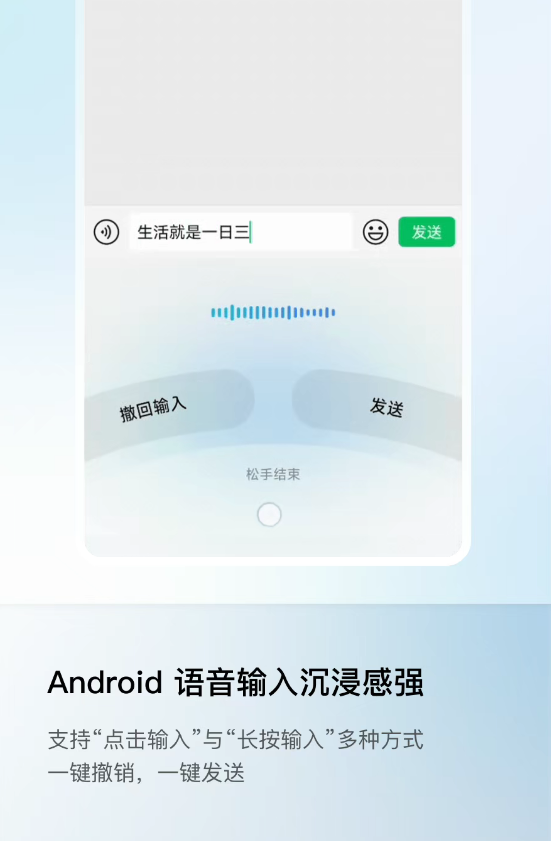
微信入力法iOS新版で音声入力が大幅強化。基盤モデルを最適化し、認識速度と精度向上。最大の特徴は多言語・多方言の自動認識対応で、手動切り替え不要。....
SpeechifyがChrome拡張機能に音声検出機能を追加。音声入力と音声アシスタントをサポートし、文書処理効率を向上。先進的音声認識技術でリアルタイム誤り訂正・不要語の自動削除を実現し、競争力強化。....
豆包入力法がAndroidでリリース、iOSも近日公開。豆包Appの音声モデルを基に、音声認識・意味理解・入力効率を向上。方言・英語・中英混合入力に対応し、小声・早口・騒音環境でも利用可能。音声入力後の自動修正が中核機能。....
メタはOmnilingual ASR自動音声認識システムを発表しました。このシステムは1600を超える口語言語の変換に対応しており、AIツールの言語カバー不足問題を解決することを目的としています。従来の主流言語に特化した制限を乗り越え、汎用的な変換システムの実現を目指し、世界中の数千種類の言語がAIによってサポートされていないギャップを埋める支援を行います。
高品質の英語自動音声認識モデルで、句読点とタイムスタンプの予測をサポートしています。
オープンソースの産業レベル自動音声認識モデル。標準中国語、方言、英語に対応し、優れた性能を誇ります。
オープンソースの工業レベル標準中国語自動音声認識モデルで、様々なアプリケーションシナリオに対応しています。
PengChengStarlingは、icefallプロジェクトをベースとした多言語自動音声認識(ASR)モデル開発ツールキットです。
Anthropic
$105
入力トークン/百万
$525
出力トークン/百万
200
コンテキスト長
$21
Alibaba
$8
$240
52
$3.9
$15.2
64
$15.8
$12.7
-
Bytedance
Xai
$1.4
$10.5
256
Baidu
Huawei
128
Tencent
24
$2.4
$12
8
$0.3
32
Iflytek
$2
kyr0
これはAppleシリコンチップデバイス用に最適化された自動音声認識モデルで、MLXフレームワークに変換し、FP8形式に量子化することで、Appleデバイス上での高速なエッジ上の音声文字起こしを実現します。このモデルは逐語的な精度に合わせて微調整されており、高精度の文字起こしが必要なシーンに特に適しています。
ai-sage
GigaAM-v3はConformerアーキテクチャに基づくロシア語自動音声認識の基礎モデルで、2.2 - 2.4億のパラメータを持っています。これはGigaAMシリーズの第3世代モデルで、70万時間のロシア語音声データを使用してHuBERT - CTC目標で事前学習され、幅広いロシア語ASR分野で最先端の性能を提供します。
abr-ai
これはApplied Brain Research(ABR)によって開発された、状態空間モデル(SSM)に基づく英語の自動音声認識モデルです。約1900万のパラメータを持ち、英語の音声を効率的かつ正確にテキストに変換することができます。このモデルは複数のベンチマークデータセットで優れた性能を発揮し、平均単語誤り率はわずか10.61%です。リアルタイム音声認識をサポートし、低コストのハードウェアで動作することができます。
adoamesh
このモデルは、OpenAIのWhisper-smallモデルをベースに、スワヒリ語に対して微調整された自動音声認識モデルです。FLEURS - SLUデータセットのスワヒリ語部分で訓練され、スワヒリ語の文字起こしの精度が大幅に向上し、単語誤り率がベースモデルに比べて68%低下しました。
thenexthub
これは多言語処理をサポートするマルチモーダルモデルで、自然言語処理、コード処理、音声処理などの複数の分野をカバーし、自動音声認識、音声要約、音声翻訳、ビジュアル質問応答などの様々なタスクを実行できます。
teckedd
このモデルは、OpenAI Whisper-smallをCommon Voice 17.0データセットで微調整した自動音声認識モデルで、Twi言語に特化して最適化されており、音声内容を正確に認識できます。
Ken-Z
