大規模AIモデル時代における計算需要の急増に対し、中小企業や研究機関はGPU調達難題に直面。従来のクラウドサービスは複雑で柔軟性に欠け、ローカル導入はコストと保守面で課題がある。経済的で柔軟な計算リソース解決策が求められる。....
NVIDIAはグーグルのAIの進展に対して反応し、自身がAIインフラストラクチャ分野での中心的な地位を強調した。それは、すべての主要なAIモデルを実行でき、クラウドからエッジコンピューティングまでの全プラットフォームをカバーする唯一の存在であり、業界より約1世代先行していると述べた。ホアン・レンズン氏は、NVIDIAの汎用GPUがパフォーマンス、柔軟性および置き換え可能性において専用AIチップよりも優れていると指摘した。
LambdaがEラウンドで15億ドル超を調達。資金はAIファクトリー建設に投入し、GPUサービスを提供。CoreWeaveなどと競争しながら市場シェアを拡大中。2025年2月のDラウンド(4.8億ドル)に続く資金調達。....
OpenAIがAWSと3800億ドル・7年間の契約を締結。数十万台のNVIDIA GPUを活用し、AIインフラを強化。従来のクラウドサービスを超える戦略的提携。....
GPU演算クラウドサービスに特化した、効率的な演算ソリューションを提供しています。
AI向けに設計されたGPUクラウドプラットフォーム。高性能インフラストラクチャと24時間365日のサポートを提供します。
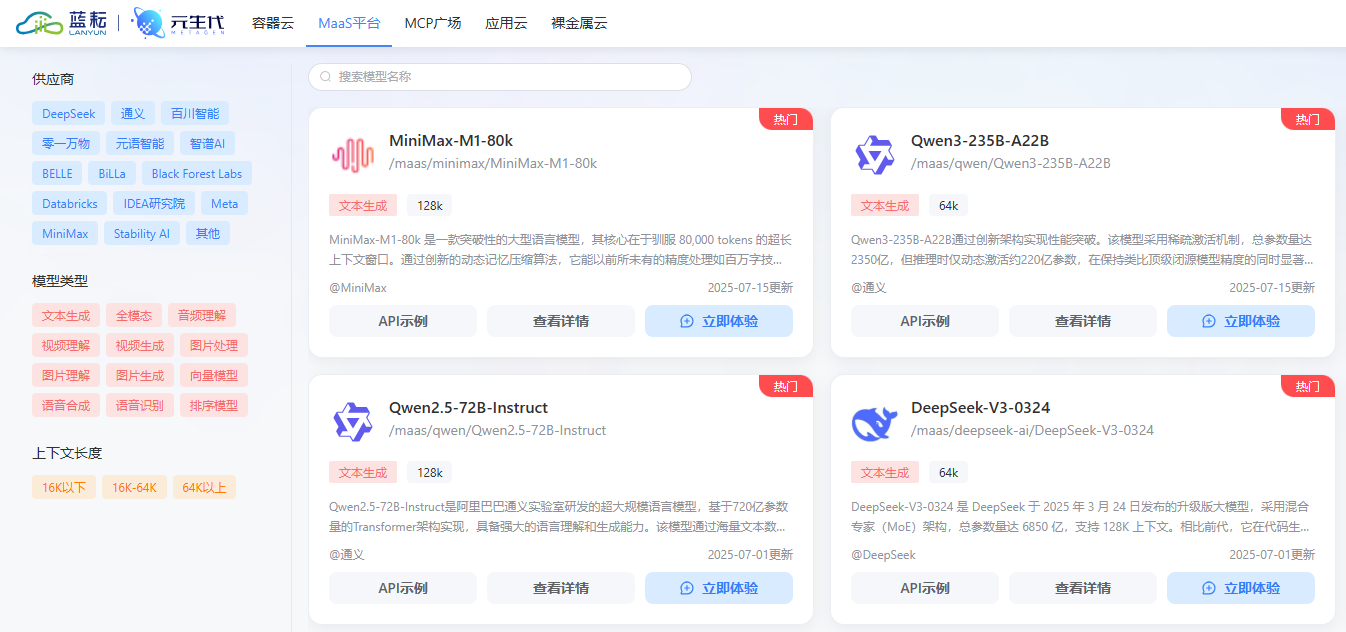
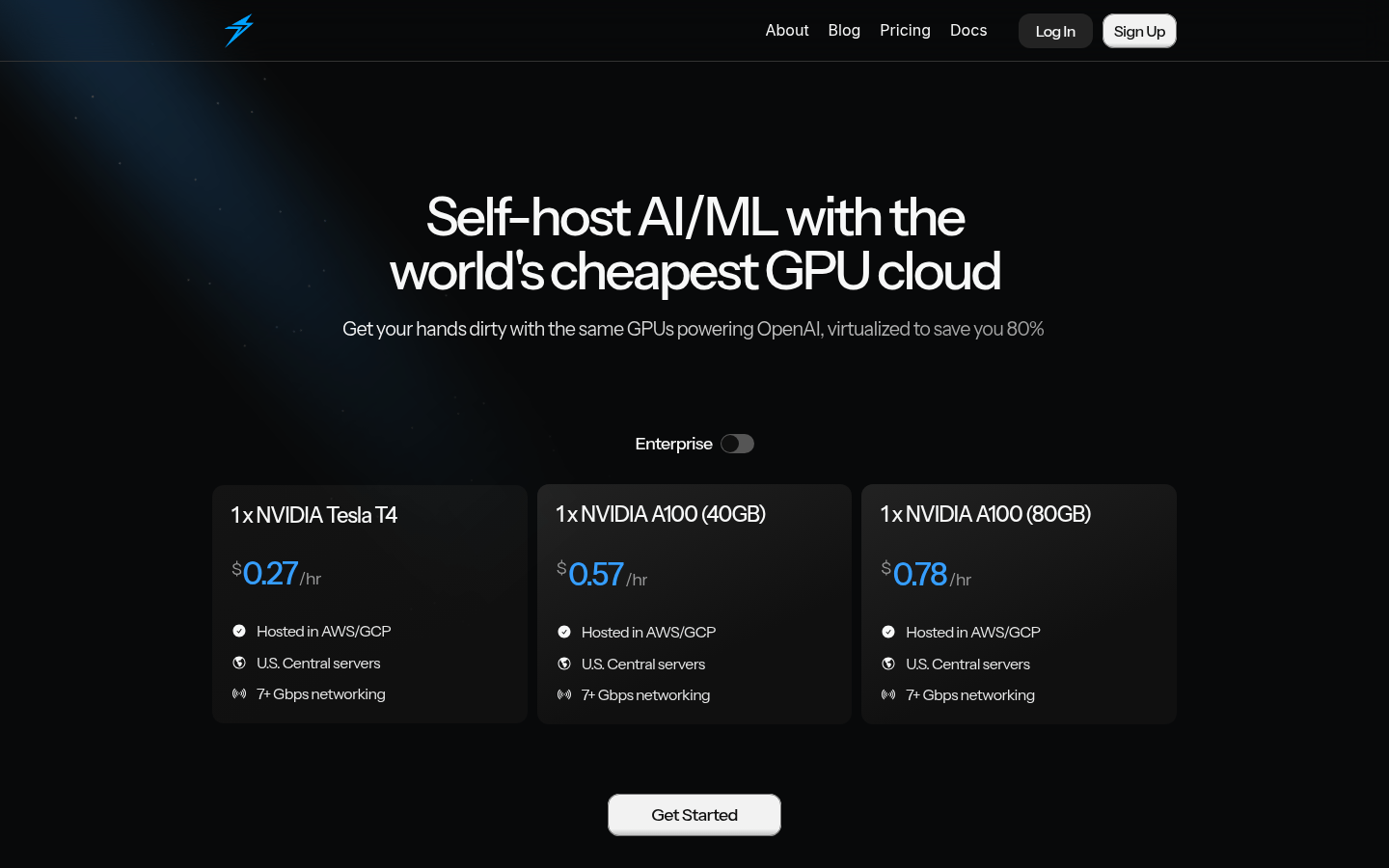
世界最安値のGPUクラウドサービスを提供し、自己ホスト型AI/ML開発を支援します。
