アリババの通義ラボがFIPOアルゴリズムを発表。Future-KLメカニズムにより、複雑な論理推論における従来の強化学習の課題を解決し、数学問題などの推論精度と効率を大幅に向上させた。....
アリババの通義研究所が新アルゴリズムFIPOを発表。Future-KLメカニズムを導入し、長文推論における純粋強化学習の「推論長停滞」問題を解決し、複雑な論理整合性のトレーニング効果を向上させます。....
西湖ロボティクス社が人形ロボットのタイタンo1を発表しました。このロボットには世界で初めての動作汎化大モデルであるGAEサイボーパークシステムが搭載されています。このロボットはミリ秒単位で模倣する能力を持ち、リアルタイムで人の動きを再現することが可能で、一人で複数台のサイボーパークを操作できるようになり、ロボット分野における新たな突破を示しています。
快手傘下の可霊AIは2026年初頭に急成長し、MAUが1200万人を突破、有料ユーザーは前月比350%増。成長は多モーダル動画モデル「O1」や「音画同出」機能、2026年1月の「動作制御」新機能など迅速な製品改良による。....
専門のAIビデオ生成プラットフォームで、テキストと画像からビデオを作成し、入力されたビデオを幅広く編集することができます。
AI音楽ジェネレーター。歌詞とプロンプトを完全に制作された楽曲に変換し、無制限でロイヤリティフリーです!
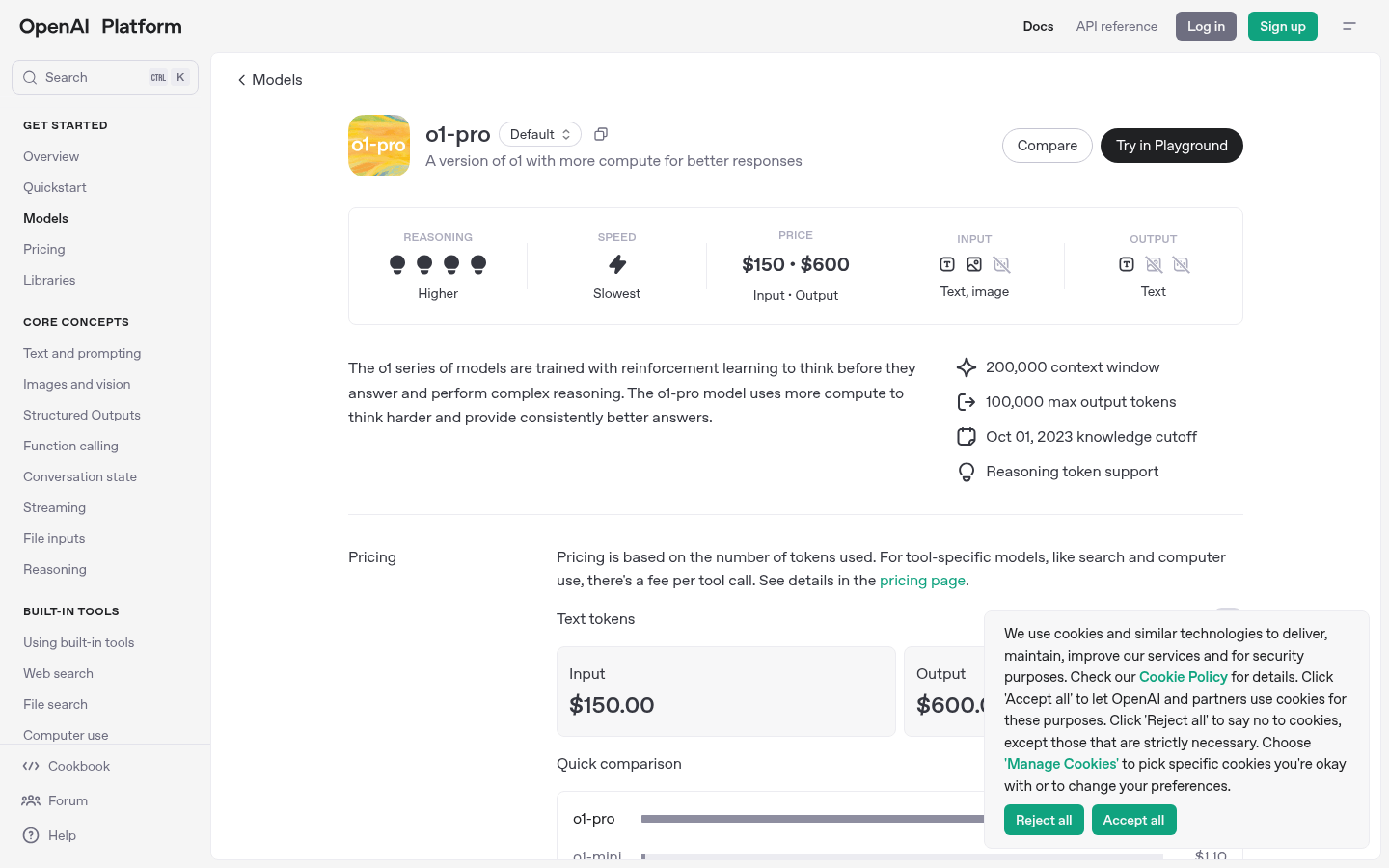
o1-proモデルは強化学習により複雑な推論能力を向上させ、より最適な回答を提供します。
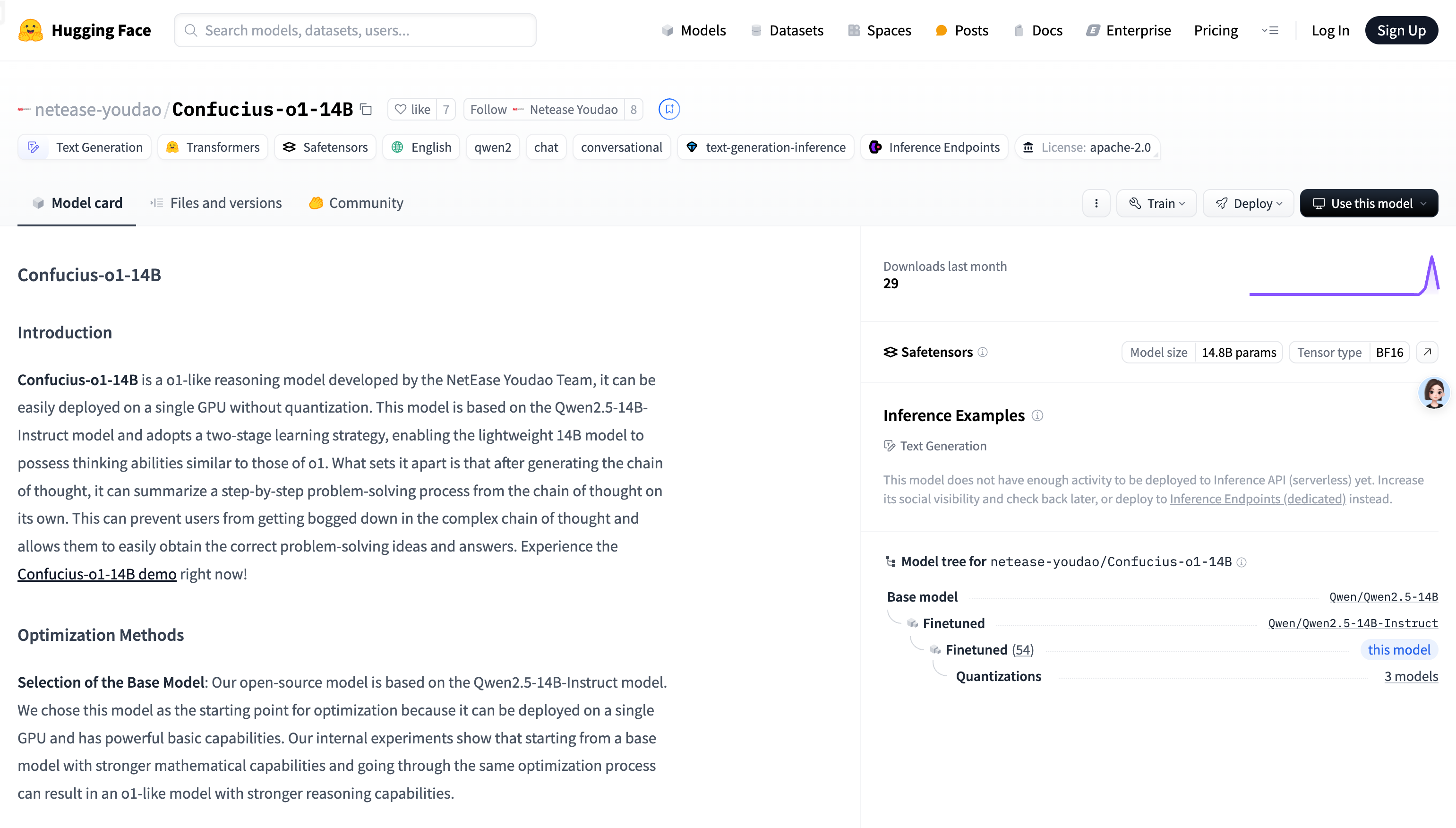
网易有道が開発した軽量な推論モデル。単一のGPUで展開でき、o1と同等の推論能力を備えています。
Openai
$14
入力トークン/百万
$56
出力トークン/百万
200
コンテキスト長
Alibaba
$2
-
32
$105
$420
$21
$84
128
XiaomiMiMo
MiMo-7B-RLはMiMo-7B-SFTモデルを基に強化学習で訓練されたモデルで、数学とコード推論タスクで優れた性能を発揮し、OpenAI o1-miniに匹敵する性能を持っています。
MiMo-7B-RLはMiMo-7B-SFTモデルを基に強化学習でトレーニングされたモデルで、数学とコード推論タスクにおいてOpenAI o1-miniと肩を並べる性能を発揮します。
evilfreelancer
GigaChat-20B-A3Bモデルを基に訓練されたLoRAアダプターで、ロシア語の論理的思考プロセスをシミュレートするために特別に設計
