Unsloth AIはオープンソースでコード不要な視覚ツールであるUnsloth Studioをリリースし、大規模言語モデルのファインチューニングプロセスを簡素化し、開発のハードルを下げることを目的としています。このツールはカスタムの逆伝播カーネルを使用して、トレーニング速度を倍にし、GPUメモリを70%節約します。複雑な環境設定や高価なハードウェアコストなしで利用可能です。
NVIDIAが大規模言語モデルのファインチューニングガイドを公開。消費者のデバイスでも効率的にカスタマイズ可能に。Unslothフレームワークを活用し、NVIDIA GPU向けに最適化されたプロフェッショナルな微調整手法を解説。....
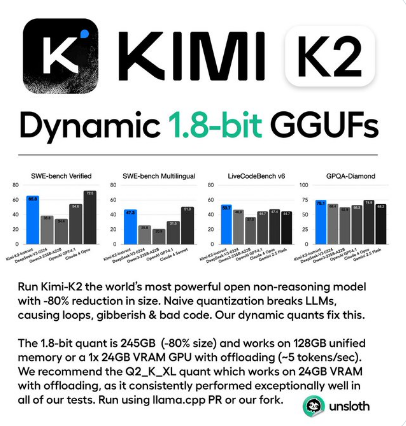
Unsloth AIはMoonshot AIのKimi K2モデルを1.8bitに量子化し、モデルサイズを1.1TBから245GBに80%削減。1兆パラメータのオープンソースモデルで、512GBメモリのM3Ultraで動作可能。GPT-4.1と競合する性能を維持しつつ、中小企業向けAIソリューションとして教育・医療分野での活用が期待。....
大規模言語モデル(LLM)の高速トレーニングとファインチューニングを実現
RiosWesley
ブラジル範囲ルーティングモデルは、Gemma 3 270Mをベースにした微調整されたミニマルな大規模言語モデルで、ブラジルの配達サービスシステム用に設計されており、非常に高速で軽量な意図分類器(ルーター)として機能します。このモデルはUnslothを使用してトレーニングされ、GGUF形式に変換されています。
TeichAI
このモデルはQwen3-4B-Thinking-2507をベースに、GPT-5-Codexの1000個のサンプルで微調整され、テキスト生成タスクに特化しており、Unsloth技術を使用してトレーニング速度を2倍に向上させています。
Ali-Yaser
このモデルはmeta-llama/Llama-3.3-70B-Instructをベースに微調整したバージョンで、mlabonne/FineTome-100kデータセットを使用してトレーニングされ、100kトークンのデータを含んでいます。モデルはUnslothとHuggingface TRLライブラリを使用して微調整され、英語の言語処理をサポートしています。
unsloth
aquif-3.5シリーズは2025年11月3日にリリースされた傑作で、PlusとMaxの2つのバージョンがあり、高度な推論能力とこれまでにない100万トークンのコンテキストウィンドウを提供し、それぞれのカテゴリで最先端の性能を実現しています。
Qwen3-Coder-REAP-363B-A35Bは、REAP手法を用いてQwen3-Coder-480B-A35B-Instructを25%のエキスパート剪定を行った疎な混合エキスパートモデルです。元のモデルに近い性能を維持しながら、パラメータ規模とメモリ要件を大幅に削減し、特にリソースが制限されたコード生成とスマートコーディングのシナリオに適しています。
Qwen3-VLは通義シリーズの中で最も強力なビジュアル言語モデルで、卓越したテキスト理解と生成能力、深いビジュアル感知と推論能力、長いコンテキストのサポート、強力な空間とビデオ動的理解能力、そして優れたインテリジェントエージェント対話能力を備えています。
Qwen3-VL-32B-ThinkingはQwenシリーズで最も強力なビジュアル言語モデルで、卓越したテキスト理解と生成能力、深いビジュアル感知と推論能力、長文脈処理、空間および動画の動的理解能力、そして優れたエージェント対話能力を備えています。
Qwen3-VL-8B-Thinkingは通義千問シリーズで最も強力なビジュアル言語モデルで、卓越したテキスト理解と生成能力、深いビジュアル認知と推論能力、長いコンテキストサポート、強力な空間とビデオ動的理解能力、そして優れたエージェント対話能力を備えています。
Qwen3-VLは通義シリーズの中で最も強力な視覚言語モデルで、卓越したテキスト理解と生成能力、深い視覚知覚と推論能力、長いコンテキストのサポート、強力な空間およびビデオ動的理解能力、そして優れたエージェント対話能力を備えています。
Qwen3-VLは通義シリーズで最も強力なビジュアル言語モデルで、テキスト理解と生成、ビジュアル認知と推論、コンテキスト長、空間およびビデオの動的理解、エージェントインタラクション能力などの面で全面的にアップグレードされています。このモデルは密集アーキテクチャとハイブリッドエキスパートアーキテクチャを提供し、エッジデバイスからクラウドまでの柔軟なデプロイをサポートします。
Qwen3-VLはQwenシリーズの中で最も強力なビジュアル言語モデルで、卓越したテキスト理解と生成能力、深いビジュアル認知と推論能力、長いコンテキストサポート、強力な空間およびビデオ動的理解能力、そして優れたエージェント対話能力を備えています。
Qwen3-VLはQwenシリーズの中で最も強力なビジュアル言語モデルで、包括的な総合アップグレードが実現されています。これには、卓越したテキスト理解と生成能力、より深いビジュアル感知と推論能力、より長いコンテキスト長、強化された空間およびビデオ動的理解能力、そしてより強力なエージェント対話能力が含まれます。
Qwen3-VLはアリババが開発した新世代のビジュアル言語モデルで、テキスト理解、ビジュアル感知、空間理解、長文脈処理、エージェントインタラクションなどの分野で全面的にアップグレードされ、エッジデバイスからクラウドまで柔軟にデプロイできます。
MiniMax-M2は、コーディングとエージェントのワークフローを最大化するために構築された小型の混合専門家モデルで、総パラメータは2300億、活性化パラメータは100億です。このモデルは、コーディングとエージェントタスクで卓越した性能を発揮し、同時に強力な汎用知能を維持し、コンパクトで高速かつ経済的に効率的な特徴を持っています。
ycngin2024
これは微調整されたWhisper音声認識モデルで、unsloth/whisper-large-v3-turboアーキテクチャに基づいており、UnslothとHuggingface TRLライブラリを使用して訓練速度を2倍に加速し、訓練効率を大幅に向上させています。
