Google DeepMindのVeo3動画生成モデルはテストで予想を上回る多タスク処理の潜在能力を示し、視覚AIの重要な進展と見なされている。その核心的な突破はゼロサンプル学習能力であり、専門的な訓練なしに複数の複雑な視覚タスクに対応できる点が特徴で、強力な汎化性能を示している。
智元机器人がGO-1汎用モデルをオープンソース化。ViLLAアーキテクチャを採用し、視覚・言語・動作能力を統合、複雑タスクの処理性能を向上。開発者向けに無料公開。....
9月19日、小米社は自社初のネイティブなエンド・トゥ・エンド音声大規模モデル Xiaomi-MiMo-Audio をオープンソース化することを発表しました。この革新的な成果は、音声技術分野における大きな突破を示しています。5年前にGPT-3が登場し、言語の汎用人工知能(AGI)の新しい時代を開いたことから、音声分野では大規模なラベル付きデータに依存する制約があり、言語モデルと同様の少サンプル一般化能力を達到することが困難でした。今や、小米が公開した Xiaomi-MiMo-Audio モデルは、革新的な前訓練技術に基づいています。
上海AI研、多モーダル大規模モデル「InternVL3.5」をオープンソース化。階層型強化学習や動的視覚解像度ルーティングなどの新技術を採用し、推論能力や汎用性能を向上。1B~241Bの全サイズ版を提供し、オープンソースモデルの性能基準を更新。....
智元は、汎用具象基盤大規模モデルGO-1を発表し、革新的なViLLAアーキテクチャを提案することで、具象知能の発展を推進しています。
低コストで視覚言語モデルの汎化能力を強化。わずか3ドル未満。
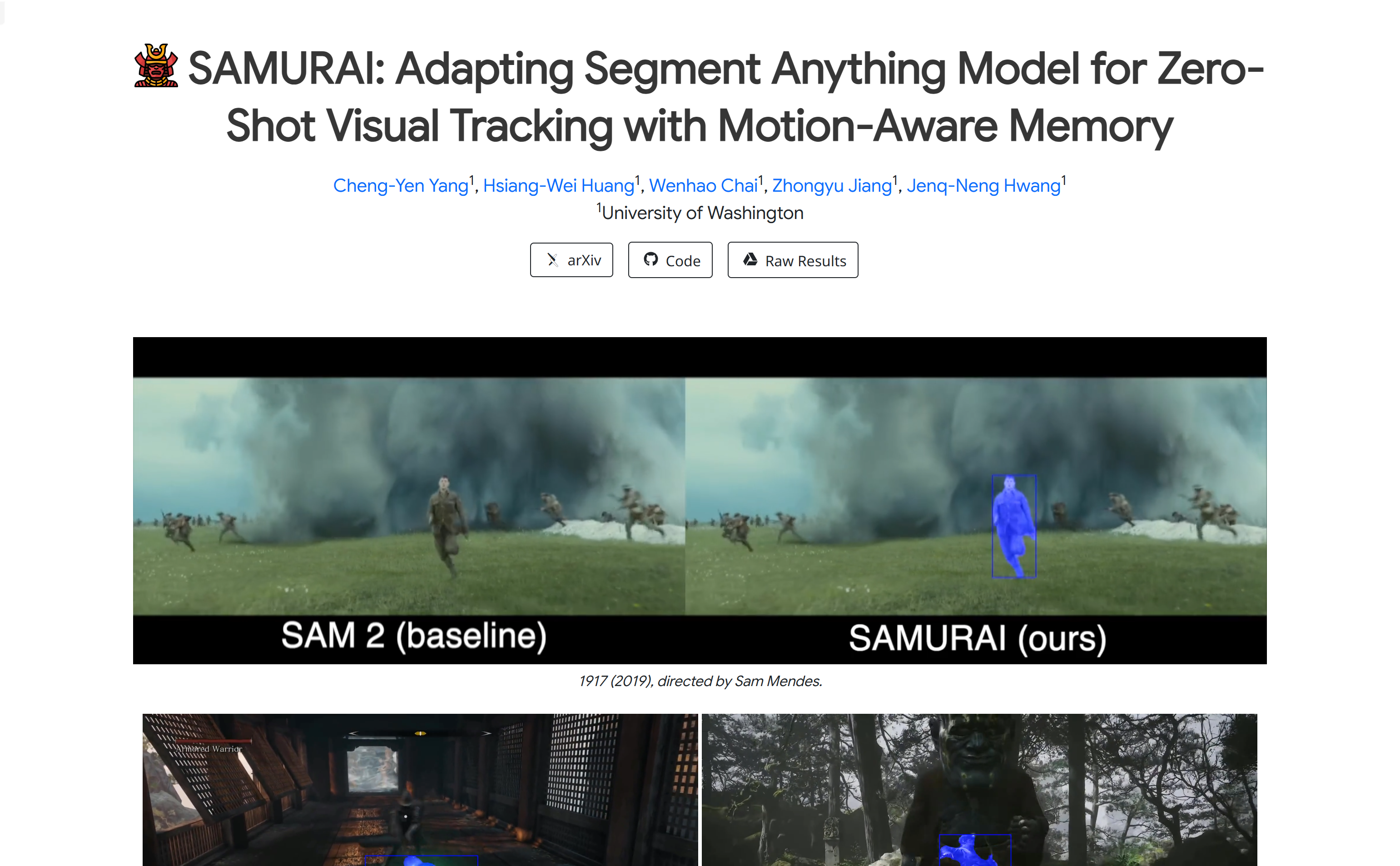
ゼロショットビジュアルトラッキングモデル。運動知覚メモリを備えています。
野外音声?映像データを用いたロボット操作学習
openai
$108
入力トークン/百万
$432
出力トークン/百万
128k
コンテキスト長
alibaba
$0.72
-
deepseek
$1.01
$2.02
$3.6
$10.8
4.1k
GilbertAkham
これはDeepSeek-R1-Distill-Qwen-1.5Bをベースとしたマルチタスク微調整モデルで、LoRAアダプタを使用して複数のデータセットで訓練され、強力なマルチタスク汎化と推論能力を備え、幅広い自然言語と推論ベースのタスクを処理できます。
lerobot
π₀.₅はPhysical Intelligenceによって開発された視覚 - 言語 - 動作モデルで、オープンワールド汎化能力を備えており、訓練時に一度も見たことのない全く新しい環境やシーンでロボットタスクを実行することができます。
mldi-lab
Kairos-10Mは、異分野のゼロショット予測に特化して設計された時系列基礎モデルで、約1000万のパラメータを持っています。異なる情報密度の異種時系列データを処理でき、微調整することなく異なる分野で強力な汎化能力を発揮します。
