El 11 de agosto, Zhipu Tech lanzó oficialmente su nuevo modelo de comprensión visual —— GLM-4.5V. Este modelo se entrenó basándose en su nuevo modelo de texto GLM-4.5-Air, heredando la línea técnica del modelo anterior de razonamiento visual GLM-4.1V-Thinking. Cuenta con un asombroso número de parámetros de 106 mil millones y 12 mil millones de parámetros activados. Destaca que el GLM-4.5V incluye una función de "modo de pensamiento", que los usuarios pueden elegir activar o no, lo que les permite manejar las tareas de manera más flexible.
La capacidad visual de este modelo es notable, ya que puede distinguir fácilmente entre el ala de pollo de McDonald's y KFC, analizando profundamente desde múltiples ángulos como el color y la textura. Además, el GLM-4.5V puede participar en desafíos de adivinar ubicaciones en imágenes, incluso logrando excelentes resultados en competencias, superando al 99% de los participantes humanos y colocándose en el puesto 66. Zhipu también mostró el excelente desempeño de este modelo en 42 pruebas estándar, obteniendo puntuaciones superiores a otros modelos de tamaño similar en la mayoría de las pruebas.
Actualmente, el GLM-4.5V ya está disponible en plataformas de código abierto como Hugging Face, ModelScope y GitHub, donde los usuarios pueden descargarlo gratis y también se ofrece una versión cuantificada en FP8. Para ofrecer una mejor experiencia con este modelo, Zhipu lanzó una aplicación de asistente de escritorio que admite capturas de pantalla y grabaciones en tiempo real, ayudando a los usuarios a realizar diversas tareas de razonamiento visual, incluyendo asistencia en código y interpretación de documentos.
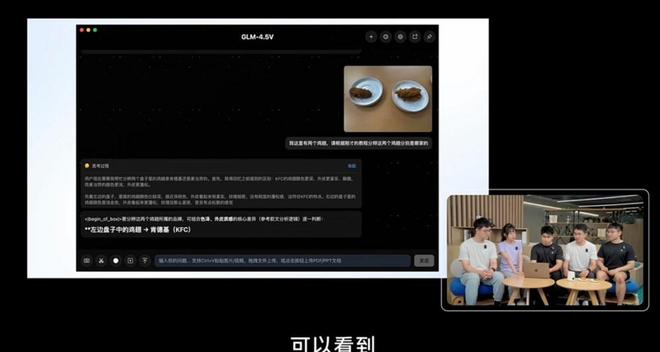
En pruebas prácticas, el GLM-4.5V demostró habilidades destacadas, capaz de inferir ubicaciones a partir de imágenes cargadas, aunque ocasionalmente presenten pequeños errores, el proceso de razonamiento sigue siendo muy rico. Al procesar contenido web, puede generar páginas con alta similitud mediante capturas de pantalla, mostrando una poderosa capacidad de reproducción.

El GLM-4.5V no solo destaca en el campo de la comprensión visual, sino que también muestra un gran potencial en escenarios de aplicación de Agentes. Con el continuo desarrollo de esta tecnología, tenemos motivos para esperar que en el futuro, esta tecnología brinde más comodidad a la vida de las personas.