Meta's next flagship model, codenamed Avocado, is set to launch in Q1 2026 as the successor to the Llama series. It will be a closed-source commercial model, competing directly with GPT-5 and Gemini in the closed-model ecosystem.....
NVIDIA's NVARC outperforms GPT-5Pro in ARC-AGI2 with 27.64% accuracy at just $0.20 per task, far cheaper than competitors' $7. It uses a unique zero-pretraining deep learning method, eliminating the need for large general datasets.....
Perplexity has launched the BrowseSafe system, designed to protect AI browser proxies from being manipulated by online content in real time. The system claims a 91% success rate in detecting prompt injection attacks, which is higher than GPT-5's 85% and PromptGuard-2's 35%. Additionally, it runs quickly and can monitor in real time. As AI browser proxies become more widespread, such security solutions are becoming increasingly important.
OpenAI CEO Sam Altman advanced GPT-5.2's release to Dec 9 to counter Google Gemini 3, boasting 18% faster reasoning, 23% better multimodal efficiency, and 32,768-token context length, all surpassing Gemini 3's current specs.....
GPTunneL provides multi-model AI services, which can generate text, images, etc., and supports multiple payment methods.
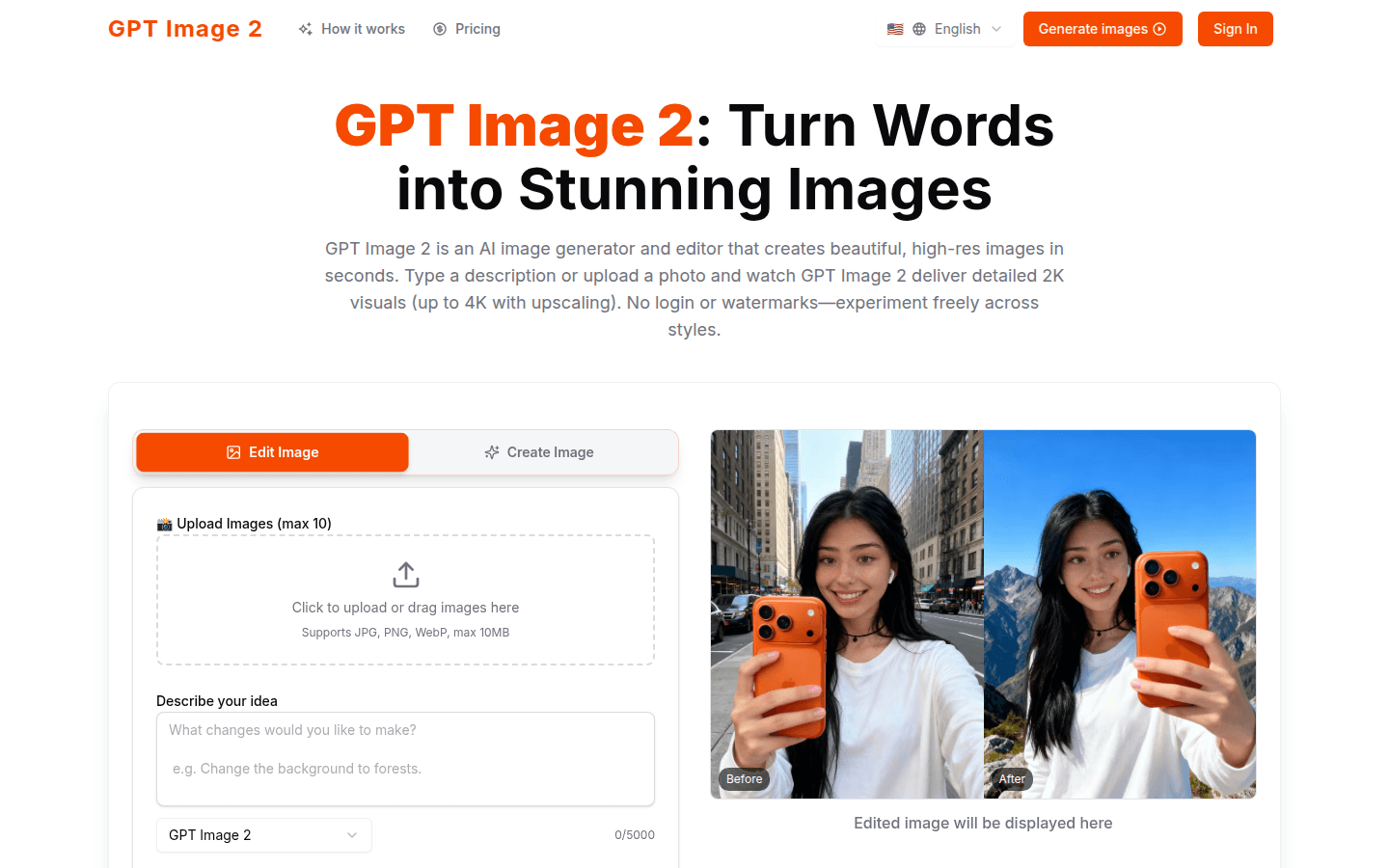
GPT Image 2 is an AI image generation and editor that can generate high-resolution images in seconds.