Skywork
Skywork o1 Open-PRM-Qwen-2.5-1.5BはQwen2.5-Math-1.5B-Instructをベースに訓練された増分プロセス報酬モデルで、小規模な複雑問題解決能力の強化を目的として設計されています。
Skywork o1 Open-Llama-3.1-8BはLlama-3.1-8Bをベースに訓練された強力な対話モデルで、'スロー思考'推論スタイルのデータにより推論能力が大幅に強化されています。
Skywork o1オープンモデルシリーズの7Bパラメータ規模モデル、Qwen2.5-Math-7B-Instructをベースに訓練、段階的プロセス報酬強化の推論能力を備える
HKAIR-Lab
HK-O1awはO1スタイルの複雑な推理能力を備えた法律アシスタントで、LLaMA-3.1-8Bをベースに香港地域の法律分野向けに設計されています。
このプロジェクトは、OpenAIのo1モデルとFluxの機能を統合するMCPサーバーを提供し、モデルのインタラクションと画像処理機能をサポートします。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
'%3e%3cpath%20d='M55.2622%2038L48.2289%2022L44.1206%2031.3333H47.2539L45.7872%2034.6667H38.7622L46.0956%2018H37.6706C36.7539%2018%2036.0039%2018.75%2036.0039%2019.6667V36.3333C36.0039%2037.25%2036.7539%2038%2037.6706%2038H55.2622Z'%20fill='white'/%3e%3cpath%20d='M64.3368%2018H50.3535L59.1535%2038H64.3368C65.2535%2038%2066.0035%2037.25%2066.0035%2036.3333V19.6667C66.0035%2018.75%2065.2535%2018%2064.3368%2018ZM63.0868%2034.6667H59.7535V21.3333H63.0868V34.6667Z'%20fill='%23FFCC66'/%3e%3cpath%20d='M89.3379%2026.75V29.25H81.8379V36.75H91.8379V24.25H81.8379V26.75H89.3379ZM84