AdobeがAI Foundryサービスを開始。企業は自社ブランドと知的財産で生成AIモデルをカスタマイズ可能。Fireflyベースでテキスト、画像、動画、3Dコンテンツを生成。....
AdobeがAI Foundryを発表。Fireflyモデルを基に、企業が自社ブランド資産でテキスト・画像・動画・3Dコンテンツを生成するAIを開発可能。法的保証が強みで需要高い。....
マイクロソフトがAzure AIプラットフォームでOpenAIの動画生成モデルSora2をパブリックプレビュー公開。クラウドAPI経由で企業・開発者向けに提供され、テキスト・画像・動画を入力に新規動画を生成可能。広告など商業利用の開始で生成AI動画ツールが本格商用化へ。....
バイドゥ検索は10月15日に文心アシスタントをアップグレードし、AIGCのマルチモーダルなクリエイティブとスマートタスク解決能力を顕著に強化しました。現在、テキスト、画像、ビデオ、音楽、パッドキャストなど8種類のコンテンツを生成できるようになりました。ユーザーは毎日1000万を超えるAIGCコンテンツを生成しており、AIクリエイティブの新しい段階に入ったことを示しています。
Nano BananaはGoogleモデルによって駆動されるAI画像生成編集プラットフォームで、テキストプロンプトで操作します。
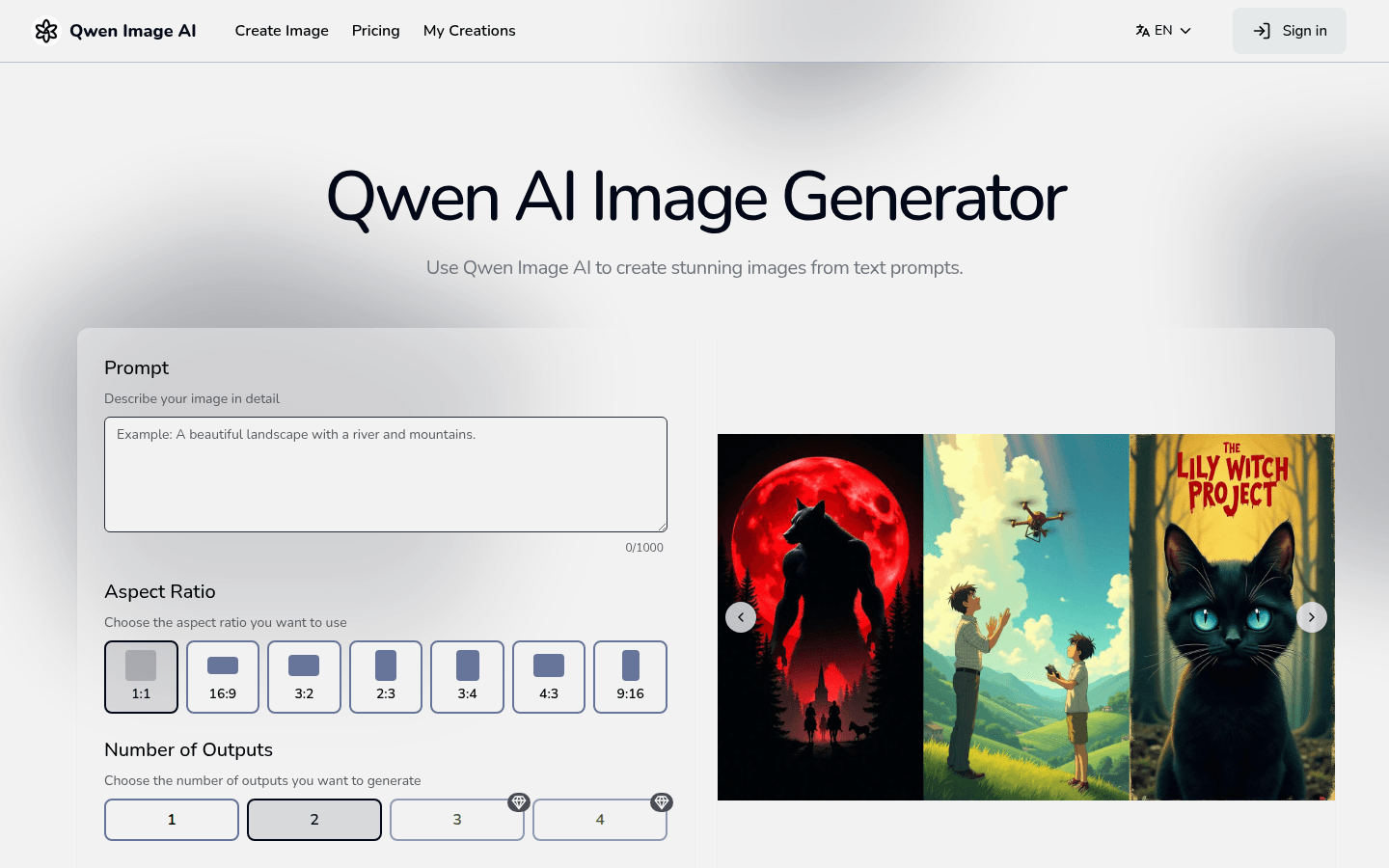
Qwen Image AIはアリババグループのQwenチームが開発したオープンソースの画像生成および編集ベースモデルで、正確な画像テキストレンダリングと高度な編集が可能です。
出力品質が優れた効率的なテキストから画像を生成するモデルです。
Flux Krea AI - FLUX.1 Devモデルを利用して高次のテキストから画像生成を行います。
meta
$1.22
入力トークン/百万
$4.32
出力トークン/百万
1M
コンテキスト長
openai
$18
$72
128k
tencent
32k
google
$0.72
$2.88
$0.58
$2.16
10M
baidu
$3
$15
-
$1.08
$216
$432
8.2k
$2.52
azure
$0.36
$0.43
bytedance
$1.5
$4.5
alibaba
131.1k
spooknik
PixelWaveはFlux.1をベースに開発されたテキストから画像生成モデルで、Nunchaku量子化(SVDQ)による最適化を施し、さまざまなGPU構成のユーザーに効率的な画像生成ソリューションを提供します。
mlx-community
これはQwen3-VL-4B-InstructモデルのMLX形式の8ビット量子化バージョンで、mlx-communityによって変換されました。このモデルは40億パラメータのマルチモーダル視覚言語モデルで、画像理解とテキスト生成タスクをサポートし、命令追従シナリオ向けに最適化されています。
neuralvfx
LibreFLUX-ControlNetは、ControlNetアーキテクチャに基づくテキストから画像への生成モデルで、LibreFLUXを基礎となるTransformerモデルとして使用しています。このモデルはSA1Bデータセットで訓練されており、テキストプロンプトと制御画像に基づいて高品質な画像コンテンツを生成することができます。