このモデルは、OpenAI Whisper-smallをベースにラテン語で微調整された自動音声認識モデルです。67時間のラテン語オーディオデータを使用して訓練され、文字誤り率(CER)は20で、ラテン語の音声をテキストに変換するタスクをサポートしています。
eustlb
これはHugging Face Transformersライブラリに基づく自動音声認識モデルで、音声内容をテキストに変換することができます。このモデルは複数の言語をサポートし、リアルタイムの音声をテキストに変換する、音声の文字起こしなどのシナリオに適用されます。
Vikhrmodels
ボレアリスは、ロシア語向けの最初の自動音声認識(ASR)オーディオ大規模言語モデルで、約7000時間のロシア語オーディオデータで訓練されています。このモデルは、オーディオ内の句読点を認識することができ、アーキテクチャはVoxtralに影響を受けていますが、改良されており、複数のロシア語ASRベンチマークテストで優れた性能を発揮しています。
feelmadrain
これはOpenAI Whisper Smallアーキテクチャに基づくロシア語の自動音声認識モデルで、Common Voice 17.0データセットで特別に訓練され、ロシア語の音声を正確にテキストに変換できます。
BUT-FIT
SE-DiCoWは、BUT Speech@FITがJHU CLSP/HLTCOEおよびCMU LTIと共同開発した、ターゲット話者の多話者自動音声認識モデルです。このモデルはWhisper large-v3-turboをベースに、自己登録メカニズムと改良されたデータ拡張技術により、高度に重畳した多話者シナリオでの認識精度を大幅に向上させています。
UsefulSensors
Moonshine Tinyは、Moonshine AI(旧有用センサー会社)によって開発された軽量のベトナム語自動音声認識モデルで、たった27Mのパラメータしか持たず、リソース制限のあるプラットフォーム向けに設計されており、FleursとCommon Voice 17のデータセットで優れた性能を発揮します。
FluidInference
parakeet-tdt-0.6b-v3は強力な多言語自動音声認識モデルで、英語、スペイン語、フランス語、ドイツ語などの多くの欧州言語をサポートしています。FastConformer-TDTアーキテクチャに基づき、公開データセットを使用して訓練され、言語を超えた音声認識に効率的な解決策を提供します。
istupakov
NVIDIA Parakeet TDT 0.6B V3は多言語自動音声認識モデルで、パラメータ数は6億で、英語、スペイン語、フランス語、ドイツ語など25種類のヨーロッパ言語をサポートし、音声をテキストに変換できます。
NexaAI
OpenAI Whisperアーキテクチャに基づいて微調整された自動音声認識と音声翻訳モデルで、デコード層の数を減らすことで大幅な速度向上を実現し、同時にオリジナル版に近い認識品質を維持します。
mradermacher
これはGemmaモデルに基づく静的量子化バージョンで、自動音声認識、自動音声翻訳などの様々なタスクに適しています。
Parakeet TDT 0.6B v2 MLXは、効率的な自動音声認識モデルで、句読点、大文字小文字、正確なタイムスタンプ予測をサポートし、最大24分のオーディオフラグメントを文字起こしできます。商用および非商用用途に適しています。
kimthegarden
Whisper-smallアーキテクチャをベースに微調整された韓国語自動音声認識モデルで、韓国語音声認識タスクで優れた性能を発揮します。
amedcj
クルド語のクルマンジ方言に特化した自動音声認識モデルで、Whisperアーキテクチャを微調整したものです。
MediaTek-Research
Breeze ASR 25は、Whisper-large-v2を微調整した高度な自動音声認識モデルで、台湾普通話と普通話 - 英語のコード切り替えシナリオの認識能力を特別に最適化しています。
ASR MCPサーバーは、whisperエンジンに基づく自動音声認識サービスで、MCPツールを通じて音声合成機能を提供し、アプリへの統合が容易です。
 Transformers英語
Transformers英語%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)