ByteDanceがマルチモーダル動画生成モデル「Seedance2.0」をテスト中。画像・動画・音声・テキスト処理を統合し、「監督級」の制御精度でコンテンツ制作の効率と品質を大幅向上。....
カーシューKling 2.6バージョンは音声と動作の制御の2つの機能を導入し、ネイティブなオーディオ生成を実現し、複雑なアクション処理の精度を向上させました。音声制御により、ビデオに合ったサウンドエフェクト、人の声、音楽を生成でき、カスタマイズ可能なボイスカスタマイズが可能です。
xAIはGrok音声プロキシAPIをリリースしました。1分あたり0.05ドルで、非常に高いコストパフォーマンスです。このモデルは音声推論ベンチマークテストで最優秀の結果を達成しており、最初の音声遅延は1秒未満で、競合製品より応答速度が約5倍速いです。中国語を含む数十の言語の自動検出と切り替えをサポートし、リアルタイムウェブ検索と推論機能を統合して、返信の質を向上させます。
快手可灵数字人2.0が全面リリースされ、ユーザーは3ステップで「話し演技する」デジタルヒューマンビデオを生成可能。新バージョンはキャラクター画像のアップロード、音声追加、表現の記述をサポートし、最大5分の動画を作成できます。旧版に比べ、表現力が大幅に向上し、手の動きと口の形を精密に制御できるようになりました。....
音声駆動の全身ビデオボイスオーバープラットフォームで、疎なフレーム制御と長シーケンスの画像からビデオへの生成をサポートします。
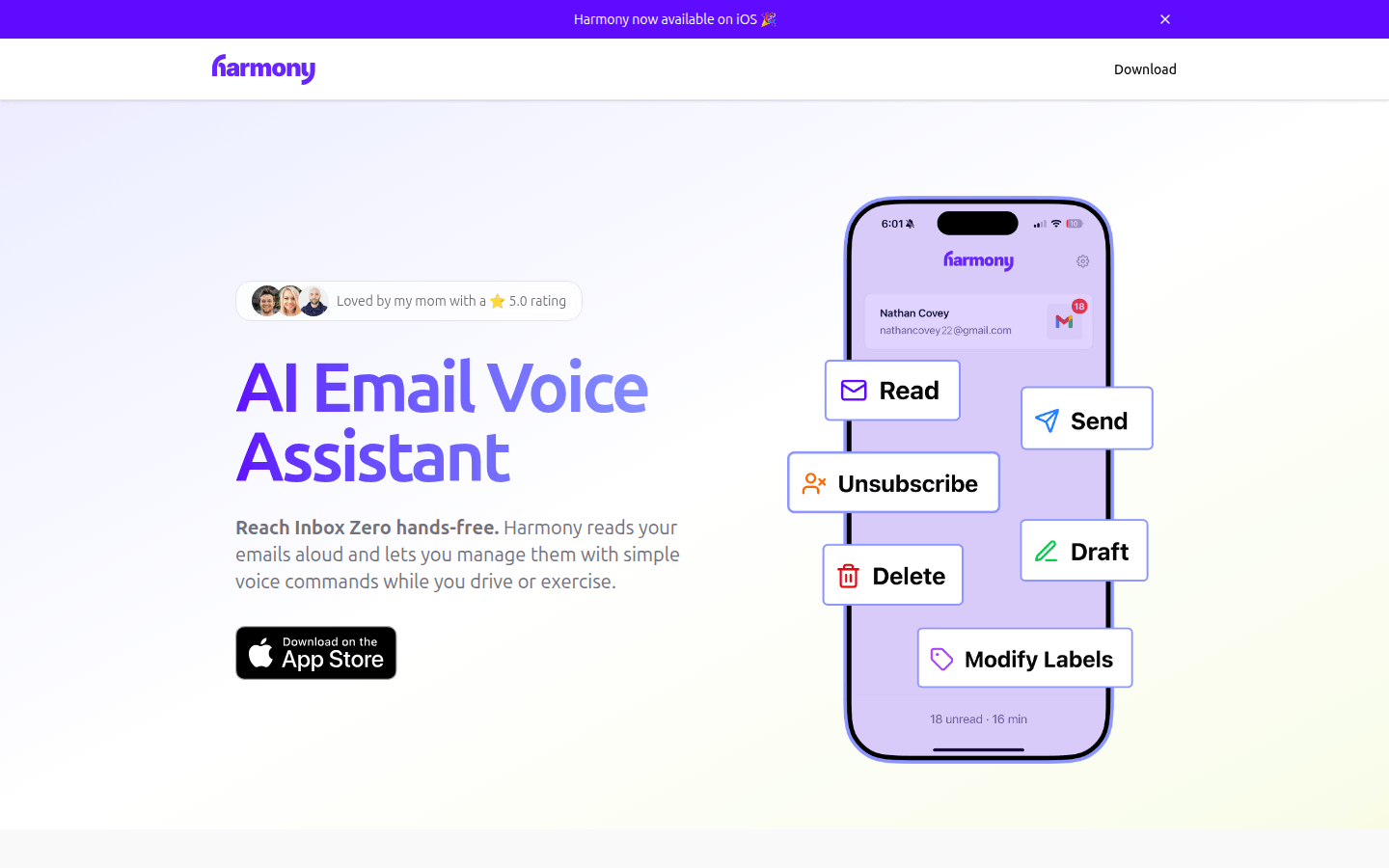
最高のAIアシスタントでGmailを管理し、デバイスに触れることなく音声コマンドで受信トレイを管理できます。
Zonos TTSは、多言語対応、感情制御、ゼロサンプルテキスト音声クローンに対応した高品質なAIテキスト音声変換技術です。
産業レベルで制御可能な、効率的なゼロショットテキスト音声変換システム
Google
$0.49
入力トークン/百万
$2.1
出力トークン/百万
1k
コンテキスト長
$17.5
Anthropic
$21
$105
200
Alibaba
$8
$240
52
-
$3.9
$15.2
64
$15.8
$12.7
Bytedance
$0.8
$2
128
32
Baidu
Tencent
Openai
$0.35
$2.8
400
Alissonerdx
HuMoは統一的で人を中心としたビデオ生成フレームワークで、テキスト、画像、音声などのマルチモーダル入力に基づいて、高品質、細粒度で制御可能な人間のビデオを生成できます。強力なテキストプロンプト追従、一貫した主体保持、同期した音声駆動型モーションをサポートします。
VeryAladeen
HuMoは人を中心としたビデオ生成フレームワークで、テキスト、画像、音声などのマルチモーダル入力を利用して、高品質、細粒度で制御可能な人間のビデオを生成することができます。テキストプロンプトの追従、主体の保持、音声駆動運動の同期をサポートします。
notmax123