A powerful AI image editing platform that uses GPT - Image - 2 technology to generate, edit, and enhance professional images.
An in - house corporate GPT that can search across documents, code, and communications to answer questions quickly and accurately.
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
-
Bytedance
$0.8
$2
128
Alibaba
$0.4
$8.75
$70
400
$1.75
$14
$0.35
64
$0.63
$3.15
131
$1.8
$5.4
16
Tencent
32
$17.5
$56
$0.7
$2.4
$9.6
Google
$0.14
$0.28
$1.4
mradermacher
This is an open-source large language model with 20 billion parameters focusing on the field of network security. It is based on the GPT-OSS architecture and fine-tuned by integrating multiple network security instruction datasets. The model provides various quantization versions, which are convenient for deployment in resource-constrained environments and can be used to generate network security-related texts, codes, and analysis reports.
bartowski
This is the quantized version of kldzj's GPT-OSS-120B-Heretic-v2 model, which is quantized using the imatrix technology of llama.cpp. The model significantly reduces the storage and computing resource requirements through quantization technology while maintaining good model performance, facilitating deployment and operation on various devices.
This is a quantized version of the kldzj/gpt-oss-120b-heretic model, quantized using llamacpp. It offers a variety of quantization types, including special formats such as BF16, Q8_0, and MXFP4_MOE, significantly improving the model's operating efficiency.
This is a quantized version of the p-e-w/gpt-oss-20b-heretic model, quantized using the imatrix technology of llama.cpp. The model is a large language model with 20 billion parameters, offering a variety of quantization options ranging from high quality to low quality, with file sizes from 41.86GB to 11.52GB, suitable for different hardware conditions.
TeichAI
This model is based on Qwen3-4B-Thinking-2507 and fine-tuned on 1000 examples of GPT-5-Codex. It focuses on text generation tasks and uses Unsloth technology to achieve a 2-fold increase in training speed.
Mungert
gpt-oss-safeguard-20b is a security inference model fine-tuned based on GPT-OSS-20b, specifically designed for input-output filtering of large language models, online content annotation, and offline annotation for trust and security use cases. This model uses the Apache 2.0 license and supports custom policies and a transparent decision-making process.
unsloth
gpt-oss-safeguard-120b is a security reasoning model built by OpenAI based on gpt-oss, with 117 billion parameters (5.1 billion of which are active parameters). This model is specifically designed for security use cases and can classify text content and perform basic security tasks according to the provided security policies.
GPT-OSS-Safeguard-20B is a security reasoning model with 21 billion parameters built on GPT-OSS, specifically optimized for security-related text content classification and filtering tasks. This model supports custom security policies, provides a transparent reasoning process, and is suitable for security use cases such as input-output filtering of large language models and online content annotation.
ModelCloud
This is a 4-bit W4A16 quantized version based on the MiniMax M2 base model, quantized by @Qubitum of ModelCloud using the GPT-QModel tool. This model is specifically optimized for text generation tasks, significantly reducing the model size and inference resource requirements while maintaining good performance.
noctrex
This is the MXFP4_MOE quantized version of the Huihui GPT-OSS-120B-BF16-abliterated-v2 model, specifically optimized for text generation tasks to provide efficient text generation capabilities. The model reduces computational and storage requirements through quantization techniques while maintaining good performance.
SiddhJagani
This is an 8-bit quantized version of the OpenAI GPT-OSS-20B model in MLX format, converted using mlx-lm 0.28.2 and optimized for Apple Silicon, providing efficient text generation capabilities.
textcleanlm
This is a content fidelity model based on the unsloth/gpt-oss-20b-BF16 base model, specifically designed to convert raw text into a concise and clear Markdown format. The model uses the Apache 2.0 license and mainly supports English text processing.
limeso
This is a Transformer model published on the Hugging Face model hub. The model card documentation is automatically generated, and currently lacks specific detailed information about the model.
nvidia
NVIDIA GPT-OSS-120B Eagle3 is an optimized version based on the OpenAI gpt-oss-120b model. It adopts the Mixture of Experts (MoE) architecture, with a total of 120 billion parameters and 5 billion active parameters. This model supports both commercial and non-commercial use and is suitable for text generation tasks, especially for the development of AI Agent systems, chatbots, and other applications.
MikeKuykendall
This is the GGUF format version of the GPT-OSS 20B model based on WeOpenML, which first implements the innovative MoE CPU expert offloading technology. This technology achieves a 99.9% reduction in video memory while maintaining the full generation quality, and only requires 2MB of video memory to run a 20 billion parameter mixture of experts model.