CenKreChro-SVDQは、ChromaとFlux Kreaを統合したテキストから画像生成モデルの量子化バージョンで、SVDQuant技術を用いて最適化され、INT4とFP4の2種類の量子化形式を提供し、それぞれ異なる世代のGPUハードウェアに適しています。
これはQwen3-VL-30B-A3B-Instructモデルの4ビット量子化MLX形式のバージョンで、mlx-communityによって変換および維持されています。このモデルは300億パラメータのマルチモーダル視覚言語モデルで、画像理解とテキスト生成タスクをサポートします。
John6666
テキストから画像生成に特化したアニメスタイルのモデルで、可愛い女の子形象の2Dイラスト、人物肖像、キャラクター設定を生成できます。画像は動的なポーズ、明確な構造、強い照明などの特徴があります。
lichorosario
これはQwen-Imageモデルをベースに訓練されたLoRA(Low-Rank Adaptation)モデルで、テキストから画像への生成タスクに特化しています。このプロジェクトはAI Toolkitを使用して訓練され、テキスト記述を高品質な画像に変換でき、様々な画像生成ツールでの使用をサポートしています。
XL-Sat-IORはStable DiffusionとStable Diffusion XLアーキテクチャに基づくテキストから画像への生成モデルで、高度なリアリティ、豊かな色彩、映画的な質感、精細な細部、優れた光と影、生き生きとした表情を持つ画像を生成することができます。
bghira
これはPixArt - 900M - 1024モデルに基づくLyCORISアダプターで、テキストから画像への変換タスクに特化しています。このモデルは入力されたテキスト記述に基づいて対応する画像を生成でき、複数の解像度の画像生成をサポートします。
loyal-misc
svizzはLoRA技術に基づくテキストから画像への生成モデルで、LyliaEngine/Pony_Diffusion_V6_XLをベースモデルとして、特定のトリガーワードを通じて高品質な画像コンテンツを生成することができます。
MadhavRupala
Stable Diffusion v1-5は潜在拡散技術に基づくテキストから画像生成モデルで、テキスト記述に基づいてリアルな画像を生成できます。このモデルはLAION - 2Bデータセットで訓練され、英語テキスト入力をサポートし、512x512解像度の画像を生成します。
zambawi
joywan - loraは、OstrisによるAIツールキットを基にトレーニングされたLoRAモデルで、テキストから動画および画像生成タスクに特化しており、基礎モデルのWan - AI/Wan2.1 - T2V - 14B - Diffusersと併用する必要があります。
mrgant
lans_v1 - loraは、Qwen/Qwen-Imageモデルをベースに、OstrisによるAIツールキットを使用して訓練されたテキストから画像への変換モデルです。LoRA技術を用いて最適化されており、良好な画像生成能力を備えています。
spamnco
これはWan2.1-T2V-14Bモデルをベースに訓練されたLoRAアダプターで、テキストからビデオへの変換タスクに特化しており、画像生成に強化機能を提供します。このモデルはAI Toolkitを使用して訓練され、画像生成をアクティブにするには特定のトリガーワード「diddly」が必要です。