.3379%2034.25V31.75H89.3379V34.25H84.3379Z'%20fill='white'/%3e%3cpath%20d='M103.504%2036.75V29.25H96.0039V26.75H103.504V24.25H93.5039V31.75H101.004V34.25H93.5039V36.75H103.504Z'%20fill='white'/%3e%3cpath%20d='M115.17%2026.75V24.25H105.17V36.75H115.17V34.25H107.67V31.75H115.17V29.25H107.67V26.75H115.17Z'%20fill='white'/%3e%3cpath%20d='M80.1712%2029.25V29.175L78.9962%2028L80.1712%2026.825V20.425L78.9962%2019.25H69.3379V36.75H78.9962L80.1712%2035.575V29.25ZM77.6712%2034.25H71.8379V29.25H77.6712V34.25ZM77.6712%2026.75H71.8379V21.75H77.6712V26.75Z'%20fill='white'/%3e%3c/g%3e%3cg%20clip-path='url(%23clip1_644_3948)'%3e%3cpath%20d='M169.59%2022.9827L169.59%2023.6491H177.409L168.175%2032.8822L169.118%2033.8248L178.351%2024.5917L178.352%2032.4106H179.685V22.3164L179.018%2022.3157H169.59V22.9827Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_644_3948'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(36%2018)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_644_3948'%3e%3crect%20width='20'%20height='20'%20fill='white'%20transform='translate(164%2018)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)