AdobeがプロフェッショナルなAI画像生成モデルであるFirefly Image5を発表しました。これにより、「十分使える」から「プロフェッショナルなレベル」への質的飛躍が実現されました。新機能には400万ピクセルのネイティブ出力、階層化されたヒント編集、カスタムアートスタイルモデルおよびAI音声トラック生成が含まれ、画像、動画、音声のAIクリエーションの完結したループを構築し、クリエイティブワークフローを再定義します。
Metaは、FacebookのAI写真編集アドバイス機能が米国およびカナダで全面的にリリースされたことを発表しました。この機能は、ユーザーが共有していないカメラアルバムの写真にアクセスし、編集の提案を行い、AIで最適化された画像をダイナミックまたはストーリーに投稿するよう促します。今年の夏にテストが実施され、アプリを開くたびに、カスタマイズされたクリエイティブな推奨を行うためにクラウド処理の権限を許可するリクエストが表示されました。
マイクロソフトがAzure AIプラットフォームでOpenAIの動画生成モデルSora2をパブリックプレビュー公開。クラウドAPI経由で企業・開発者向けに提供され、テキスト・画像・動画を入力に新規動画を生成可能。広告など商業利用の開始で生成AI動画ツールが本格商用化へ。....
VideoFrom3Dフレームワークは3Dグラフィックデザインを革新し、画像と動画の拡散モデルを活用して、粗い幾何学やカメラパス、参照画像から現実的で統一されたスタイルの3Dシーン動画を生成します。高価なペアデータは必要なく、プロセスを簡素化し、デザイナーが効率的にクリエイティブな探求と迅速な作成をサポートします。コアとなるのは補完的な拡散モデルの革新的な統合です。
NeonLights AIは先進的なAIクリエイティブプラットフォームで、テキストやコンテンツから画像、ビデオ、アニメーションを作成することができます。
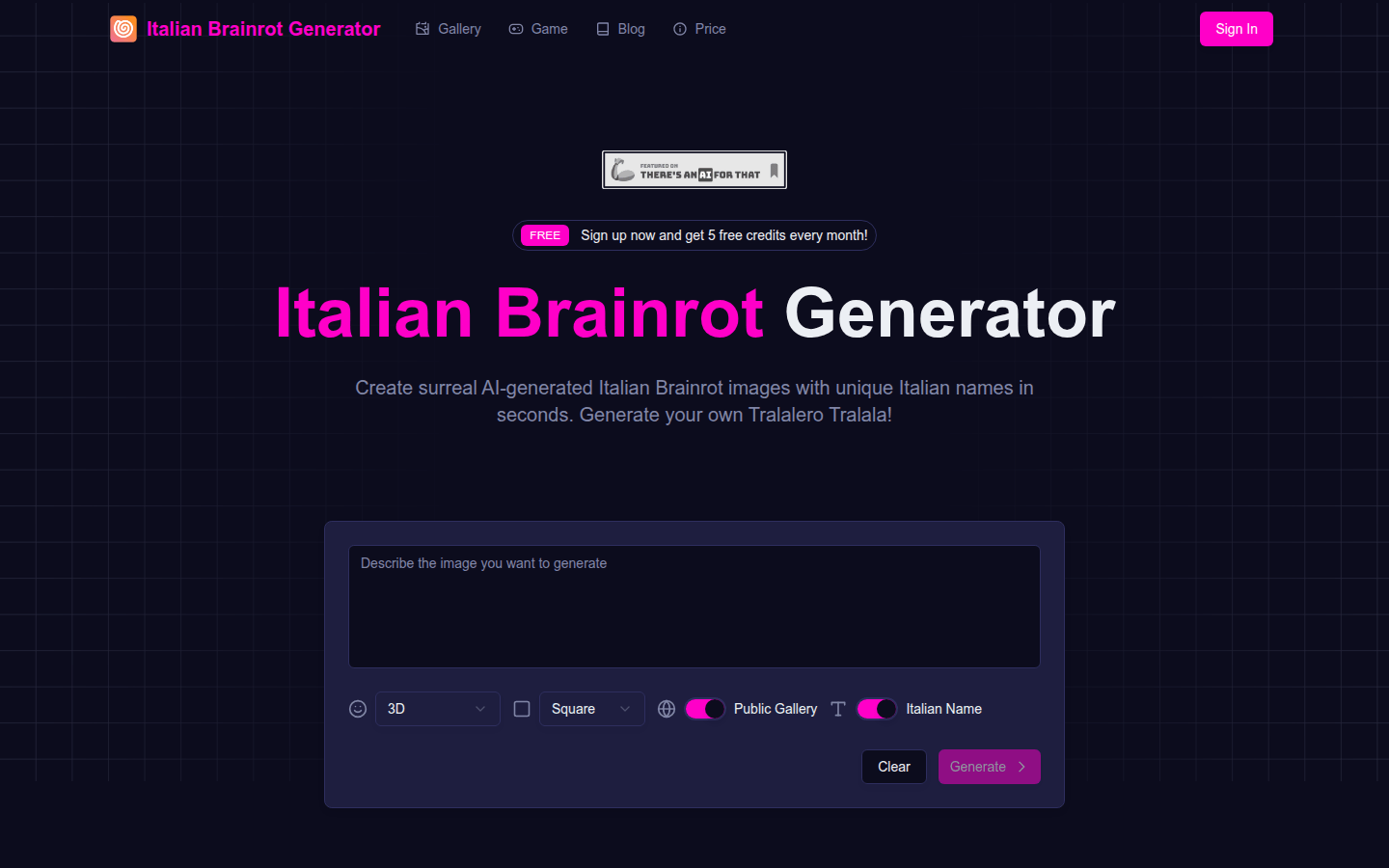
超現実的な「イタリアンブレインロット」ミーム画像を生成し、あなた独自のトララレロトララキャラクターを作成します。
画像と音声からビデオを生成するインタラクティブなストーリーテリングAIプラットフォーム。
Midjourney srefコードライブラリ。豊富なスタイルの参考コードを提供し、Midjourneyでの多様な画像制作を支援します。
google
$2.16
入力トークン/百万
$18
出力トークン/百万
1M
コンテキスト長
openai
-
128k
$144
$288
32k
bytedance
$4
$16
Svngoku
Qwen3-VL-TimeTravelは、Qwen3-VL-8B-Instructモデルをベースに、Unslothライブラリを使用してMBZUAI/TimeTravelデータセットで微調整したバージョンです。このモデルは、歴史文物画像の説明を生成するために特別に設計されており、歴史および文化文物の分析において専門的な能力を持っています。
John6666
Noobai-XL-1.0はdiffusersライブラリに基づくテキストから画像への生成モデルで、アニメスタイルのガール画像の生成に特化しています。このモデルはHetaKonekoによって作成され、Laxhar/noobai-XL-1.0をベースにしており、独特なスタイルのアニメ画像を生成することができます。
EarthnDusk
Earth & Duskプロジェクトは、OnomaAIResearch/Illustrious-xl-early-release-v0ベースモデルに基づくテキストから画像への変換プロジェクトで、diffusersライブラリを使用して画像生成を実現します。このプロジェクトはアート創作に特化しており、CREATIVE ML OPEN RAIL Mライセンスを採用し、0FTH3N1GHT PRODUCTIONSによる監督の下で行われています。
これは、アニメやカートゥーンスタイルの画像生成に特化したテキストから画像への生成モデルで、幻想や美少女などの様々な要素を含むアニメスタイルの画像を生成できます。モデルはOnomaAIResearch/Illustrious-xl-early-release-v0ベースモデルを基に構築され、diffusersライブラリを使用して実装されています。
