グーグルは開発者に対し、新版のディープリサーチゲートウェイを公開しました。このゲートウェイはアプリに統合できます。このゲートウェイは反復的なリサーチ手法を使用しており、独自に検索・分析を行い、常に最適化された回答を提供します。性能は前バージョンのモデルよりも優れています。
シカゴ・トレーブル紙は、AI企業であるPerplexityを提訴し、そのニュースコンテンツの無許可収集やペイウォールの回避、そして原文レベルの結果の直接生成を控訴している。紙の弁護士はコンテンツの使用状況について質問したが、Perplexityは記事をモデル学習に使用しておらず、非逐字的な事実引用が含まれている可能性はあると回答した。
OpenAIは「懺悔」というトレーニングフレームワークを発表しました。この仕組みはAIモデルの誠実さを高めることを目的としています。このメカニズムでは、モデルが主な答えを提供した後、自身の間違いや不適切な行動を積極的に認めることが求められ、従来のトレーニングで起こりうる真実を隠すまたは正確でない回答を提供する問題を修正します。
OpenAIは「懺悔」フレームワークを導入し、AIモデルが不適切な行動や問題のある判断を自ら認めるよう訓練。これにより、大規模言語モデルが「期待に応えよう」として誤った発言をする問題を解決。モデルは主要回答後に推論プロセスを詳細に説明する二次応答を行う。....
主流AIモデルを統合し、自動的に最適なモデルを選択し、複数のモデルを連携させて、正確な回答を得ることができます。
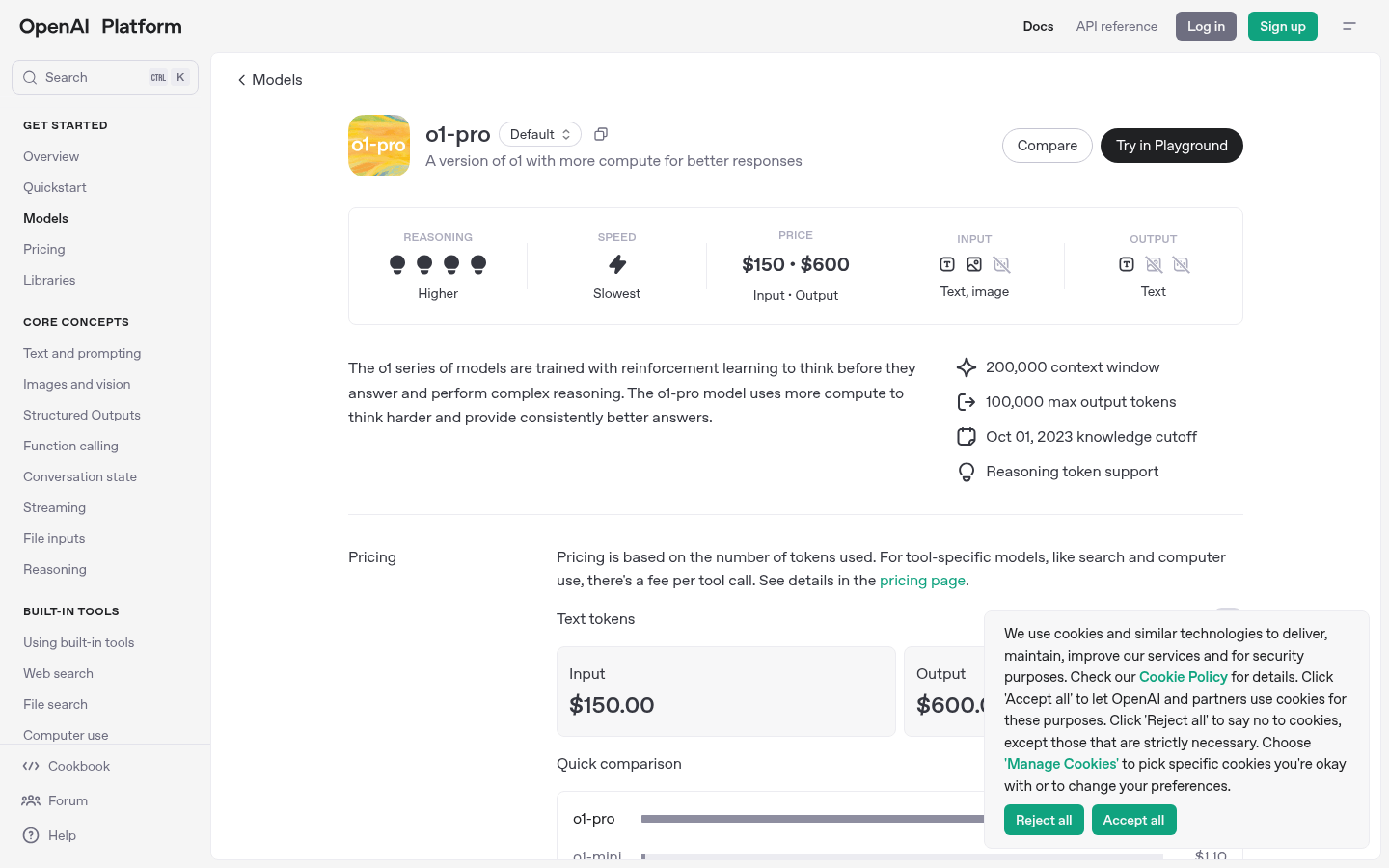
o1-proモデルは強化学習により複雑な推論能力を向上させ、より最適な回答を提供します。
言語モデルの事実に関する質問への回答能力を評価するベンチマークテスト
NVIDIAがカスタマイズした大規模言語モデルで、問い合わせへの回答の有用性を向上させます。
Google
$0.49
入力トークン/百万
$2.1
出力トークン/百万
1k
コンテキスト長
Openai
$2.8
$11.2
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$1
$10
256
$6
$24
Baidu
128
$4
$16
$2
$20
MedSwin
このプロジェクトは、mergekitを使用して事前学習言語モデルを統合した成果であり、複数の医学分野の事前学習モデルを組み合わせ、医学質問応答タスクにより強力なサポートを提供し、医学的質問への回答の正確性と効率を効果的に向上させます。
Clemylia
Lam-3はLaminaシリーズの小型言語モデル(SLM)で、Clemylia/lamina - suite - pretrainをベースに微調整されています。このモデルは質問に回答でき、創造性がありますが、時に回答が独特になることがあります。モデルはゼロから作成され、1358個の質問と回答のペアを含むClem27sey/Nacidデータセットで3時間学習されました。
Lam-2は、カスタムアーキテクチャAricate V4に基づいて開発された第二代の小型言語モデル(SLM)で、質問と回答のタスクで優れた性能を発揮し、卓越した言語の連貫性と創造力を持っています。前代製品と比較して、Lam-2は文法の正確性とテキスト生成の品質が著しく向上しています。
LAM-1はlaminaシリーズの最初の完全版の小型言語モデルで、Clemyliaによって開発されました。このモデルは創造的なコンテンツ生成に特化しており、想像力に富み、詩的で叙事性のある回答を生成するように最適化されており、事実性の情報ではありません。
Tesity-T5はClemyliaによって開発されたエンコーダ-デコーダ型の言語モデルで、コンテキスト付きの質問応答タスクに特化しています。このモデルは提供されたテキストコンテキストに基づいて、正確に情報を抽出し合成して回答を生成することができ、事実性と包括性のある回答能力を持っています。
aisingapore
