NVIDIAはOpenAI向けに特化したAIプロセッサを開発し、推論性能を大幅に向上させる計画です。これは汎用GPUサプライヤーからカスタムシステムアーキテクトへの戦略的転換を示しています。....
Metaは数十億ドル規模でGoogleの自社開発TPUをリースし、AIモデル開発に活用。NVIDIAのAIチップ市場支配に挑む。従来はNVIDIA GPUに依存していたが、最近ではNVIDIAとAMDのGPU数百万個購入も発表。....
NVIDIAの最新決算で、四半期売上高は680億ドル(前年比73%増)と過去最高を記録。データセンター事業が620億ドル(全体の9割超)を貢献し、年間売上高は2150億ドルに達した。初めて開示された内訳では、GPU関連の計算事業が510億ドルを占める。....
最近、NVIDIAはメタと長期間にわたる世代を超えた戦略的パートナーシップを発表しました。今回の合意に基づき、メタはその大規模なAIデータセンター内に数百万台のNVIDIAブラックウェルGPU、および知能体AI推論向けに特別に設計された次世代のルビンアーキテクチャGPUを導入し、AI計算基盤を強化する予定です。
NVIDIA? GeForce RTX? 5090は、これまでにないほどパワフルなGeForce GPUであり、ゲーマーとクリエイターに革新的な能力をもたらします。
NVIDIA GPU上でLLM推論を加速する革新的技術
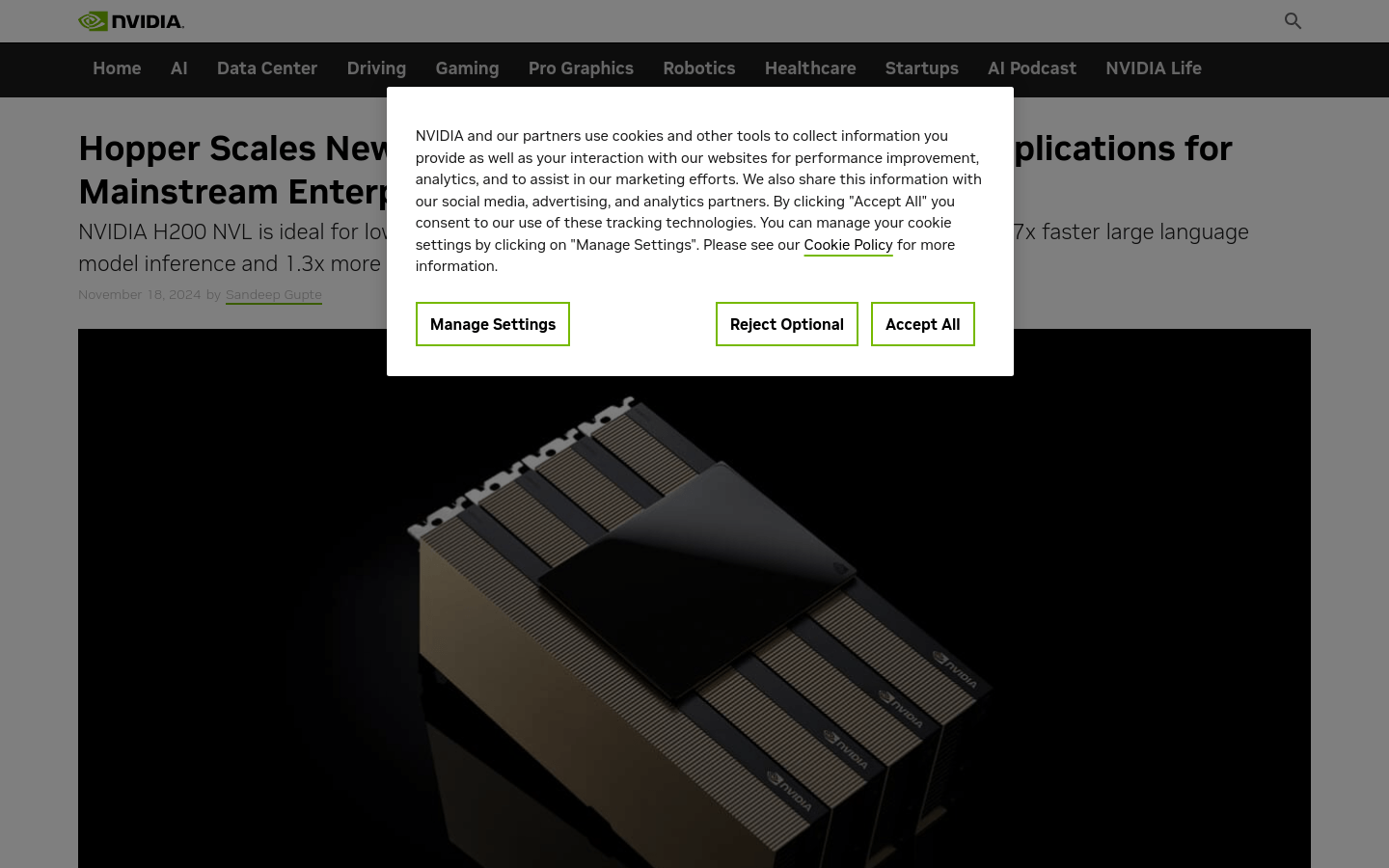
AIおよびHPCアプリケーションを加速するNVIDIA H200 NVL GPU
NVIDIAディープラーニングインスティテュート(DLI)のティーチングキットは、教育者がGPUを活用した授業を展開するための支援ツールです。
Openai
$2.8
入力トークン/百万
$11.2
出力トークン/百万
1k
コンテキスト長
-
Bytedance
$0.8
$2
128
Alibaba
$0.4
$8.75
$70
400
$1.75
$14
$0.35
64
$0.63
$3.15
131
Huawei
32
$1.8
$5.4
16
Tencent
$17.5
$56
$0.7
$2.4
$9.6
Google
$0.14
$0.28
Qwen
Qwen3-VL-2B-ThinkingはQwenシリーズの中で最も強力なビジュアル言語モデルの1つで、GGUF形式の重みを使用し、CPU、NVIDIA GPU、Apple Siliconなどのデバイスで効率的な推論をサポートします。このモデルは、優れたマルチモーダル理解と推論能力を備え、特にビジュアル感知、空間理解、エージェントインタラクション機能が強化されています。
TheStageAI
TheWhisper-Large-V3はOpenAI Whisper Large V3モデルの高性能ファインチューニング版で、TheStage AIによって多プラットフォーム(NVIDIA GPUとApple Silicon)のリアルタイム、低遅延、低消費電力の音声テキスト変換推論用に最適化されています。
RedHatAI
これはNVIDIA-Nemotron-Nano-9B-v2モデルのFP8動的量子化バージョンで、重みと活性化をFP8データ型に量子化することで最適化を実現し、ディスクサイズとGPUメモリ要件を約50%削減し、同時に優れたテキスト生成性能を維持します。
