声網はメイドゥーなどと共同でAI電話呼び出しの評価基準であるVoiceAgentEvalを発表し、実践性を強調し、6つの分野と30のサブシナリオをカバーしています。この評価基準は実際に使われるビジネスデータを活用し、業界の標準化の発展を促すことを目的としています。
カリフォルニアのチップ企業Cerebras Systemsが10億ドルの資金調達を完了し、評価額は230億ドルに達し、1年で約3倍に増加。独自のウェハースケールエンジン技術が従来のチップアーキテクチャを革新し、シリコンバレーのベンチャーキャピタルBenchmark Capitalが主導する投資は、非GPUコンピューティングルートへの市場の期待を示している。....
ゲーム科学のCEO馮驥氏は、ByteDanceのSeedance 2.0動画生成モデルを高く評価し、AIのマルチモーダル理解の飛躍を代表し、映像業界を覆し、一般的な動画制作コストを大幅に削減すると述べた。....
Anthropicは200億ドルの資金調達を実施中で、評価額は3500億ドルに達する見込み。投資家の需要が高く、当初予定の2倍規模に拡大。AIモデル競争激化と計算コスト上昇を受け、5ヶ月前の130億ドル調達に続く大規模資金確保が必要となった。....
急速に成長するスタートアップ企業向けに開発されたAI採用プラットフォームで、候補者の評価や面接の準備などが可能です。
AI LinkedIn投稿コーチ。投稿をリアルタイムで評価し、改善し、自信を持って投稿できるようサポートします。
プリティースケールは写真を通じて顔の特徴を分析し、瞬時に顔の評価点を出し、機能が豊富で面白いです。
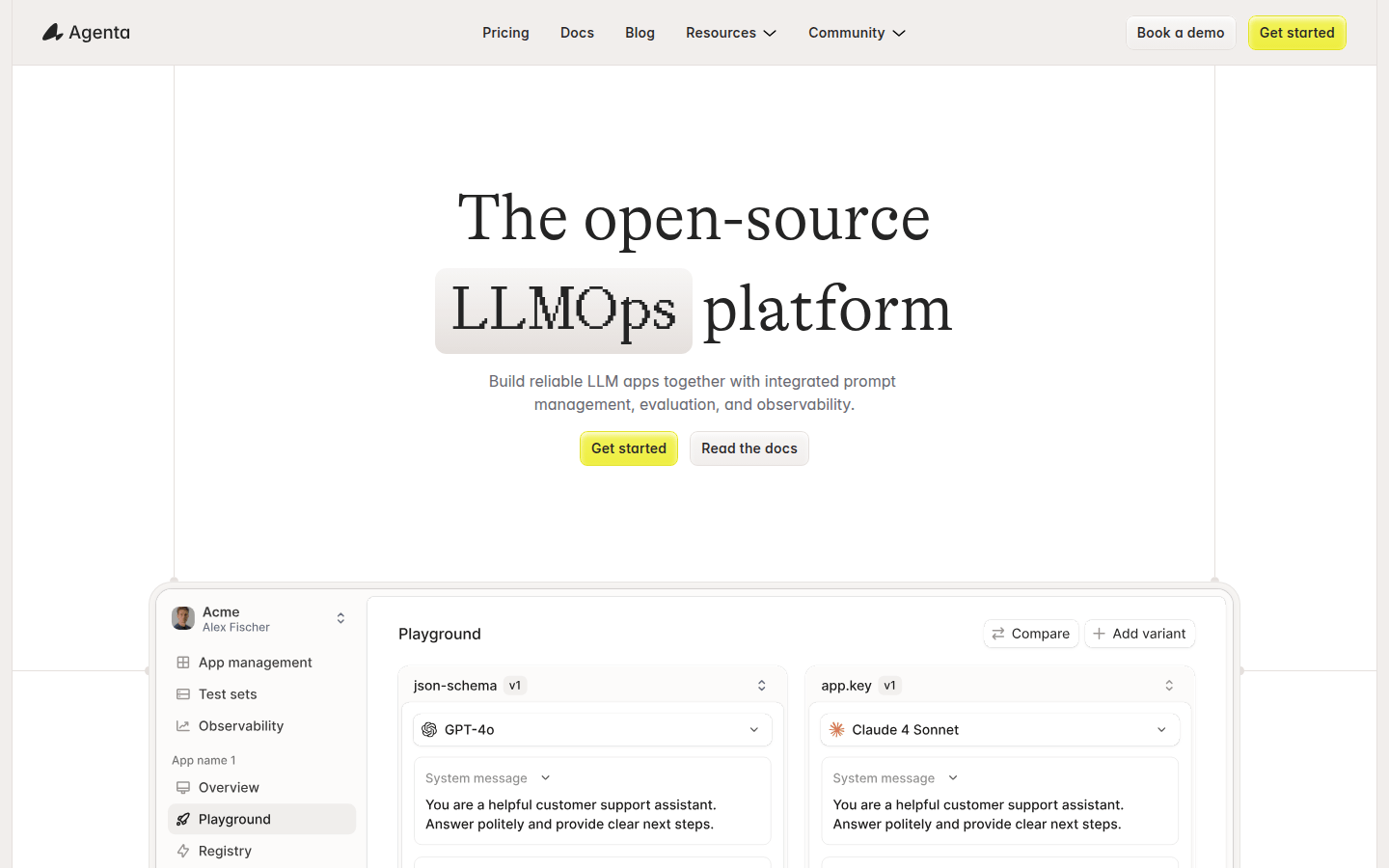
オープンソースプラットフォームで、LLMアプリケーションのプロンプト管理、評価、および可観測性ツールを提供します。
Bytedance
$0.8
入力トークン/百万
$2
出力トークン/百万
128
コンテキスト長
Openai
$0.35
$2.8
400
Tencent
-
24
Alibaba
$1.8
$5.4
16
32
Baidu
$4
$8
28
$0.7
1k
$1.5
$6
Chatglm
30
Baichuan
Minimax
$1
64
250
$100
01-ai
200
4
$5
drbaph
Z-Image(造相)は60億のパラメータを持つ高効率な画像生成基礎モデルで、画像生成分野の効率と品質の問題を専門的に解決します。その蒸留バージョンであるZ-Image-Turboは、たった8回の関数評価でリーディングな競合モデルに匹敵するか、それを上回る性能を発揮し、企業用のH800 GPUでは亚秒級の推論遅延を実現し、16G VRAMの消費者向けデバイスでも動作します。
Shawon16
これはVideoMAEアーキテクチャに基づくビデオ理解モデルで、Kineticsデータセットで事前学習した後に微調整され、手話認識タスクに特化しています。モデルは評価セットでの性能向上が必要で、正解率は0.0010です。
これはVideoMAE-baseアーキテクチャに基づくビデオ理解モデルで、未知のデータセットで20エポックの微調整トレーニングを行いました。モデルは評価セットでの性能が限られており、正解率は0.0041、損失値は7.7839です。
KonradBRG
このモデルは、FacebookAI/xlm-roberta-largeを多言語テキストで微調整したジョーク評価モデルで、ジョークの品質とユーモア度を評価するために特化しています。評価セットで0.4005の正解率と5.0327の二乗平均平方根誤差を達成しています。