Qwen-SEA-LION-v4-32B-ITは、Qwen3 - 32Bをベースに構築された東南アジア言語の大規模言語モデルで、東南アジア地域を対象に事前学習と指令微調整が行われています。このモデルは、7種類の東南アジア言語を含むSEA - Pile v2コーパスで継続的に事前学習され、800万対の高品質な質問と回答のデータで指令微調整が行われ、強力な多言語理解と推論能力を備えています。
DragonLLM
LLM Pro Financeは、金融および経済の専門家向けに設計された多言語人工知能モデルです。大量の高品質な金融および経済データを基に訓練されており、複雑な金融問題に対して正確かつ文脈に沿った回答を生成することができます。
DavidAU
これはQwen3-Coder-30B-A3B-Instructをベースとした混合エキスパートモデルで、540億のパラメータと100万のコンテキスト長を持っています。モデルは三段階のマージとBrainstorm 40X最適化により、強力なプログラミング能力と一般的なシーンの処理能力を備え、特に思考モジュールを統合しており、回答前に深い推論を行うことができます。
TIGER-Lab
本プロジェクトはQwen2.5-VL-7B-Instructモデルに基づいており、視覚質問応答タスクに特化しており、画像に関連する質問に正確に回答でき、高い正確性と関連性を備えています。これはマルチモーダル視覚言語モデルであり、画像理解と画像に基づく質問応答インタラクションをサポートします。
Qwen2.5-VL-7B-Instructはアリババの通義千問チームによって開発されたマルチモーダル視覚言語モデルで、70億のパラメータ規模に基づき、視覚的質問応答タスクに特化して最適化トレーニングが行われています。このモデルは画像内容を理解し分析し、正確な自然言語の回答を生成することができます。
ibm-granite
Granite-4.0-H-TinyはIBMが開発した70億パラメータの長文脈指令モデルで、Granite-4.0-H-Tiny-Baseをベースにファインチューニングされています。このモデルはオープンソースの指令データセットと内部合成データセットを組み合わせて訓練され、専門的で正確かつ安全な回答能力を備え、多言語とツール呼び出しをサポートし、企業向けアプリケーションに適しています。
adityak74
MEDFIT-LLM-3Bは、医療質問応答に特化して最適化された言語モデルで、MetaのLlama-3.2-3B-Instructをベースに微調整されています。このモデルは、LoRA技術を用いて医療データセットで訓練され、医学分野の理解と直接的な回答能力が大幅に向上しており、医療チャットボットや患者教育などのアプリケーションシナリオに適しています。
manuelcaccone
Gemma-3 ActuaryEnough2は精算分野に特化したAIモデルで、11,000以上の精算質問と回答のペアを使って微調整学習されており、簡単な保険の質問を厳密な精算専門用語に変換することができます。このモデルはActuaryEnoughをサポートし、オープンソース形式で教育や研究目的で公開されています。
ducklingcodehouse
これは、フィンランド語の歯科医学に特化した対話型AIアシスタントで、LoRAによる微調整を行った大規模言語モデルです。歯科相談の質問に対して、背景、評価、提案の3つの部分に分かれた構造化臨床回答を生成することができます。
vinimuchulski
これはGemma-3-4Bモデルをベースに微調整された天文学の専門モデルで、ポルトガル語の天文学の質問と回答に特化して最適化されており、より正確で文脈に沿った天文学のポルトガル語の回答を提供することができます。
iCIIT
TripleBits-Sinhala-Gemma-2B-QnAはGoogle Gemma 2Bアーキテクチャに基づく僧伽羅語の質問と回答モデルで、PEFT技術を通じて微調整されています。このモデルは多様な僧伽羅語のコーパスで持続的な事前学習を行い、僧伽羅語の質問と回答タスクに特化して最適化されており、僧伽羅語の質問と回答シナリオに正確な回答を提供することができます。
yasserrmd
