英伟达在SIGGRAPH大会上发布多款机器人AI开发工具:1)70亿参数视觉语言模型Cosmos Reason,具备物理理解和记忆能力;2)Cosmos Transfer-2及精简版,可加速生成合成训练数据;3)神经重建库实现3D场景模拟;4)RTX Pro Blackwell服务器和DGX Cloud管理平台。这些工具将整合至CARLA模拟器等开源平台,助力机器人规划、视频分析等应用,展现英伟达布局机器人领域的战略意图。(140字)
英伟达在SIGGRAPH大会上发布开源物理AI模型Cosmos Reason,该70亿参数模型显著提升机器人视觉推理能力,能像人类一样处理复杂多步骤任务。演示中机器人成功完成"面包+烤面包机"的合理操作推理。该技术已应用于优步自动驾驶数据标注、麦格纳配送方案等多个商业场景。英伟达同时更新了Omniverse工具包和神经重建库,推动AI与机器人技术深度融合。
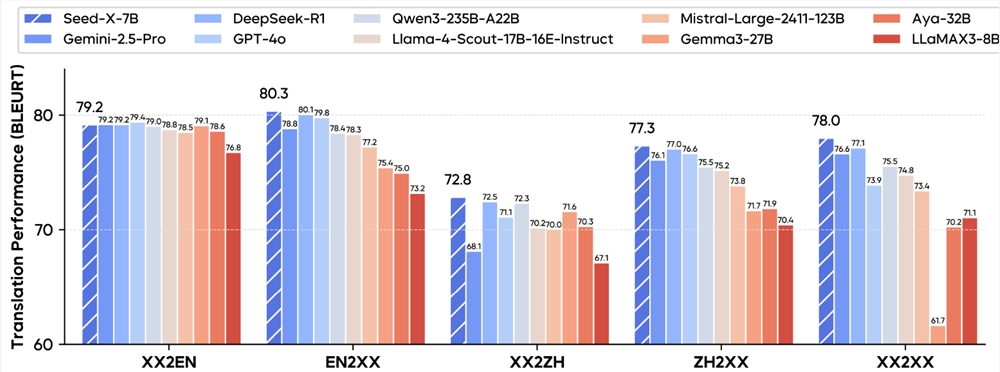
字节跳动开源轻量级多语言翻译模型Seed-X,支持28种语言双向翻译,性能媲美顶级大模型。该70亿参数模型基于Mistral架构,专注翻译优化,在多个领域表现出色。采用创新训练策略生成高质量数据,优化部署效率。这是字节继BAGEL、Seed-Coder等之后又一开源项目,推动AI翻译技术进步。
6月30日,华为于正式宣布开源盘古70亿参数的稠密模型、盘古Pro MoE720亿参数的混合专家模型,以及基于升腾的模型推理技术。 此次开源举措,是华为践行升腾生态战略的关键一步,旨在推动大模型技术的研究与创新发展,加速人工智能在各行业的应用并创造价值。
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$4
$16
$1
$10
256
Baidu
128
$2
$20
$6
$24
$8
$240
52
Bytedance
$1.2
$3.6
4
Trilogix1
Fara-7B是微软专门为计算机使用场景设计的高效小型语言模型,参数仅70亿,在网页操作等高级用户任务中表现出色,能与更大型的代理系统竞争。
mlx-community
本模型是基于allenai/Olmo-3-7B-Instruct转换的8位量化版本,专门为Apple MLX框架优化。它是一个70亿参数的大型语言模型,支持指令跟随和对话任务。
Mungert
PokeeResearch-7B是由Pokee AI开发的70亿参数深度研究代理模型,结合了AI反馈强化学习(RLAIF)和强大的推理框架,能够在工具增强的大语言模型中实现可靠、对齐和可扩展的研究级推理,适用于复杂的多步骤研究工作流程。
unsloth
Apertus是一款由瑞士AI开发的全开放多语言大语言模型,提供70亿和80亿两种参数规模。该模型支持超过1000种语言,使用完全合规且开放的训练数据,性能可与闭源模型相媲美。Apertus在15T标记上进行预训练,采用分阶段课程训练方法,支持长达65,536个标记的上下文长度。
inclusionAI
LLaDA-MoE是基于扩散原理构建的新型混合专家语言模型,是首个开源的MoE扩散大语言模型,在约20万亿个标记上从头预训练,总参数70亿,推理时仅激活14亿参数,在代码生成和数学推理等任务中表现卓越。
Frane92O
本模型是Qwen2.5-Omni-7B的GGUF量化版本,使用llama.cpp工具从原始模型转换而来。Qwen2.5-Omni-7B是一个70亿参数的多模态大语言模型,支持文本、图像、音频等多种模态的输入和输出。