これはMCG - NJU/videomae - baseモデルを未知のデータセットで微調整した動画理解モデルで、20エポックの学習を経て、評価セットで13.31%の正解率を達成しました。このモデルは動画分析タスクに特化して最適化されています。
advy
このモデルは、meta-llama/Llama-3.1-70B-Instructを特定のデータセットで微調整した大規模言語モデルで、テキスト生成タスクに特化しており、評価セットで0.6542の損失値を達成しています。
Foshie
これはGoogleのmT5-smallモデルをアマゾンのデータセットで微調整した英語からスペイン語への翻訳モデルで、テキスト要約生成タスクに特化しています。モデルは評価セットでRouge1: 16.44、Rouge2: 8.04のスコアを獲得しました。
Maxlegrec
BT4モデルはLeelaChessZeroエンジンの背後にあるニューラルネットワークモデルで、チェス対局に特化しています。このモデルはTransformerアーキテクチャに基づいて設計されており、過去の手順に基づいて次の最適な手順を予測し、局面を評価し、手順の確率を生成することができます。
これはVideoMAE-baseアーキテクチャに基づき、WLASLデータセットで微調整された動画動作認識モデルで、手話認識タスクに特化して最適化されており、評価セットで48.22%の正解率を達成しています。
これはVideoMAE-Baseアーキテクチャに基づいてWLASLデータセットで微調整された動画動作認識モデルです。200エポックの訓練を経て、評価セットで52.96%のトップ1精度と79.88%のトップ5精度を達成し、手話動作認識タスクに特化しています。
DevQuasar
これはNVIDIAがQwen3アーキテクチャに基づいて開発した32Bパラメータの報酬モデルで、強化学習における報酬評価と原則アライメントに特化しており、より安全で人間の価値観に沿ったAIシステムのトレーニングを支援します。
yueqis
このモデルは、Qwen2.5-Coder-32B-Instructをベースに、swe_only_sweagentデータセットで微調整された専用のコード生成モデルです。評価セットで0.1210の損失値を達成し、ソフトウェアエンジニアリング関連のタスクに特化して最適化されています。
EpistemeAI
metatune-gpt20bは、自己改善能力を持つ大規模言語モデルのプロトタイプで、自身に新しいデータを生成し、自身のパフォーマンスを評価し、改善指標に基づいてハイパーパラメータを調整することができます。このモデルは、博士後レベルの科学と数学の理解能力に優れており、コーディングタスクにも使用できます。
RedHatAI
これはunsloth/Mistral-Small-3.2-24B-Instruct-2506の量子化バージョンで、重みと活性化関数をFP4データ型に量子化することで、ディスク容量とGPUメモリの要件を削減し、同時にvLLM推論をサポートします。複数のタスクで評価され、非量子化モデルとの品質比較が行われました。
qthuan2604
これはvinai/bartpho-syllableをベースに微調整されたベトナム語テキスト誤り訂正モデルで、評価セットで文字正確率69.12%という良好な結果を得ており、ベトナム語テキストの自動誤り訂正タスクに特化しています。
ivan-kleshnin