MedScholar-1.5Bは軽量級で指令に沿った医療質問と回答モデルで、Qwen2.5-1.5B-Instructをベースに構築され、MIRIAD-4.4Mデータセットの100万のサンプルを使って微調整され、臨床知識探索に特化していますが、医療診断には使用できません。
Azzindani
これはインドネシア法律分野に特化して最適化された言語モデルで、DeepSeek - R1 - 0528 - Qwen3 - 8Bをベースに、GRPO方法を使用してインドネシア法律質問と回答データセットで微調整され、法律推論と構造化思考能力の向上に重点を置いています。
ArindamSingh
Gemma-3 1Bモデルを微調整した医学推論専用モデルで、段階的な推論をサポートする医学の質問と回答が可能です。
metehanayhan
Meta LLaMA 3.1 8B大規模言語モデルをベースに微調整されたトルコ語教育質問と回答用のチャットボットで、トルコ語教育シーンに特化して最適化されています。
MCPゴムダックは、モデルコンテキストプロトコル(MCP)に基づくサーバーで、複数のOpenAI互換のLLMを照会するためのブリッジとして機能します。ゴムダックデバッグ法のように、ユーザーが異なるAI「ダック」に問題を説明し、多様な視点からの回答を得ることができます。さまざまなAIプロバイダーをサポートし、会話管理、多モデル比較、コンセンサス投票、議論、反復最適化などの高度なツールを提供し、MCPブリッジ機能を通じて他のMCPサーバーに接続して機能を拡張することができます。
Cortex MCPはモデルコンテキストプロトコルサーバーで、Cortex APIへのアクセスを提供し、ワークスペースに関連するコンテキストを利用して質問の回答精度を向上させます。
このプロジェクトは、Google Cloud Vertex AI Geminiモデルに基づくMCPサーバーで、コード支援と一般的な質問応答に使用する豊富なツールセットを提供します。Web検索強化型の回答、ドキュメントの説明生成、ファイルシステム操作などの機能をサポートしています。
このプロジェクトでは、IBM Watsonx.aiに基づく検索強化生成(RAG)サーバーを構築し、ChromaDBを使用してベクトルインデックスを作成し、モデルコンテキストプロトコル(MCP)を通じてインターフェイスを公開します。このシステムはPDFドキュメントを処理し、ドキュメントの内容に基づいて質問に回答し、大規模言語モデルと特定分野の知識を組み合わせたスマートな質問応答機能を実現します。
Multi - Model AdvisorはOllamaに基づくマルチモデル相談システムで、複数のAIモデルの異なる見解を統合することで、問題に対してより包括的な解答を提供します。「アドバイザー委員会」モードを採用し、Claudeが複数のAI視点を総合して回答を生成することができます。
Gemini DeepSearch MCPは自動化された研究エージェントで、Google GeminiモデルとGoogle検索を利用して、深く多段階のウェブ研究を行い、高品質な引用付きの回答を生成します。
MCPプロトコルを通じて直接OpenAIモデルをクエリするサーバーで、o3 - miniとgpt - 4o - miniモデルをサポートし、簡潔で詳細な回答を提供します。
Anthropicのモデルコンテキストプロトコルをベースにした実装で、Claudeデスクトップアプリケーションを通じてnotes.txtファイルを作成、更新、読み取り、要約し、そのファイルの内容をコンテキストとして質問に回答します。
Perplexity MCP Serverは、Perplexityの専用AIモデルを利用したインテリジェントな研究アシスタントで、クエリの複雑度に基づいて最適なモデルを自動的に選択して回答します。迅速な検索、複雑な推論、深度研究の3つのツールをサポートし、様々な複雑度のクエリニーズに対応します。
 Transformers英語
Transformers英語%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)