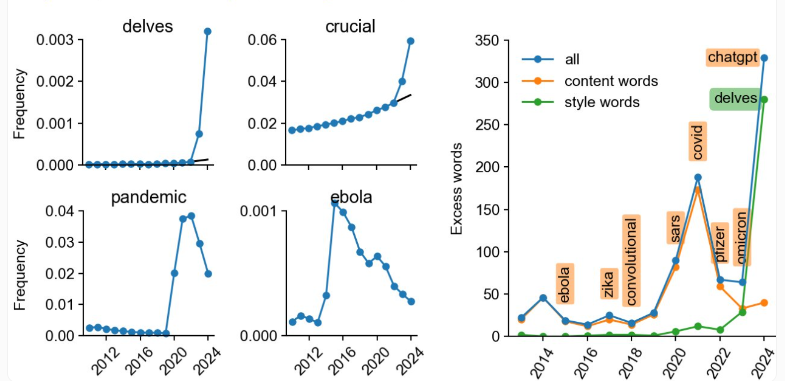
Nature誌の研究によると、2024年の生物医学論文ではAI執筆の痕跡が顕著。PubMedの150万件の要約のうち、20万件以上にAI特徴語(華麗な形容詞など)が含まれ、非英語圏(中国・韓国15%)や低ランク誌(24%)で使用率が高い。著者はAI語彙を回避しつつあり、研究チームは1400万件の分析から学術文体への影響を指摘。規範整備の必要性を訴えている。....
1400万件のPubMed抄録を分析した結果、ChatGPT登場以降、AIテキストジェネレーターが少なくとも10%の科学論文抄録に影響を与えていることが判明しました。一部の分野や国では、この割合はさらに高くなっています。
Google検索、arXiv、Scholar、PubMed、IEEEなどから、AIやその他の研究論文の実装コードを直接取得できます。
OpenMed
これは疾病実体識別に特化した生物医学の命名実体識別モデルで、PubMedデータを基に訓練され、NCBIデータセットから疾病実体を正確に識別でき、生物医学分野の研究や臨床応用に強力な支援を提供します。
lokeshch19
PubMedデータセットを基に訓練された文変換器モデルで、複数の埋め込み次元をサポートし、生物医学テキスト処理に適しています。
nyamuda
このモデルはt5-smallをファインチューニングしたバージョンで、PubMedデータセットを使用して科学・医学テキストを要約するために最適化されています。
ThorBaller
これはPubMedQAデータセットでファインチューニングされたLlama3モデルで、医学分野のQ&Aタスクに特化しています。
ikim-uk-essen
BiomedCLIPはマイクロソフトが開発した生物医学ビジュアル言語処理モデルで、PubMedBERTとViTアーキテクチャに基づき、生物医学分野向けに設計されています。
BioMistral
BioMistralはMistralアーキテクチャを基盤とし、PubMed Centralのオープンアクセステキストデータを用いて追加事前学習を行った医療分野向けオープンソース大規模言語モデルです
Mistralアーキテクチャに基づく医療分野のオープンソース大規模言語モデル、PubMed Centralテキストで継続事前学習
BioMistralはMistralアーキテクチャを基に、医学分野向けに最適化されたオープンソース大規模言語モデルで、PubMed Centralのオープンアクセステキストデータを用いて追加事前学習を行い、多言語医学質問応答タスクをサポートします。
BioMistralはMistralアーキテクチャを基盤とし、PubMed Centralのオープンアクセステキストデータを用いて継続事前学習を行った医療分野向けオープンソースモデルスイートです。
mreisman
T5-smallをファインチューニングしたPubMed文献要約生成モデルで、医学文献の簡潔な要約を自動生成します。
andorei
GEBERTはPubMedBERTで事前学習された生物医学エンティティリンキングモデルで、GATグラフエンコーダーによりUMLS概念グラフの表現学習を強化
NotXia
PubMedBERT事前学習モデルに基づき、MS^2データセットでファインチューニングされた抽出型要約モデルで、生物医学分野のテキスト要約タスクに特化しています。
wisdomik
Quilt-1M病理動画データセットで訓練されたViT-B/16視覚エンコーダーとPubMedBERTテキストエンコーダーのマルチモーダル基盤モデル
flaviagiammarino
PubMedCLIPは医療分野向けにファインチューニングされたCLIPモデルのバージョンで、医学画像と関連テキストの処理に特化しています。
biu-nlp
このモデルは生物医学文献の要約文をベクトル空間にマッピングし、文の類似度を計算するために設計されており、特にPubMed文献向けに訓練されています。
oracat
PubMedBERTをファインチューニングしたarXiv論文分類モデルで、論文タイトルと要約に基づいてarXiv分類用語を予測します。
malteos
PubMedNCLは、PubMedBERTをベースに開発された事前訓練済みの生物医学論文ドキュメント表現言語モデルで、引用近傍比較学習によってファインチューニングされています。
pruas
これはPubMedBERTをファインチューニングした固有表現認識モデルで、バイオメディカルテキスト中の遺伝子とタンパク質エンティティを識別するために特別に設計されています。
microsoft
BiomedBERTはPubMedの抄録テキストを基にゼロから事前学習された生物医学分野向け大規模言語モデルで、生物医学自然言語処理タスクの性能向上に特化しています。