hunyuanvideo-community
HunyuanImage-2.1 画像リファイナーは、diffusersライブラリに基づいて構築された画像から画像への変換モデルで、入力画像を特定のスタイルの画像に変換することができ、高品質な画像生成とスタイル変換をサポートします。
chaitnya26
Qwen-Image-Lightningは、Qwen/Qwen-Imageに基づくテキストから画像への生成モデルで、蒸留とLoRA技術を通じて高速かつ高品質な画像生成を実現し、diffusersライブラリを使用した簡便な呼び出しをサポートしています。
sothmik
これはCivitaiプラットフォームに基づくテキストから画像生成モデルで、テキスト記述を高品質な画像に変換することができます。モデルは量子化ツールを通じて最適化することができ、クリエイティブデザインやビジュアルコンテンツ生成に適しています。
これはdiffusersライブラリに基づくテキストから画像を生成するモデルで、リアルなスタイルの小马画像を生成するために特別に開発されました。このモデルは色彩表現、光と影の効果、コントラストにおいて優れた性能を発揮し、高品質でリアルな小马画像を生成することができます。
calcuis
KreaのGGUF量子化バージョンは、FLUX.1アーキテクチャに基づくテキストから画像への生成モデルです。GGUF量子化技術により、モデルサイズと推論効率が最適化され、diffusersライブラリ、ComfyUI、gguf-connectorなどの複数の方法で実行できます。
QuantStack
これはblack-forest-labs/FLUX.1-Krea-devモデルのGGUF形式の量子化バージョンで、テキストから画像への生成タスクに特化しています。このモデルはGGUF形式で最適化されており、特定のツールやライブラリで使用でき、非商用の画像生成アプリケーションに適しています。
Keltezaa
AiGirl_IIは、black-forest-labs/FLUX.1-devをベースに構築されたテキストから画像を生成するモデルで、LoRA技術とDiffusersライブラリを組み合わせて、特定のスタイルの画像を生成するために特別に設計されています。このモデルはCC BY-NC-ND 4.0ライセンスを採用しており、非商用用途に適しています。
mradermacher
Perseus-Doc-vl-0712量子化モデルは、テキスト生成推論、画像キャプション生成、光学文字認識などの多領域アプリケーションをサポートするビジュアルと言語の理解モデルで、transformersライブラリに基づいて構築されています。
black-forest-labs
FLUX.1 Krea [dev] は、120億のパラメータを持つ整流フロー変換器で、テキスト記述に基づいて高品質な画像を生成するために特別に設計されています。出力品質や指示の遵守などの面で優れた性能を発揮し、美学写真に特化しており、効率的なガイド付き蒸留トレーニング方式を採用し、ウェイトを公開して研究やクリエイティブな作業を促進しています。
gaianet
Gemma-3n-E4B-itはGoogleがリリースした軽量級言語モデルで、transformersライブラリに基づいており、画像テキストからテキストへのタスクに適しています。
LPX55
拡散器(diffusers)ライブラリに基づく実験的画像生成モデルで、LoRA融合と量子化処理に特化しています。
rabidgremlin
RTXレイトレーシング版『マインクラフト』ゲームスクリーンショットで微調整されたStable Diffusionモデル。ブロックワールドスタイルのレイトレーシング効果画像を生成可能
meta-llama
Llama Guard 4はネイティブマルチモーダルセキュリティ分類器で、120億のパラメータを持ち、テキストと複数画像を連携してトレーニングされ、大規模言語モデルの入力と出力のコンテンツセキュリティ評価に使用されます。
OpenGVLab
