Kuaishou's Qilin AI announced on its official WeChat account the launch of its first "Audio-Visual Synthesis" model, officially named Qilin 2.6. The highlight of this model is its ability to generate images, natural voice, sound effects, and ambient atmosphere in a single generation process, fully bridging the "audio" and "visual" worlds and enhancing the user's creative experience.
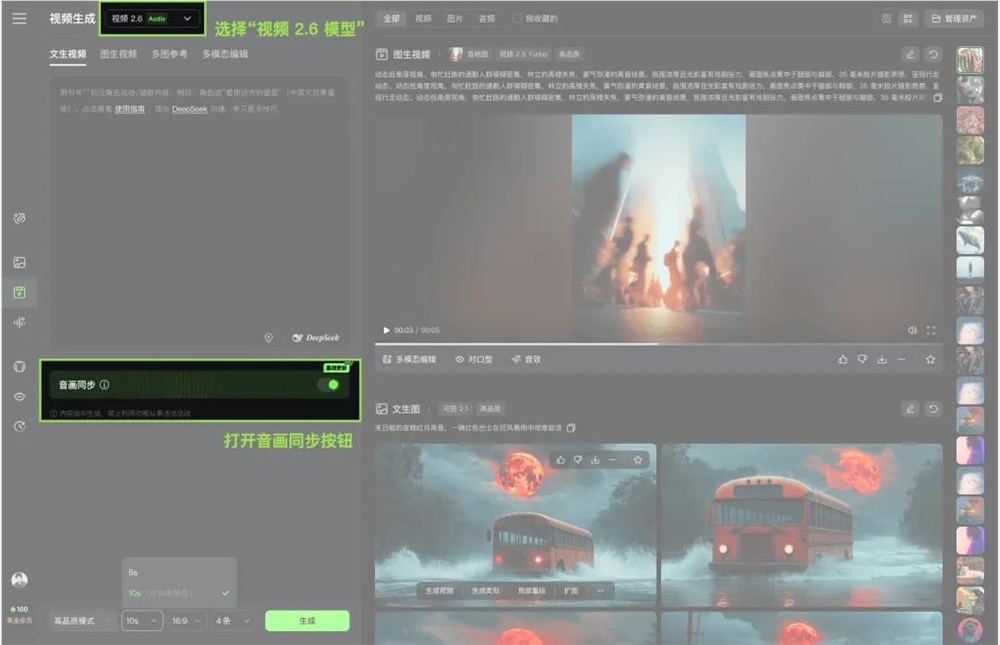
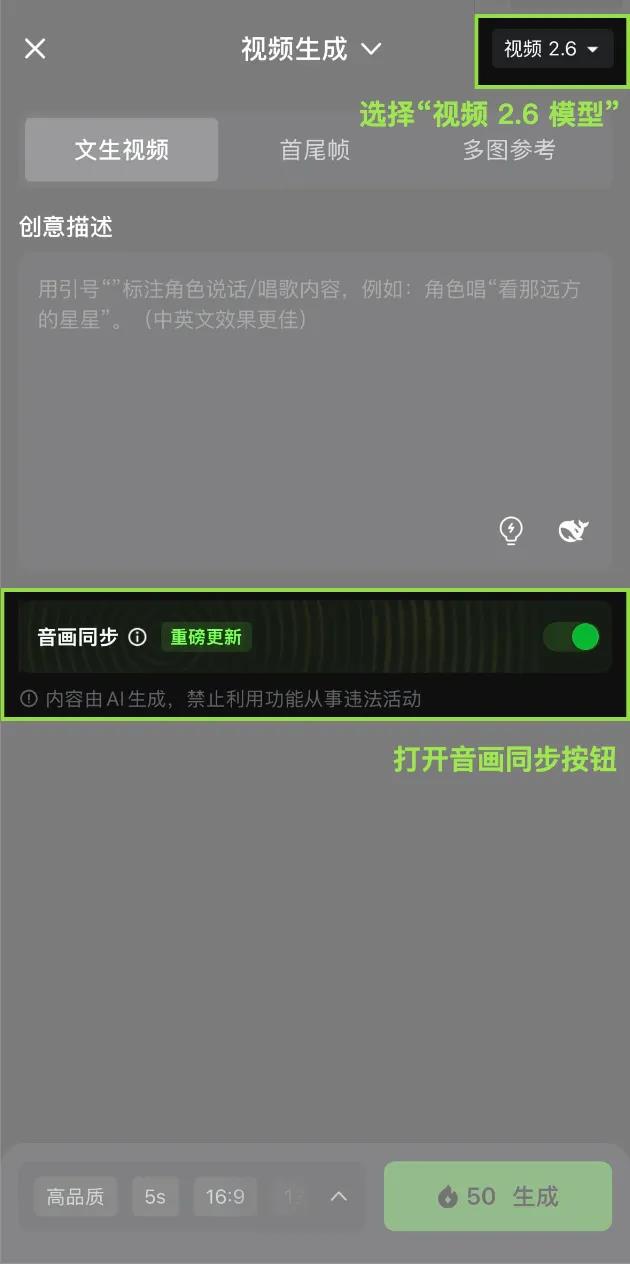
Qilin 2.6 offers two creative paths: "Text-to-Audio-Visual" and "Image-to-Audio-Visual." "Text-to-Audio-Visual" allows users to quickly generate complete audio-video content with just a simple sentence. Meanwhile, "Image-to-Audio-Visual" enables static images to "speak" and be presented dynamically. This means that users can easily create rich audio-video content by simply providing text or images.
The model has a wide range of application scenarios, suitable for various forms of content creation, including monologues (such as product showcases, lifestyle vlogs, news reports, and speeches), voiceovers (such as product explanations, sports commentary, documentaries, and storytelling), dialogues (such as interviews and short plays), and music performances (such as singing, rapping, multiple harmonies, and instrument playing).
Qilin AI stated that the release of version 2.6 will make video creation more flexible and convenient, allowing users to better express their creativity and ideas. The launch of this model marks another step forward for Kuaishou in the field of AI creation, further meeting the growing content creation needs of users.
Key Points:
🎨 Qilin 2.6 model achieves synchronized audio-visual generation, enhancing the user's creative experience.
🖊️ Offers two creative paths: "Text-to-Audio-Visual" and "Image-to-Audio-Visual," making it easy to create various content formats.
🎤 Suitable for a wide range of scenarios, including monologues, voiceovers, dialogues, and music performances.