Zonos-v0.1は、20万時間以上の多言語音声データを基にトレーニングされた、最先端のオープンソースのテキスト読み上げ(TTS)モデルです。表现力と品質は、トップレベルのTTSサプライヤーと匹敵します。ゼロショット音声クローン、多言語合成、および細かいオーディオ制御をサポートしています。
Lorenzob
Aurora-1.6BはDia-1.6Bをファインチューニングした多言語感情・歌唱音声合成モデルで、複数言語と感情制御をサポートし、ゼロショット音色クローン能力を備えています。
Dia-1.6Bをファインチューニングした多言語感情・歌唱音声合成モデル、音色クローンと感情制御をサポート
Emova-ollm
EMOVAはエンドツーエンドの全モーダル対応大規模言語モデルで、視覚、聴覚、音声機能をサポートし、感情制御可能なテキストと音声応答を生成できます。
Prince-1
Llamaアーキテクチャに基づく音声大規模モデルで、高品質なテキスト読み上げを設計し、感情制御とリアルタイムストリーミングをサポート
2121-8
llm-jp/llm-jp-3-150m-instruct3をベースに訓練した日本語TTS音声合成システムで、プロンプトによる音質制御が可能
nari-labs
DiaはNari Labsが開発した16億パラメータのテキスト音声合成モデルで、テキストから高度にリアルな対話を直接生成でき、感情やイントネーションの制御をサポートし、非言語コミュニケーション内容も生成可能です。
HKUSTAudio
AudioXは任意のコンテンツから音声や音楽を生成できる統一拡散トランスフォーマーモデルです。高品質な汎用音声と音楽作品を生成し、柔軟な自然言語制御を提供し、複数のモダリティ入力をシームレスに処理できます。
YaTharThShaRma999
Llamaアーキテクチャに基づく高品質なテキスト読み上げモデル、感情制御と音声クローニングをサポート
chutesai
Llamaアーキテクチャに基づく高品質なテキスト音声変換モデル、感情制御と音色クローニングをサポート
ajd12342
テキストスタイルプロンプトで豊かな音声スタイルを制御できるテキスト読み上げモデル
Parler-TTS Mini v1をファインチューニングしたテキスト音声変換モデルで、スタイルプロンプトによる音声出力制御をサポート
firstpixel
F5-TTSベースのブラジルポルトガル語テキスト音声変換モデル、感情タグと話者特徴制御をサポート
EMOVA音声トークナイザーは、中英両言語に対応した離散音声トークナイザーで、意味-音響デカップリング設計を採用し、柔軟な音声スタイル制御をサポートします。
mradovic38
wav2vec2に基づくセルビア語のスマートホーム音声コマンド認識モデルで、7種類の制御コマンドを認識できます。
parler-tts
Parler-TTS Mini v1.1は軽量型のテキスト音声変換モデルで、45,000時間のオーディオデータを基に訓練され、高品質で自然な流れの良い音声を生成できます。その特性は簡単なテキストプロンプトで制御できます。
軽量級のテキスト音声変換モデルで、4.5万時間の音声データを基に訓練され、テキストプロンプトで音声特性を制御できます。