quantized4all
OpenCodeReasoning-Nemotron-1.1-7B是基于Qwen2.5-7B-Instruct开发的70亿参数大型语言模型,专门针对代码生成和推理任务进行后训练优化。该模型支持64k标记的上下文长度,在竞争性编程任务中表现出色,在LiveCodeBench评估中达到55.5%的一次通过率。
ByteDance-Seed
BAGEL是一个开源的、拥有70亿活跃参数的多模态基础模型,训练于大规模交错多模态数据,在理解和生成任务上表现优异。
Featherless-Chat-Models
Mistral-7B-v0.1是一个拥有70亿参数的预训练生成式文本大语言模型,在多项基准测试中表现优于Llama 2 13B模型。它采用了先进的Transformer架构设计,包括分组查询注意力和滑动窗口注意力机制。
EQUES
JPharmatron-7B是一款专为制药应用和研究设计的70亿参数大语言模型,能在制药文书和研究领域发挥重要作用。
JPharmatron-7B-base是一个70亿参数的日语和英语大语言模型,专为制药应用和研究设计。
ALLaM-AI
ALLaM是由沙特数据与人工智能管理局(SDAIA)开发的阿拉伯语言技术大语言模型,支持阿拉伯语和英语,采用完全从头训练模式,具有70亿参数。
scb10x
Typhoon2-Qwen2.5-7B-Instruct是一款基于Qwen2.5-7B开发的70亿参数泰语指令大语言模型,具备强大的指令跟随能力和多领域处理能力,支持长达128k的上下文处理。
openGPT-X
Teuken 7B-base-v0.6是一个拥有70亿参数的多语言大语言模型,在OpenGPT-X研究项目中基于6万亿个标记进行了预训练。该模型专为欧盟24种官方语言的私有、非商业、研究和教育用途设计,能在多语言环境中提供稳定的性能。
sapienzanlp
Minerva是由Sapienza NLP开发的意大利语-英语双语大语言模型,基于Mistral架构,拥有70亿参数,支持指令跟随和对话任务。
Teuken-7B-instruct-commercial-v0.4 是一款经过指令调优的70亿参数多语言大语言模型,支持欧盟24种官方语言,专为商业和研究场景设计。
nectec
PathummaLLM-text-1.0.0-7B 是一个支持泰语、中文和英语的70亿参数大语言模型,基于OpenThaiLLM-Prebuilt进行指令微调,优化了RAG、约束生成和推理任务。
NLPnorth
SnakModel是一款专为丹麦语设计的70亿参数大语言模型,基于Llama 2架构,由哥本哈根IT大学开发。
openthaigpt
OpenThaiGPT 7b 1.5 Instruct是基于Qwen v2.5的先进泰语聊天模型,拥有70亿参数。它在超200万条泰语指令对上微调,能精准回答泰语领域问题,在各类泰语考试中相比其他开源泰语大语言模型取得了最高的平均分数。
Teuken-7B-instruct-research-v0.4是一个经过指令微调的70亿参数多语言大语言模型,支持24种欧盟官方语言,专注于欧洲价值观和多语言任务场景。
 TransformersOther
TransformersOther%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)