nvidia
NVIDIA Qwen2.5-VL-7B-Instruct-FP4は、アリババのQwen2.5-VL-7B-Instructモデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用し、マルチモーダル入力(テキストと画像)をサポートし、さまざまなAIアプリケーションシナリオに適しています。このモデルはTensorRT Model Optimizerを使用してFP4量子化され、NVIDIA GPU上で効率的な推論性能を提供します。
NVIDIA Qwen3-14B FP4モデルは、アリババのQwen3-14Bモデルの量子化バージョンで、FP4データ型を用いて最適化され、TensorRT-LLMによる効率的な推論が可能です。このモデルはNVIDIA GPU加速システム向けに設計されており、AIエージェントシステム、チャットボット、RAGシステムなどの様々なAIアプリケーションシーンに適しており、世界中での商用および非商用利用がサポートされています。
NVIDIA Qwen3-14B FP4モデルは、アリババクラウドのQwen3-14Bモデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用した自己回帰型言語モデルです。このモデルはTensorRT Model Optimizerを使用して量子化され、重みと活性化をFP4データ型に量子化することで、NVIDIA GPU加速システム上で高効率な推論を実現します。
NVIDIA Qwen3-8B FP8は、アリババのQwen3-8Bモデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用し、自己回帰型言語モデルに属します。このモデルはFP8量子化技術によって最適化され、NVIDIA GPU上で効率的な推論を実現でき、商用および非商用用途に対応しています。
jet-ai
Jet-Nemotron-4BはNVIDIAが開発した高効率混合アーキテクチャの言語モデルで、事後ニューラルアーキテクチャサーチとJetBlock線形注意力モジュールという2つの核心的な革新技術に基づいて構築されています。性能面では、Qwen3、Qwen2.5、Gemma3、Llama3.2などのオープンソースモデルを上回り、H100 GPU上で最大53.6倍の生成スループットの高速化を実現しています。
ESM - 2はNVIDIAがTransformerEngineを基に最適化したタンパク質言語モデルで、アミノ酸配列からタンパク質の3D構造を予測できます。このモデルはマスク言語モデリングの目標で訓練され、NVIDIA GPU上でより高速な訓練と推論速度を持ちます。
NVIDIA DeepSeek R1 FP4 v2は、DeepSeek AIのDeepSeek R1モデルに基づいてFP4量子化を行ったテキスト生成モデルで、最適化されたTransformerアーキテクチャを採用しており、商用および非商用用途に使用できます。このモデルはTensorRT Model Optimizerを通じて量子化され、FP8バージョンと比較してディスク容量とGPUメモリの要件が大幅に削減されています。