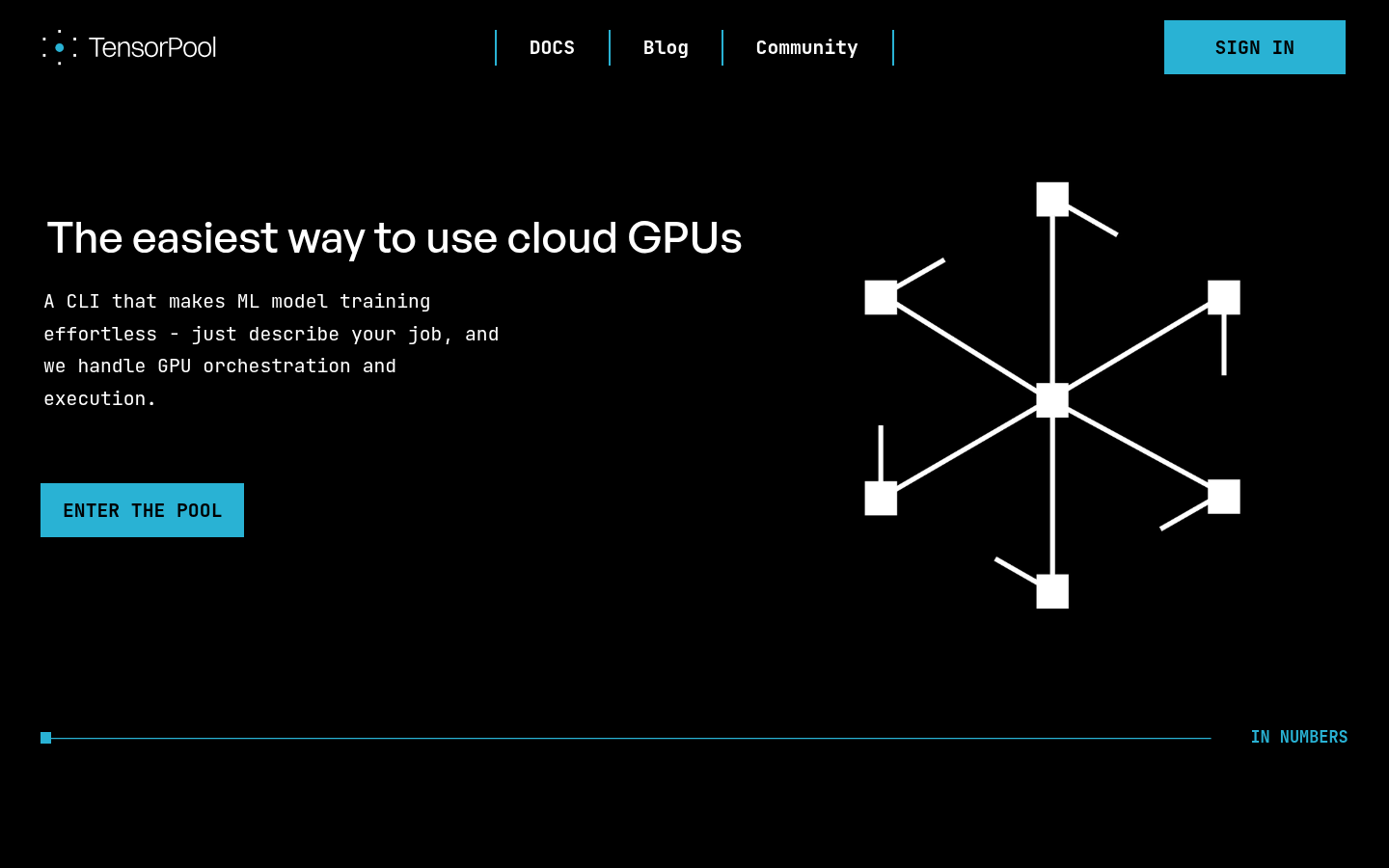
TensorPoolは、機械学習モデルのトレーニングを簡素化するクラウドGPUプラットフォームです。
Openai
$2.8
入力トークン/百万
$11.2
出力トークン/百万
1k
コンテキスト長
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
Google
$0.7
$7
$35
$2.1
$17.5
$21
Alibaba
$6
$24
256
$4
$16
Bytedance
$1.2
$3.6
4
Moonshot
$0.8
$2
128
$0.15
$1.5
nvidia
NVIDIA Qwen3-14B FP4モデルは、アリババクラウドのQwen3-14Bモデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用した自己回帰型言語モデルです。このモデルはTensorRT Model Optimizerを使用して量子化され、重みと活性化をFP4データ型に量子化することで、NVIDIA GPU加速システム上で高効率な推論を実現します。
NVIDIA Qwen3-30B-A3B FP4モデルは、アリババクラウドのQwen3-30B-A3Bモデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用し、自己回帰型言語モデルです。このモデルはTensorRT Model Optimizerを使用してFP4量子化を行い、各パラメータのビット数を16ビットから4ビットに減らし、ディスクサイズとGPUメモリ要件を約3.3倍削減しながら、高いパフォーマンスを維持します。
NVIDIA Qwen3-235B-A22B FP4モデルは、アリクラウドのQwen3-235B-A22Bモデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用した自己回帰型言語モデルです。このモデルは、FP4量子化技術を用いてパラメータを16ビットから4ビットに削減し、ディスク容量とGPUメモリの要件を約3.3倍削減すると同時に、高い精度と性能を維持します。
NVIDIA Qwen3-235B-A22B FP8モデルは、アリクラウドのQwen3-235B-A22Bモデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用した自己回帰型言語モデルです。このモデルは、FP8量子化技術により、ディスク容量とGPUメモリの要件を大幅に削減しながら、高い推論精度を維持し、さまざまなAIアプリケーションシナリオに適しています。
Hyperbolic GPU MCPサーバーはHyperbolic GPUクラウドとやり取りするツールで、プロキシとLLMがGPUを表示、レンタルし、SSH接続を通じてGPU加速されたワークロードを実行できます。
双曲GPU MCPサーバーは、Node.jsベースのツールで、APIを介して双曲クラウドプラットフォーム上のGPUリソースを管理およびレンタルできます。利用可能なGPUの表示、インスタンスのレンタル、SSH接続、およびGPUワークロードの実行などの機能が含まれています。
 Safetensors
Safetensors%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)