InternVL3-2BはHugging Face Transformersライブラリに基づいて実装されたマルチモーダル大規模言語モデルで、画像、ビデオ、テキスト処理などのマルチモーダルタスクで優れた性能を発揮し、さまざまな入力方式と効率的なバッチ推論をサポートします。
fahadh4ilyas
Llama 4シリーズはMetaが開発したネイティブマルチモーダルAIモデルで、ハイブリッドエキスパートアーキテクチャを採用し、テキストと画像のインタラクションをサポートし、様々な言語とビジュアルタスクで卓越した性能を発揮します。
Llama 4シリーズはMetaが開発したネイティブマルチモーダルAIモデルで、テキストと画像のインタラクションをサポートし、ハイブリッドエキスパートアーキテクチャを採用しており、テキストと画像の理解において卓越した性能を発揮します。
LangGraphベースのエージェントツールで、ユーザーがAIを通じて画像を生成し、ストーリーブロックチェーン上のIP資産として登録するのを支援します。画像生成、IPFSアップロード、メタデータ作成、ライセンス条項の交渉、ブロックチェーン登録までの全プロセスを含みます。
exif - mcpはexifrライブラリに基づくMCPサーバーで、オフラインで画像メタデータを抽出して分析するために使用され、複数の画像形式とメタデータセグメントをサポートし、画像ライブラリ分析、開発デバッグなどのシーンに適しています。
UnsplashスマートMCPサーバーは、AIエージェント向けの専用画像ライブラリ統合ソリューションです。スマートな検索、自動帰属、およびプロジェクト認識型の画像管理機能を提供し、開発者のビジュアルコンテンツ取得プロセスを簡素化します。
このプロジェクトはMCPプロトコルとpython - pptxライブラリに基づくPPT作成サービスで、チャットインタラクションを通じてPowerPointプレゼンテーションを動的に作成、編集、保存することをサポートしています。スライドの追加、画像や表の挿入などの様々な機能を提供し、ダウンロードリンクを生成し、Base64形式でエクスポートすることもできます。
Sharpライブラリに基づく画像処理MCPサービスで、サイズ調整、形式変換、トリミング、回転、画像情報の取得などの機能を提供します。
Puppeteer MCPサーバーは、Puppeteerに基づくブラウザ自動化機能を提供し、ウェブページのインタラクション、スクリーンショット、画像の抽出とダウンロード、JavaScriptの実行などの機能をサポートし、実際のブラウザ環境でのウェブページ操作を実現します。
rembg背景除去ライブラリをベースとしたMCPサーバーで、AIモデルを通じてClaudeなどのツールに画像背景除去機能を提供し、複数のモデルとバッチ処理に対応しています。
go-mcp-harborは、go-mcp SDKをベースに開発されたMCPサービスとクライアントのサンプルライブラリで、高德MCPクライアントとMiniMax海螺のMCPサーバーおよびクライアントの実装を含み、テキストから音声への変換、テキストから画像への生成、音声クローンなどの機能をサポートし、個人開発の参考のみに供されます。
Traylinx検索エンジンMCPサーバーは、Agentic検索APIを接続するブリッジサービスで、MCPクライアント(ClaudeやCursorなど)がインテリジェントな検索機能を使用し、テキスト要約と構造化データ(HTML、画像など)を取得できるようにします。
Grok AI MCP ServerはNode.jsベースのサーバーで、xAI Grok APIを統合し、Solanaブロックチェーンに強力なAI駆動の分析ツールを提供します。トランザクション分析、アドレス分析、画像分析、および汎用クエリをサポートし、Model Context Protocol (MCP)を通じて標準化されたインターフェースを提供します。
mammothライブラリに基づくDOCX文書処理用のMCPサーバーで、テキスト抽出、HTML変換、構造解析、画像抽出、Markdown変換などの機能を提供し、完全な形式の保持と文書解析をサポートします。
 Diffusers多言語
Diffusers多言語%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)