andkelly21
t5-smallモデルをPubMed要約データセットでファインチューニングしたテキスト要約生成モデル
Suppr超能文献のMCPサービスは、文書翻訳と中国語の意味検索によるPubMed文献検索機能を提供し、多様なファイル形式と言語の相互翻訳をサポートし、ClaudeなどのAIアシスタントに統合して使用できます。
モデルコンテキストプロトコル(MCP)に基づく学術論文検索とダウンロードサーバーで、arXiv、Semantic Scholar、PubMed、RePEcなど複数の学術プラットフォームをサポートし、Claude DesktopなどのLLMツールに論文検索、ダウンロード、閲覧機能を提供します。
arXiv、PubMed、bioRxivなどの複数の学術プラットフォームから論文を検索してダウンロードするためのMCPサーバーで、標準化された検索と取得ツールをサポートし、AI駆動の研究ワークフローを容易にします。
専門のPubMed医学文献分析MCPサーバーで、文献検索、トピック分析、トレンド追跡、論文投稿統計機能を提供し、研究者が医学研究の動向を迅速に把握するのを支援します。
PubMed文献検索MCPサービス
PubMed強化検索MCPサーバーは、高度な学術論文検索と医学主題語検索機能を提供します。
このプロジェクトには、複数のMCP(モデルコンテキストプロトコル)サーバーの実装が含まれており、天気検索、LinkedInプロファイルの取得、PubMed記事の検索機能をカバーし、MCPクライアントとの統合をサポートしています。
これは医療分野に特化したMCPサーバーの集合で、PubMed文献検索、医学プレプリントアクセス、FHIRデータのやり取り、DICOM医学画像処理、タンパク質構造解析、医学計算ツール、医学教育リソースの統合など、さまざまな医療関連のMCPサービスの実装をカバーしています。
このプロジェクトには複数のMCPサーバー実装が含まれており、天気、LinkedInプロフィール、PubMed記事の検索サービスを提供します。
Claude Desktop用に特別に設計された医学コンテンツサーバーで、PubMedとNCBIのリソースを統合し、医学教育コンテンツの検索、取得、分析機能を提供します。
Paper Search MCPは、MCPプロトコルに基づく学術論文検索とダウンロードサーバーで、arXiv、PubMed、bioRxivなどの複数のプラットフォームから論文を検索し、標準化された出力形式を提供し、Claudeなどの大規模言語モデルとシームレスに統合できます。
パブクロールはMCPサーバーで、LLMクライアントにPubMed文献検索、FDA医薬品ラベル、英国医薬品データ、ClinicalTrials.govの臨床試験のアクセス機能を提供し、文献からラベル、試験までの包括的な医薬情報照会を実現します。
Model Content Protocolに基づくPubMed学術論文検索サービス
PubMedデータベースに基づく高度な医学文献研究ツールで、学術医学論文の検索、分析、取得機能を提供します。文献検索、詳細なメタデータの取得、引用の生成、研究者の統計などの機能が含まれています。
Suppr超能文献はAI駆動の文書翻訳と中国語のPubMed文献検索サービスを提供し、複数の文書形式の翻訳とスマートな文献検索をサポートします。
このプロジェクトは、MCPプロトコルを通じてPubMed文献を検索するサービスを実装しており、ノート保存システムと要約生成機能を備えています。
医学部学生や研究者向けに開発されたPubMed文献分析MCPサーバーで、文献検索、ホットトピック分析、トレンド追跡、論文発表統計などの機能を提供します。
Google Cloud Healthcare APIをベースとしたMCPサーバーで、FHIRリソースとのやり取りを行う医療ツールを提供し、Firebase認証をサポートするSmartonFHIRゲートウェイを通じたデータアクセスを可能にし、PubMedなどの医学研究APIを統合しています。
PubMed MCPサーバーは、Model Context Protocolに基づくインターフェースサービスで、AIエージェントと研究ツールに、PubMedの生物医学文献データベースへの全面的なアクセス機能を提供します。文献検索、メタデータ取得、引用分析、研究計画生成、データ可視化などの機能をサポートし、NCBI E-utilities APIを通じて効率的な統合を実現します。
Entrez APIを通じてPubMedの記事にアクセスするMCPサーバーで、キーワード検索、要約取得、オープンアクセス全文ダウンロードをサポートします。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)