22億パラメータを持つテキスト音声変換モデル、4.5万時間の音声データで訓練され、テキストプロンプトによる音声特徴の制御をサポート
SystemPrompt Coding Agentは、オープンソースプロジェクトで、ローカルワークステーションをMCPプロトコルでリモート制御可能なAIプログラミングアシスタントに変えます。音声コマンドとモバイル端末での操作をサポートし、異なる場所でのプログラミング管理を実現します。
TeamSpeak MCPは、Model Context Protocolに基づくサーバー制御ツールで、ClaudeなどのAIモデルがTeamSpeak音声サーバーを管理できるように設計されています。ユーザー管理、チャンネル制御、権限設定などの包括的な操作をカバーする39種類の機能ツールを提供し、複数のデプロイ方法(PyPI/Docker/ローカル)をサポートして、TeamSpeakの自動管理を実現します。
ClaudeなどのLLMインターフェイスを通じてフィリップスHueスマートライトを制御するMCPサーバープロジェクト
MacOS上でアプリを実行するためのMCPサーバーアプリ
TeamSpeak MCPは、Model Context Protocolに基づくサービスで、AIモデル(Claudeなど)を通じてTeamSpeakサーバーを制御し、包括的なチャンネル管理、ユーザー権限制御、音声調整などの機能を提供します。
MCPフレームワークに基づく多機能なTTSサーバーで、KokoroのローカルTTSとOpenAIのクラウドTTSエンジンを統合し、リアルタイムオーディオストリーム、音声カスタマイズ、再生制御をサポートしています。
統一インターフェースを提供してSpotifyの再生を制御するメディア制御プロトコルサーバーで、REST API、AIアシスタント、および音声制御をサポートします。
Home Assistant MCP統合スイートは、複数のMCPサーバー(Microsoft 365、BookStack、Lokiなど)を完全に接続し、音声制御を実現し、統一された拡張可能なスマートホーム管理インターフェイスを提供します。
IntelliGlowはMCPプロトコルに基づくスマート照明システムで、AIアシスタントによって実際のスマート電球を制御し、音声コマンド、AI推論、および直接的なハードウェア制御をサポートし、自然言語対話とスマートな照明管理を実現します。
Windows TTS MCPサーバーは、PowerShellベースのテキストを音声に変換するサービスで、Claude Desktopに安定した効率的なTTS機能を提供し、音声制御、速度調整、緊急ミュートなどの操作をサポートしています。
IntelliGlowは、MCPプロトコルに基づくAIスマート照明制御システムで、UDPネットワークを介して実際のスマート電球を直接制御し、音声コマンド、AI推論、ハードウェア制御をサポートし、自然言語対話とスマートホームをシームレスに接続します。
 Transformers英語
Transformers英語%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)