これはjhu-clsp/mmBERT-smallモデルを微調整した分類器モデルで、評価セットで91.07%の正解率を達成し、主にテキスト分類タスクに使用されます。
yujieouo
G²RPOは、流モデルの嗜好アライメントに特化した新しい強化学習フレームワークで、粒度化報酬評価メカニズムにより生成品質を大幅に向上させます。
nineninesix
KaniTTSは高速で高忠実度のテキスト音声変換モデルで、リアルタイム対話型人工知能アプリケーション向けに最適化されています。このモデルは2段階の処理フローを採用し、大規模言語モデルと効率的なオーディオコーデックを組み合わせています。Nvidia RTX 5080で15秒の音声を生成する際の遅延は約1秒だけで、MOS自然度評価は4.3/5で、英語、中国語、日本語などの多言語をサポートしています。
これはmmBERT-smallアーキテクチャに基づいて微調整されたテキスト分類モデルで、メッセージタイプの分類タスクに特化しています。評価セットで93.94%の正解率を達成し、効率的なテキスト分類能力を持っています。
Sunbird
Sunflower-14Bは、Sunbird AIによって開発された多言語大規模言語モデルで、ウガンダの言語に特化して設計されています。このモデルはQwen 3-14Bアーキテクチャに基づいて構築され、31種類のウガンダ語と英語の翻訳およびテキスト生成タスクをサポートし、複数の評価で優れた成績を収めています。
エージェンティックレーダーは、エージェントシステムを分析・評価するセキュリティスキャナーで、開発者、研究者、セキュリティ専門家がエージェントシステムのワークフローを理解し、潜在的なホールを特定するのに役立ちます。
OpikはオープンソースのLLM評価フレームワークで、LLMアプリケーションのトレース、評価、監視をサポートし、開発者がより効率的で経済的なLLMシステムを構築するのを支援します。
Node.jsデバッガーMCPサーバーは、Chrome DevToolsプロトコルに基づく完全なデバッグ機能を提供します。ブレークポイントの設定、ステップ実行、変数のチェック、式の評価などが含まれます。
BloodHound - MCPは、モデルコンテキストプロトコル (MCP) サーバーとBloodHoundを統合したツールで、自然言語を通じてActive Directoryの攻撃パスを分析し、75以上の専用ツールを提供してADセキュリティ評価を行います。
PMATはゼロコンフィギュレーションのAIコードコンテキスト生成ツールで、コード品質分析、技術的負債評価、ミューテーションテスト、リポジトリ健全性評価、意味検索などの機能を提供し、17種類以上のプログラミング言語をサポートし、MCPプロトコルを通じてClaude CodeなどのAIアシスタントと統合することができます。
MCPBenchは、MCPサーバーのパフォーマンスを評価するためのフレームワークで、Web検索とデータベースクエリの2種類のタスクの評価をサポートし、ローカルおよびリモートのサーバーと互換性があり、主に精度、遅延、トークン消費を評価します。
タンパク質データベース(PDB)へのアクセスを提供するMCPサーバーで、構造検索、情報取得、ファイルダウンロード、品質評価機能をサポートしています。
MCPパートナーハブは、さまざまなISVパートナーが提供するMCP(モデルコンテキストプロトコル)サーバーを集中的に表示し、比較するためのリソースライブラリです。ユーザーが自分のニーズに合ったMCPサーバーを見つけ、評価し、選択するのを支援することを目的としています。