Jackrong
This project distills the inference ability of GPT into the Llama-3.1-8B model through an innovative two-stage training process. First, knowledge distillation and format alignment are performed through supervised fine-tuning, and then reinforcement learning is used to encourage the model to independently explore and optimize inference strategies, focusing on breakthroughs in the field of mathematical reasoning.
QuantTrio
GLM-4.6-GPTQ-Int4-Int8Mix is a quantized version based on the zai-org/GLM-4.6 base model, which performs excellently in text generation tasks. This model achieves optimization of the model size through GPTQ quantization technology while maintaining good performance.
Tesslate
WEBGEN DEVSTRAL IMAGES is an AI model focused on web page generation. It can generate single-page web pages using HTML, CSS, JS, and Tailwind technologies. This project is trained based on custom templates and uses the supervised fine-tuning method, training with a dataset generated by GPT-OSS-120B.
EpistemeAI
This model is based on GPT-OSS-20B and fine-tuned using the Unsloth reinforcement learning framework. The aim is to optimize inference efficiency and reduce vulnerabilities that occur during reinforcement learning from human feedback (RLHF) training. The fine-tuning process focuses on the robustness and efficiency of alignment, ensuring that the model maintains inference depth without incurring excessive computational overhead.
geoffmunn
This is the GGUF quantized version of the Qwen/Qwen3-Coder-30B-A3B-Instruct language model, optimized for local inference and supporting frameworks such as llama.cpp, LM Studio, OpenWebUI, and GPT4All. This model is a code generation and programming assistant model with a parameter scale of 30B.
The GPT Researcher MCP Server is an AI research server based on the MCP protocol. It can provide high-quality and optimized research results for LLM applications through in-depth web search and verification.
This project demonstrates how to integrate the MCP (Model Context Protocol) server with Pydantic.AI, includes example code for weather services, and supports interaction through different LLMs (such as GPT - 4 and Sonnet).
The Image Gen MCP Server is a general AI image generation service that provides cross - platform and multi - model image generation capabilities for various LLM chatbots through the Model Context Protocol (MCP) standard protocol. It supports multiple image models from OpenAI and Google, enabling seamless conversion from text conversations to visual content.
A server that directly queries OpenAI models via the MCP protocol, supporting the o3 - mini and gpt - 4o - mini models, providing concise and detailed answers.
An image generation and editing tool based on the OpenAI GPT-4o/gpt-image-1 model, supporting image generation through text prompts, image editing (such as repair, extension, composition, etc.), and being compatible with multiple MCP clients.
A client project based on Python 3.13 that integrates MCP services and the GPT-4 model, providing interactive tool invocation and network search functionality.
An MCP server for image generation and editing based on the OpenAI gpt-image-1 model, supporting the creation and modification of images through text prompts, providing convenient integration methods and rich configuration options.
An MCP server based on TypeScript that provides AI image and video generation functions, requiring the support of an API key from GPT4O Image Generator.
A Midjourney image generation server based on the GPTNB API, providing functions such as image generation, editing, and face replacement
An automatic commit message generation tool based on Git change analysis, leveraging OpenAI's GPT model to generate standardized commit information for code changes.
This project is a stdio server based on the Model Context Protocol (MCP), used to forward prompts to OpenAI's ChatGPT (GPT-4o), supporting advanced summarization, analysis, and reasoning functions, suitable for assistant integration in the LangGraph framework.
An image analysis MCP server based on the GPT-4o-mini model that can handle image content analysis from URLs or local paths
A TypeScript-based MCP server that provides AI image and video generation functions and requires support from the API key of GPT4O Image Generator.
The OpenAPITools SDK is a multi - AI platform tool management library that provides a unified interface to support the integration and execution of tools for models such as Claude, GPT, and LangChain, and supports both local and API usage modes.
A server that interacts with ChatGPT through the MCP protocol for advanced text analysis and reasoning.
A code review tool designed for Cursor IDE, which uses OpenAI's GPT model to provide intelligent code analysis and suggestions.
A lightweight Excel automation MCP server based on FastAPI and GPT - 4o, supporting Excel file operations through natural language.
MCP - ChatBot is a chatbot application based on the Modular Capability Protocol (MCP). It integrates weather services and the GPT - 4o model through a containerized architecture to provide natural language interaction capabilities.
The Meta API MCP Server is a multi - API gateway server that connects various APIs with large - language models (such as Claude, GPT, etc.) through the Model Context Protocol (MCP), enabling AI assistants to directly interact with APIs and access real data sources. It supports quickly adding APIs from JSON configuration files or Postman collections, and provides comprehensive support for HTTP methods and multiple authentication methods.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)