Qwen3-VLはQwenシリーズの中で最も強力なビジュアル言語モデルで、卓越したテキスト理解と生成能力、深いビジュアル認知と推論能力、長いコンテキストサポート、強力な空間とビデオ動的理解能力、そして優れたエージェントインタラクション能力を備えています。このバージョンは2Bパラメータの思考強化版で、推論能力が特別に最適化されています。
JanusCoder-14Bは、Qwen3-14Bをベースに構築された14Bパラメータのオープンソース基礎モデルで、コードインテリジェンスに統一されたビジュアルプログラミングインターフェイスを構築することを目的としています。このモデルはJANUSCODE-800Kマルチモーダルコードコーパスで学習され、さまざまなビジュアルプログラミングタスクを統一的に処理することができます。
JanusCoder-8Bは、Qwen3-8Bをベースに構築されたオープンソースのコードインテリジェンス基礎モデルで、統一されたビジュアルプログラミングインターフェイスを構築することを目的としています。このモデルは、JANUSCODE-800K(これまでで最大のマルチモーダルコードコーパス)で学習され、データ可視化、インタラクティブなWeb UI、コード駆動のアニメーションなど、さまざまなビジュアルプログラミングタスクを処理できます。
Qwen3-VL-32B-ThinkingはQwenシリーズで最も強力なビジュアル言語モデルで、卓越したテキスト理解と生成能力、深いビジュアル認知と推論能力、長文脈サポート、強力な空間およびビデオ動的理解能力、そして優れたエージェント対話能力を備えています。
Qwen3-VLは通義シリーズの中で最も強力なビジュアル言語モデルで、卓越したテキスト理解と生成能力、深いビジュアル認知と推論能力、長いコンテキストのサポート、強力な空間とビデオの動的理解能力、そして優れたエージェント対話能力を備えています。
Unsloth MCPサーバーは、大規模言語モデルを効率的に微調整するためのサーバーで、最適化技術により速度が2倍に向上し、メモリ使用量が80%削減されます。
Unsloth MCPサーバーは、大規模言語モデルを効率的に微調整するためのサーバーで、最適化アルゴリズムと4-bit量子化技術を通じて、トレーニング速度を2倍に向上させ、GPUメモリを80%節約し、複数の主流モデルをサポートします。
Unsloth MCPサーバーは、大規模言語モデルを効率的に微調整するためのサービスで、Unslothライブラリを基に2倍の高速化と80%のメモリ節約を実現し、複数のモデルと量子化技術をサポートしています。
 Transformers
Transformers%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
'%3e%3cpath%20d='M55.2622%2038L48.2289%2022L44.1206%2031.3333H47.2539L45.7872%2034.6667H38.7622L46.0956%2018H37.6706C36.7539%2018%2036.0039%2018.75%2036.0039%2019.6667V36.3333C36.0039%2037.25%2036.7539%2038%2037.6706%2038H55.2622Z'%20fill='white'/%3e%3cpath%20d='M64.3368%2018H50.3535L59.1535%2038H64.3368C65.2535%2038%2066.0035%2037.25%2066.0035%2036.3333V19.6667C66.0035%2018.75%2065.2535%2018%2064.3368%2018ZM63.0868%2034.6667H59.7535V21.3333H63.0868V34.6667Z'%20fill='%23FFCC66'/%3e%3cpath%20d='M89.3379%2026.75V29.25H81.8379V36.75H91.8379V24.25H81.8379V26.75H89.3379ZM84.3379%2034.25V31.75H89.3379V34.25H84.3379Z'%20fill='white'/%3e%3cpath%20d='M103.504%2036.75V29.25H96.0039V26.75H103.504V24.25H93.5039V31.75H101.004V34.25H93.5039V36.75H103.504Z'%20fill='white'/%3e%3cpath%20d='M115.17%2026.75V24.25H105.17V36.75H115.17V34.25H107.67V31.75H115.17V29.25H107.67V26.75H115.17Z'%20fill='white'/%3e%3cpath%20d='M80.1712%2029.25V29.175L78.9962%2028L80.1712%2026.825V20.425L78.9962%2019.25H69.3379V36.75H78.9962L80.1712%2035.575V29.25ZM77.6712%2034.25H71.8379V29.25H77.6712V34.25ZM77.6712%2026.75H71.8379V21.75H77.6712V26.75Z'%20fill='white'/%3e%3c/g%3e%3cg%20clip-path='url(%23clip1_644_3948)'%3e%3cpath%20d='M169.59%2022.9827L169.59%2023.6491H177.409L168.175%2032.8822L169.118%2033.8248L178.351%2024.5917L178.352%2032.4106H179.685V22.3164L179.018%2022.3157H169.59V22.9827Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_644_3948'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(36%2018)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_644_3948'%3e%3crect%20width='20'%20height='20'%20fill='white'%20transform='translate(164%2018)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)