これはStable DiffusionとStable Diffusion XL技術に基づくテキストから画像への生成モデルで、人物の肖像、テクスチャ、肌の表現を特別に最適化し、リアルで自然な画像を生成できます。
これはStable Diffusion XLに基づくテキストから画像への生成モデルで、アジアスタイルの画像生成に特化して最適化されており、リアル感と美感を持つ画像作品を生成することができます。
BarleyFarmer
natalie_wan_2.2-loraは、OstrisによるAIツールキットを基にトレーニングされたLoRAモデルで、テキストからビデオへの変換タスクに特化しており、画像生成の品質と効果を効果的に向上させることができます。
MartinSSSTSGH
これはOstrisによるAIツールキットを基にトレーニングされたLoRAモデルで、テキストから動画への画像生成タスクに特化しており、トリガーワード「Lilly」を使用して特定のスタイルの画像コンテンツを生成します。
Mark111111111
これはOstrisによるAIツールキットを基にトレーニングされたLoRAモデルで、テキストからビデオへの変換に特化しており、画像生成に新しい体験をもたらします。このモデルは基礎モデルWan2.2-T2V-A14Bと一緒に使用する必要があります。
Ashmotv
animat3d_style_wan-loraは、OstrisによるAIツールキットを基にトレーニングされたLoRAモデルで、テキストからビデオへの生成に特化しており、画像生成に独特な3Dアニメーションスタイルの効果をもたらします。このモデルはWan2.2 - T2V - A14Bベースモデルを基に微調整されており、複数の主流のAIプラットフォームで使用できます。
ミニマックス公式のモデルコンテキストプロトコル(MCP)サーバーで、テキスト読み上げ、ビデオ/画像生成などのAPIとのやり取りをサポートします。
Flux Image MCPサーバーはFlux Schnellモデルに基づく画像生成サービスで、Replicateプラットフォームを通じてAPIインターフェースを提供し、テキスト記述による画像生成をサポートします。
MCPプロトコルに基づく画像生成サーバーで、Replicateのflux-schnellモデルを使用し、テキストプロンプトによる画像生成をサポートし、さまざまなパラメータを設定できます。
AIビデオ生成MCPサーバーは、テキストと画像入力をサポートして動画ビデオを生成し、様々なパラメーター制御とモデル選択を提供します。
Google Geminiモデルに基づくMCPサーバーで、テキストからの画像生成と画像変換機能を提供し、高品質な画像生成、スマートなファイル名生成、ローカル保存をサポートします。
TypeScriptベースのMCPサーバーで、Flux Schnellモデルを統合してテキストから画像への生成機能を実現します。
Go言語に基づくMCPサーバーで、OpenAIのDALL - E APIを通じてテキスト説明に基づく画像生成機能を実現し、Claudeなどの大型言語モデルと統合して使用できます。
OpenSCAD MCPサーバーは、テキストまたは画像からパラメトリック3Dモデルを生成するツールで、多視点再構築とリモート処理をサポートします。
MiniMax MCP JSは、JavaScript/TypeScriptで実装されたMiniMaxモデルコンテキストプロトコルツールキットで、テキスト読み上げ、画像生成、動画生成、声のクローンなどの機能を提供し、複数の設定方法と転送モードをサポートします。