Kairos-50Mは5000万のパラメータを持つ時系列基礎モデルで、異なる分野にまたがるゼロショット予測に特化しています。適応的分詞と位置符号化技術を採用し、異なる情報密度を持つ異種時系列データを処理でき、微調整することなく異なる分野で強力な汎化能力を実現します。
XiaomiMiMo
MiMo Audioは大規模事前学習に基づく音声言語モデルで、音声インテリジェンスと音声理解のベンチマークテストでオープンソースモデルのSOTA性能を達成しました。このモデルは強力な少サンプル学習能力を示し、学習データに含まれないタスクに汎化でき、音声変換、スタイル移行、音声編集などのさまざまな音声タスクをサポートします。
samuelsimko
これはTransformerアーキテクチャに基づく事前学習モデルです。具体的な機能と特性は実際のモデル情報に基づいて補完する必要があります。モデルは複数の下流タスクをサポートし、良好な汎化能力を備えています。
OpenGVLab
InternVL3.5-4Bはオープンソースのマルチモーダルモデルシリーズの中規模バージョンで、汎用性、推論能力、推論効率の面で顕著な進歩を遂げ、GUIインタラクションなどの新機能をサポートしています。このモデルはカスケード強化学習フレームワークと視覚解像度ルーター技術を採用し、効率的なマルチモーダル理解と推論を実現しています。
arunimas1107
これはopenai/gpt-oss-20bをベースに医療分野で微調整されたLoRAアダプターモデルで、医療質問応答、摘要生成、知識検索などのタスクに特化して最適化されています。このモデルは、効率的なパラメータ微調整技術を用いて、200億パラメータのベースモデルの汎用推論能力を維持しながら、医療分野での性能を向上させています。
ertghiu256
これはQwen3-4B-Thinking-2507ベースモデルに基づいて、TIES方法を通じて複数の微調整モデルをマージして得られた強化型言語モデルで、コード生成と数学推論能力の向上に特化し、同時に優れた汎用言語理解能力を維持しています。
NVFP4
Qwen3-30B-A3B-Thinking-2507は、推論能力と汎用能力が著しく向上した大規模言語モデルで、長文脈理解能力を強化し、高度に複雑な推論タスクに適しています。このモデルは305億のパラメータを持ち、そのうち33億のパラメータがアクティブで、262,144トークンの長文脈処理をサポートしています。
MonkeyDAnh
これはRoBERTa-baseを微調整したAIテキスト検出モデルで、AI生成テキストと人間が書いたテキストを区別するために特別に設計されています。モデルは複数のデータセットで順次微調整され、高精度の検出能力と良好な汎化性能を備えています。
cpatonn
Qwen3-30B-A3B-Thinking-2507は量子化処理された大規模言語モデルで、強化された推論能力、汎用能力、長文脈理解能力を持っています。このモデルは混合エキスパートアーキテクチャを採用しており、論理推論、数学、科学、コーディングなどの複雑なタスクで優れた性能を発揮し、262,144トークンの長文脈処理をサポートしています。
