Chinese AI company MiniMax has officially announced the open-source release of its latest large language model (LLM), MiniMax-M1, which has drawn global attention due to its ultra-long context reasoning capability and efficient training cost. AIbase has compiled the latest information to provide a comprehensive interpretation of MiniMax-M1.
Record-breaking Context Window: 1M Input, 80k Output
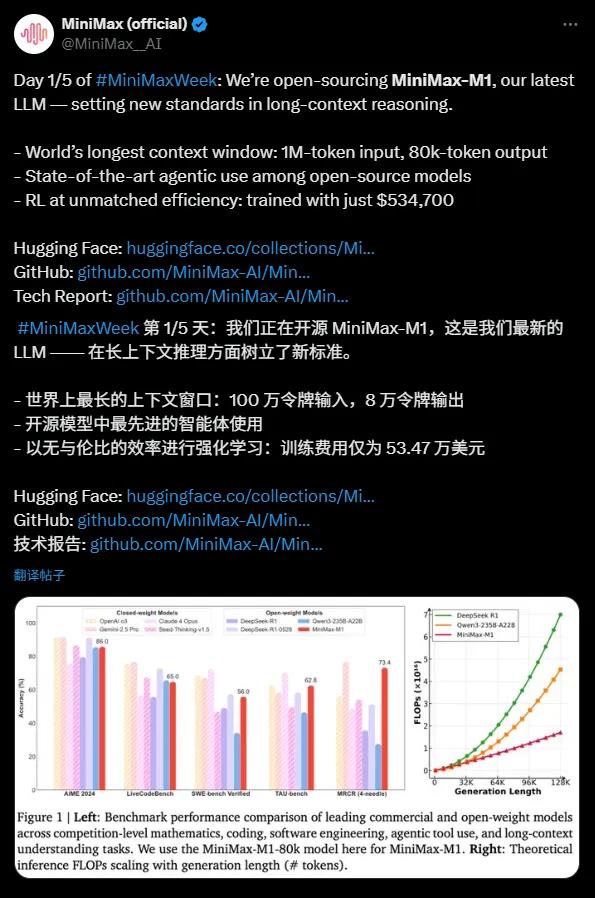
With an impressive context window capable of handling up to 1 million input tokens and 80 thousand output tokens, MiniMax-M1 stands out as the most proficient at long-context reasoning among currently available open-source models. This ability means the model can process information equivalent to an entire novel or even a series of books in one go, far surpassing OpenAI GPT-4's 128,000 token context window. Whether it's complex document analysis, long-form code generation, or multi-round dialogues, MiniMax-M1 handles these tasks with ease, providing businesses and developers with a powerful tool.
Pioneering Proxy Capability Among Open-Source Models
MiniMax-M1 excels in using proxy tools, performing on par with top commercial models like OpenAI o3 and Claude4Opus. Thanks to its combination of the Mixture of Experts (MoE) architecture and the Lightning Attention mechanism, MiniMax-M1 demonstrates nearly state-of-the-art performance in complex tasks such as software engineering, tool invocation, and long-context reasoning. The powerful proxy capability of this open-source model presents unprecedented opportunities for the global developer community.

High Cost Efficiency: $530,000 to Build a Cutting-Edge LLM
MiniMax-M1’s training cost is remarkable, requiring only $534,700, compared to DeepSeek R1's $5-6 million and OpenAI GPT-4's over $100 million, making it a "budget-friendly miracle." With the help of efficient reinforcement learning (RL) techniques and hardware support from just 512 H800 GPUs, MiniMax completed model development in only three weeks. Additionally, MiniMax’s pioneering CISPO optimization algorithm further enhances inference efficiency, ensuring critical information is not lost while reducing training costs.
Technical Highlights: 456 Billion Parameters and Efficient Architecture
Based on MiniMax-Text-01, MiniMax-M1 has a total of 456 billion parameters, activating approximately 45.9 billion parameters per token, achieving efficient computation through the MoE architecture. The model supports two modes of inference—40k and 80k thought budgets—to meet various scenario needs. In benchmark tests for math, coding, and other inference-intensive tasks, MiniMax-M1 performs strongly, surpassing models like DeepSeek R1 and Qwen3-235B-A22B.
Milestone in the Open-Source Ecosystem
Adopting the Apache2.0 license, MiniMax-M1 is now available on the Hugging Face platform for free use by developers worldwide. This move not only challenges open-source models from other Chinese AI companies like DeepSeek but also injects new vitality into the global AI ecosystem. MiniMax has stated that it will release more technical details in the future to further drive innovation within the open-source community.
The release of MiniMax-M1 marks a significant breakthrough in long-context reasoning and proxy capabilities among open-source AI models. Its ultra-long context window, efficient training cost, and powerful performance offer businesses and developers highly cost-effective solutions. AIbase believes that the open-sourcing of MiniMax-M1 will accelerate the application of AI technology in complex tasks, propelling the global AI ecosystem to new heights.