MCP NMAPサーバーは、AIアシスタントにネットワークスキャン機能を提供するプロトコルサーバーです。標準化されたインターフェースを通じて、AIモデルがNMAPを使用してネットワーク分析とセキュリティ評価を行うことができます。
BugBounty MCP Serverは包括的なセキュリティテストツールで、自然言語でLLMと対話し、92種以上の浸透テストツールを提供し、偵察、スキャン、脆弱性評価、Webアプリケーション、ネットワークセキュリティ、OSINT、脆弱性利用、レポート生成などの機能をカバーしています。
AlphaFold MCPサーバーは、タンパク質構造予測分析ツールを提供する総合的なプラットフォームで、構造検索、品質評価、バッチ処理、可視化統合などの機能をサポートしています。
ライトハウスMCPサーバーは、Google Lighthouseに基づくモデルコンテキストプロトコルサーバーで、包括的なウェブサイトのパフォーマンス監査と分析機能を提供します。パフォーマンススコア、アクセシビリティチェック、SEO分析、セキュリティ評価などを含みます。
線形回帰MCPプロジェクトは、Claudeとモデルコンテキストプロトコル(MCP)を使用したエンドツーエンドの機械学習ワークフローを示しており、データの前処理、モデルのトレーニング、評価が含まれます。
マンドリンMCPサーバーはAIアシスタント評価フレームワークで、Model Context Protocolを通じてClaudeやCursorなどのAIアシスタントにカスタム評価指標の作成、一括評点、パフォーマンス分析ツールを提供し、AIが自身のパフォーマンスを持続的に改善するのを支援します。
AIベースのNPMパッケージ分析MCPサーバーで、リアルタイムのセキュリティスキャン、依存関係分析、パフォーマンス評価などの機能を提供し、ClaudeとAnthropic AI技術を統合して、npmエコシステムの管理を最適化します。
VulniCheckはAI駆動のセキュリティスキャナで、PythonプロジェクトとGitHub倉庫に包括的なセキュリティ分析を提供しています。DockerベースのHTTP MCPサーバとして動作し、標準HTTPストリーミングをサポートし、依存チェック、鍵検出、Dockerファイル解析、AIリスク評価などのコンテナ化配置と包括的な脆弱性スキャン機能を提供する。
Gauntlet - Inceptは、K - 8の学生向けの高品質な教育コンテンツを生成するシステムで、記事と問題集の個別化生成と評価に特化しています。
DeepReはDenoベースのAI駆動のCLIツールで、Google Gemini APIを利用して深度調査報告書を自動生成します。複数回の反復調査と自動評価をサポートし、構造化されたMarkdown報告書を出力します。
これは、Scikit-learnモデルに標準化されたインターフェースを提供するMCPサーバーで、モデルのトレーニング、評価、データ前処理、および永続化などの機能をサポートしています。
MCPプロトコルに基づく多エージェントのディベートフレームワークで、コードレビューとディベート計画に使用されます。ClaudeやCodexなどの複数のAIエージェントを並列に実行してコードを評価し、確定的な評価システム(P0/P1/P2の深刻度分類)とプラットフォーム固有のルールを採用し、最終的に結果を統合してレビューレポートを生成します。
 Transformers多言語
Transformers多言語%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)