekと清華大学の研究者らが新たな論文を発表し、報酬モデルの推論時のスケーリング手法について論じ、DeepSeek R2をさらに進化させました。現在、強化学習は大規模言語モデルの後期トレーニング段階で広く用いられていますが、大規模言語モデルに対して正確な報酬信号を得ることが課題となっています。

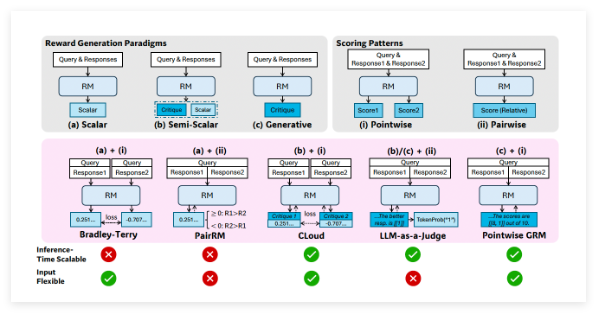
研究者らは、点式生成報酬モデル(GRM)を用いることで、モデルの適応能力と推論段階における拡張性を向上できることを発見しました。そのため、自己原則評価調整(SPCT)学習手法を提案し、これによりDeepSeek-GRMモデル(例えば、Gemma-2-27Bを基にトレーニングされたDeepSeek-GRM-27Bなど)が得られました。実験の結果、SPCTはGRMの質と拡張性を大幅に向上させ、複数のベンチマークテストにおいて既存の手法やモデルを上回る性能を示しました。さらに、研究者らはメタ報酬モデル(meta RM)を導入して投票プロセスを導き、拡張性能を向上させています。

SPCT手法は2段階に分かれています。第1段階は、拒否式ファインチューニングによるコールドスタート段階で、GRMが様々な入力タイプに適応し、正しい形式で原則と評価内容を生成できるようにします。研究者らは点式GRMを採用し、プロンプト式サンプリングを導入することで、予測報酬と真の報酬の一致性を向上させています。第2段階は、ルールベースのオンライン強化学習段階で、ルールベースの結果報酬を用いて、GRMがより良い原則と評価内容を生成するように促し、推論段階における拡張性を向上させています。
DeepSeek-GRMの性能を向上させるため、研究チームは推論時の拡張戦略を検討しました。生成された報酬による投票を行い、報酬空間を広げ、最終的な報酬の質を向上させています。同時に、メタ報酬モデルをトレーニングして投票を導き、低品質なサンプルを除外しています。実験結果によると、DeepSeek-GRM-27Bは全体的な性能が優れており、推論時の拡張によってさらに性能が向上することが示されました。アブレーションスタディでは、オンライントレーニングがGRMにとって重要であり、原則生成もモデルの性能に非常に重要であることが示されました。さらに、本研究ではDeepSeek-GRM-27Bの推論時の拡張の有効性が証明され、単にモデル規模を拡大するよりも優れていることが示されました。
要点:
💡DeepSeekと清華大学の研究者らは、自己原則評価調整(SPCT)手法とメタ報酬モデル(meta RM)を提案し、報酬モデルの推論時の拡張性を向上させ、DeepSeek-GRMシリーズモデルを構築しました。
🧪SPCTは、拒否式ファインチューニングとルールベースのオンライン強化学習の2段階からなり、GRMの質と拡張性を向上させ、DeepSeek-GRM-27Bはベンチマークテストで優れた性能を示しました。
📈研究チームは推論時の拡張戦略を検討し、生成報酬による投票とメタ報酬モデルによる投票ガイドによって性能を向上させ、DeepSeek-GRM-27Bの推論時の拡張の有効性が、モデル規模の拡大よりも優れていることを証明しました。
論文アドレス:
https://arxiv.org/abs/2504.02495