NVIDIA DeepSeek-R1-0528-FP4 v2はDeepSeek R1 0528モデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用し、自己回帰型言語モデルです。FP4量子化最適化により、ディスク容量とGPUメモリの要求量を削減し、同時に高い推論効率を維持します。
NVIDIA Qwen3-30B-A3B FP4モデルは、アリババクラウドのQwen3-30B-A3Bモデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用し、自己回帰型言語モデルです。このモデルはTensorRT Model Optimizerを使用してFP4量子化を行い、各パラメータのビット数を16ビットから4ビットに減らし、ディスクサイズとGPUメモリ要件を約3.3倍削減しながら、高いパフォーマンスを維持します。
NVIDIA Qwen3-235B-A22B FP4モデルは、アリクラウドのQwen3-235B-A22Bモデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用した自己回帰型言語モデルです。このモデルは、FP4量子化技術を用いてパラメータを16ビットから4ビットに削減し、ディスク容量とGPUメモリの要件を約3.3倍削減すると同時に、高い精度と性能を維持します。
NVIDIA Qwen3-235B-A22B FP8モデルは、アリクラウドのQwen3-235B-A22Bモデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用した自己回帰型言語モデルです。このモデルは、FP8量子化技術により、ディスク容量とGPUメモリの要件を大幅に削減しながら、高い推論精度を維持し、さまざまなAIアプリケーションシナリオに適しています。
NVIDIA DeepSeek-R1-0528-FP4はDeepSeek R1 0528モデルの量子化バージョンで、最適化されたTransformerアーキテクチャを採用し、重みと活性化値をFP4データ型に量子化することで、ディスク容量とGPUメモリの要件を大幅に削減し、TensorRT-LLM推論エンジンをサポートして効率的な推論を実現します。
NVIDIA DeepSeek R1 FP4モデルは、DeepSeek AIのDeepSeek R1モデルの量子化バージョンで、最適化されたTransformerアーキテクチャを使用した自己回帰型言語モデルです。このモデルは、FP4量子化技術を通じてパラメータのビット数を8ビットから4ビットに減らし、ディスクサイズとGPUメモリ要件を約1.6倍削減すると同時に、高い精度性能を維持します。
microsoft
Phi-3 Smallは70億パラメータの軽量級最先端オープンソースモデルで、NVIDIA GPU向けに最適化されたONNXバージョンであり、8Kの文脈長をサポートし、強力な推論能力を備えています。
 Safetensors
Safetensors%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)