MCP Flux Studioは、強力なモデルコンテキストプロトコルサーバーです。Fluxの高度な画像生成機能をAIプログラミングアシスタントに統合し、CursorとWindsurf IDEをサポートします。
TypeScriptベースのMCPサーバーで、OpenAIのDALL - E 3モデルを使ってテキストプロンプトに基づいて画像を生成します。
Image Gen MCP Serverは、Model Context Protocol(MCP)標準プロトコルを通じて、さまざまなLLMチャットボットにクロスプラットフォーム、多モデルの画像生成機能を提供する汎用AI画像生成サービスです。OpenAIとGoogleの複数の画像モデルをサポートし、テキスト対話からビジュアルコンテンツへのシームレスな変換を実現します。
TRELLIS Blenderプラグインは、高度なテキスト/画像から3Dモデルを生成する機能をBlenderに統合します。テキストまたは画像を通じてテクスチャ付きの3Dメッシュを生成し、詳細調整機能も提供します。プラグインはMCPサービスも統合しており、Cursor/Windsurfなどのツールと通信できます。
fal.ai APIとMCPプロトコルを通じてテキストから画像を生成するNode.jsツールで、複数のモデルとパラメータをサポートし、開発者やクリエイターが迅速に画像を生成するのに適しています。
このプロジェクトは、Google Veo2モデルに基づくビデオ生成MCPサーバーで、テキストプロンプトまたは画像を通じてビデオを生成することができ、MCPリソースへのアクセス機能も提供します。
モーダルMCPツールボックスは、Modalプラットフォーム上で動作するツールの集合で、モデルコンテキストプロトコル(MCP)に基づいており、LLMにPythonサンドボックスコード実行やFLUXモデルによる画像生成などの拡張機能を提供します。
Image Generation MCP ServerはClaude Desktopに画像生成機能を提供するMCPサーバーで、Replicate Fluxモデルを使用し、テキストプロンプトを通じて画像生成をサポートし、Smitheryまたはnpmを通じてインストールおよび構成できます。
Outsource MCPは、複数のAIモデルプロバイダーをサポートする統一インターフェースサービスです。MCPプロトコルを通じて、AIアプリケーションが異なるベンダーのテキストおよび画像生成機能を簡単に呼び出せるようにします。
このプロジェクトは、OpenAIのgpt-image-1モデルを通じて画像生成と編集機能を提供するMCPサーバーを実装しています。テキスト説明に基づく画像生成、参照画像に基づく画像の編集または修復が可能で、結果をローカルに保存することができます。
詳細な架空世界を構築するためのモデルコンテキストプロトコルで、自動画像生成をサポートします。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)





![FLUX.1 Krea [dev]](https://pic.chinaz.com/ai/2025/08/01/25080110475283667344.jpg)





