QuantTrio
Qwen3-235B-A22B-Thinking-2507-AWQは、Qwen/Qwen3-235B-A22B-Thinking-2507ベースモデルに基づく量子化バージョンで、推論タスクで優れた性能を発揮し、より高い汎用能力と長文脈理解能力を持っています。このモデルは混合エキスパートアーキテクチャを採用し、総パラメータ数は235B、活性化パラメータは22Bで、256Kの文脈長をサポートします。
Qwen
Qwen3-235B-A22B-Thinking-2507-FP8はアリババクラウドが開発した強力なテキスト生成モデルで、推論能力、汎用能力、長文脈理解能力などの面で著しい向上が見られます。このモデルは2350億のパラメータを持ち、220億のパラメータが活性化され、256Kの長文脈をサポートし、高度に複雑な推論タスクに特化して最適化されています。
Qwen3-235B-A22B-Instruct-2507はQwen3シリーズモデルの更新バージョンで、汎用能力、希少知識のカバレッジ、ユーザーの嗜好アライメント、長文脈理解などの面で著しい向上が見られ、より質の高いテキスト生成サービスを提供できます。このモデルは混合専門家アーキテクチャを採用し、合計235Bのパラメータのうち、22Bのパラメータが活性化され、ネイティブで262,144の文脈長をサポートします。
RedHatAI
Qwen/Qwen3-8B用に特別に設計された推測デコードモデルで、EAGLE - 3アルゴリズムを採用してテキスト生成の効率と品質を向上させ、複数の優良データセットで訓練され、優れた汎化能力を獲得しています。
lhjiang
AnySplatは、高度な3Dガウス散点レンダリングモデルで、異なる視点の画像から効率的に高品質の3Dシーンを生成することができます。このモデルは、高速推論能力と良好な汎化性能を持ち、3D再構築とレンダリングに革新的な解決策を提供します。
MathLLMs
MathCoder-VLシリーズのオープンソース大規模マルチモーダルモデルで、汎用数学問題解決のために設計され、視覚とコードを組み合わせて数学推論能力を強化します。
unsloth
Whisperは事前学習済みの自動音声認識(ASR)および音声翻訳モデルで、68万時間の注釈付きデータで訓練されており、強力な汎化能力を持っています。
WhisperはOpenAIが開発した最先端の自動音声認識(ASR)および音声翻訳モデルで、500万時間以上のラベル付きデータでトレーニングされ、強力なゼロショット汎化能力を備えています。Turboバージョンはオリジナルのプルーニングおよび微調整バージョンで、デコード層を32層から4層に削減し、速度が大幅に向上していますが、品質はわずかに低下しています。
 Safetensors
Safetensors%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)