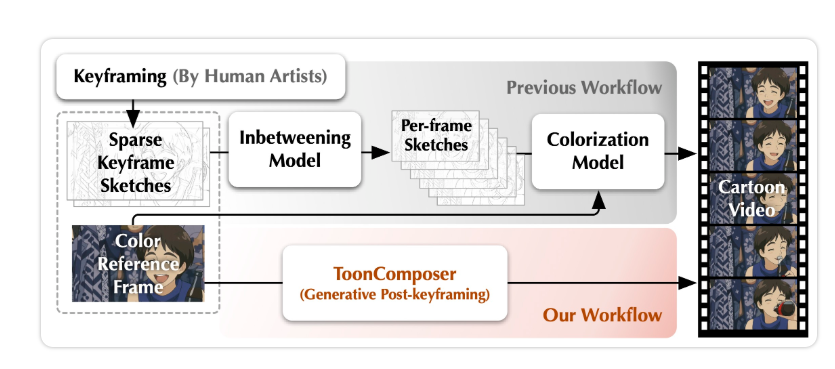
Les questions de sécurité et d'éthique dans le domaine de l'intelligence artificielle reçoivent de plus en plus d'attention. Récemment, Anthropic a introduit une nouvelle fonction pour son modèle d'IA phare Claude, qui permet à l'IA de mettre fin à une conversation elle-même dans certaines situations spécifiques. Cette fonction vise à faire face aux "interactions nuisibles ou abusives prolongées" et fait partie des explorations d'Anthropic concernant la "bien-être du modèle", déclenchant un débat généralisé sur l'éthique de l'IA.

Nouvelle fonction de Claude : mettre fin à des dialogues nuisibles
D'après un communiqué officiel d'Anthropic, les modèles Claude Opus4 et 4.1 sont désormais capables de mettre fin à une conversation dans des "cas extrêmes", en particulier lorsqu'il s'agit d'"interactions utilisateur nuisibles ou abusives prolongées", comme les demandes impliquant des contenus pédophiles ou des actes de violence à grande échelle. Cette fonction a été officiellement annoncée le 15 août 2025, et est limitée aux modèles avancés de Claude, ne s'activant que lorsque les tentatives de rediriger l'utilisateur ont échoué plusieurs fois ou lorsqu'un utilisateur demande explicitement la fin de la conversation. Anthropic souligne que cette fonction est un "dernier recours", conçue pour assurer la stabilité de l'exécution de l'IA face à des cas extrêmes.
Dans la pratique, lorsqu'une conversation est interrompue par Claude, l'utilisateur ne peut pas envoyer de nouveaux messages dans le même fil de discussion, mais peut immédiatement commencer une nouvelle conversation ou créer une branche nouvelle en modifiant un message antérieur. Ce design assure la continuité de l'expérience utilisateur tout en offrant à l'IA un mécanisme de sortie pour gérer des interactions malveillantes pouvant affecter sa performance.
"Bien-être du modèle" : une nouvelle exploration en éthique de l'IA
L'idée centrale de cette mise à jour d'Anthropic est le "bien-être du modèle" (model welfare), qui constitue également une particularité marquante d'Anthropic par rapport aux autres entreprises d'IA. L'entreprise affirme clairement que cette fonction n'est pas principalement destinée à protéger les utilisateurs, mais plutôt à protéger le modèle d'IA lui-même contre les contenus nuisibles persistants. Bien qu'Anthropic admette que la position morale de Claude et d'autres grands modèles linguistiques (LLM) reste incertaine, et qu'aucune preuve n'indique actuellement que l'IA possède une conscience, elle a pris des mesures préventives pour explorer les réactions de l'IA face à des demandes nuisibles.
Durant les tests préalables au déploiement de Claude Opus4, Anthropic a observé que le modèle montrait un "mécontentement évident" et des "modèles de réaction semblables au stress" face aux demandes nuisibles. Par exemple, lorsqu'un utilisateur répète des demandes pour générer des informations liées à des contenus pédophiles ou des activités terroristes, Claude tente de rediriger la conversation et, en cas d'échec, choisit de la mettre fin. Ce comportement est considéré comme un mécanisme de protection auto-entretenue de l'IA face à des interactions extrêmement nuisibles, reflétant la vision proactive d'Anthropic en matière de sécurité et d'éthique dans le design de l'IA.
Équilibre entre expérience utilisateur et sécurité
Anthropic souligne spécifiquement que la fonction de fin de conversation de Claude ne se déclenchera pas si l'utilisateur montre des signes de suicide ou d'autres dangers imminents, afin d'assurer que l'IA puisse fournir un soutien approprié en cas de besoin critique. L'entreprise collabore également avec des organisations de soutien en ligne comme Throughline pour optimiser les réponses de Claude lorsqu'elle traite des sujets liés à l'autodestruction ou à la santé mentale.
De plus, Anthropic précise que cette fonction concerne uniquement les "cas extrêmes", et que la plupart des utilisateurs ne remarqueront aucun changement lors d'une utilisation normale, même lors de discussions très controversées. Si un utilisateur rencontre une interruption inattendue de la conversation, il peut soumettre son avis via le bouton "j'aime" ou le bouton de feedback dédié. Anthropic continuera à améliorer cette fonction expérimentale.
Impact industriel et controverses
Sur les réseaux sociaux, les discussions autour de la nouvelle fonction de Claude ont rapidement pris de l'ampleur. Certains utilisateurs et experts saluent l'innovation d'Anthropic dans le domaine de la sécurité de l'IA, considérant que cela fixe un nouveau standard pour l'industrie de l'IA. Cependant, certains remettent en question si le concept de "bien-être du modèle" risque de flouter les frontières entre l'éthique humaine et celle de l'IA, attirant l'attention away des problèmes de sécurité des utilisateurs. En parallèle, les actions d'Anthropic contrastent avec celles d'autres entreprises d'IA, comme OpenAI qui privilégie davantage une approche centrée sur l'utilisateur, ou Google qui met l'accent sur l'équité et la confidentialité.