腾讯搜狗输入法发布20.0版本,宣布全面AI化,从工具升级为智能助手。新版本基于大模型重塑交互逻辑,在语音、打字、翻译三大高频场景实现底层技术升级,核心提升在于更准、更快、更聪明。
腾讯搜狗输入法发布20.0.0纪念版,全面AI化升级。依托腾讯混元大模型,重点提升AI语音、翻译和打字功能。AI语音识别延时降低40%,准确率达98%,方言识别准确率提升30%。
京东科技与乐奇Rokid合作推出全球首款智能眼镜购物应用JoyGlance,结合AI大模型与光波导技术,实现语音交互购物,简化用户操作。
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://app.aibase.com/zh1、淘宝天猫出重拳!新版Siri将支持语音与文本双输入,并集成于iOS27及其全线操作系统中,同时借助谷歌Gemini模型提升性能。
Voiceley可免费快速进行AI语音克隆,还能使用语音模型生成语音。
免费、超快速、高准确率且支持多语言的语音打字应用,由Whisper提供支持
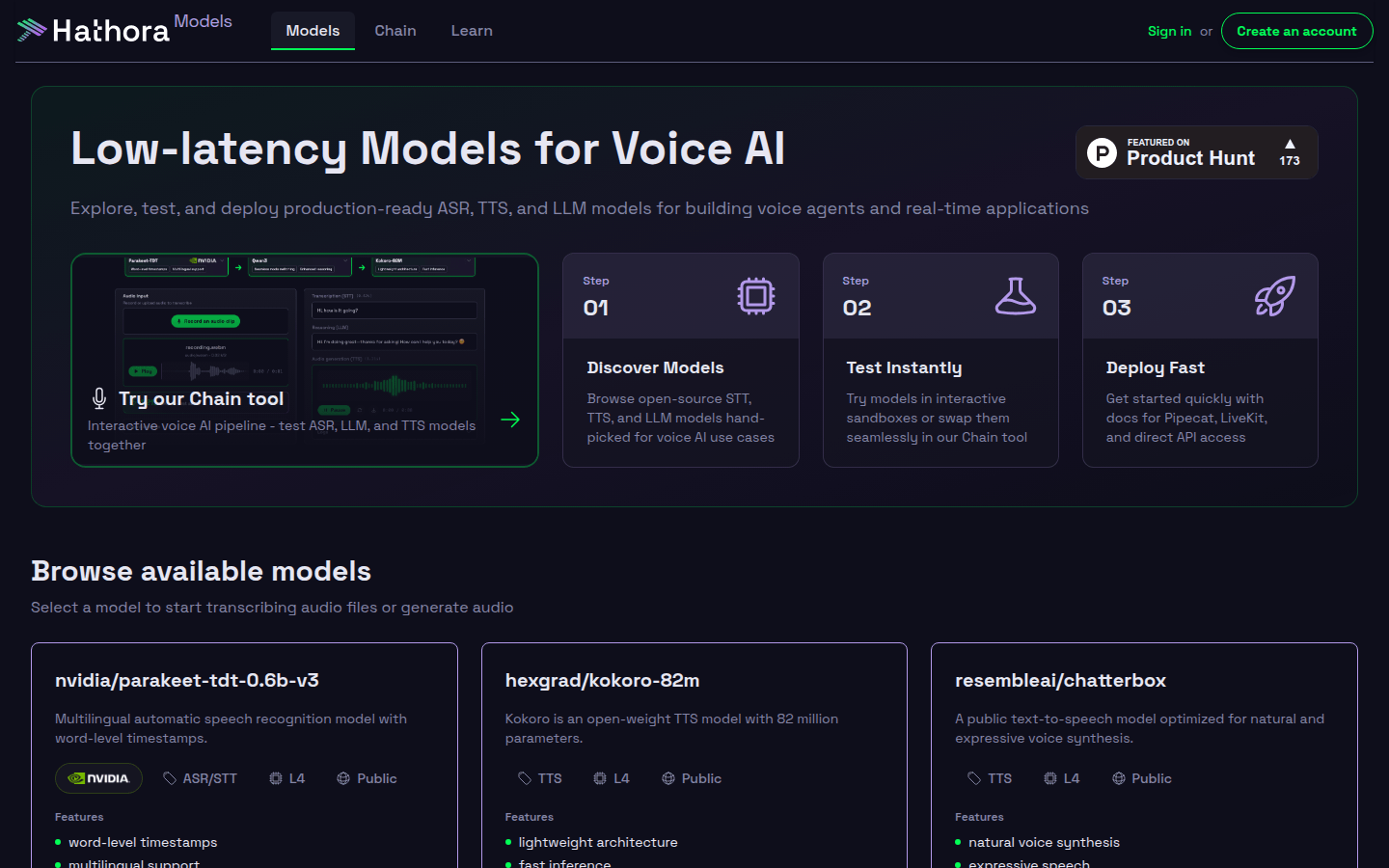
提供语音AI的ASR、TTS和LLM模型,可测试部署用于实时应用。
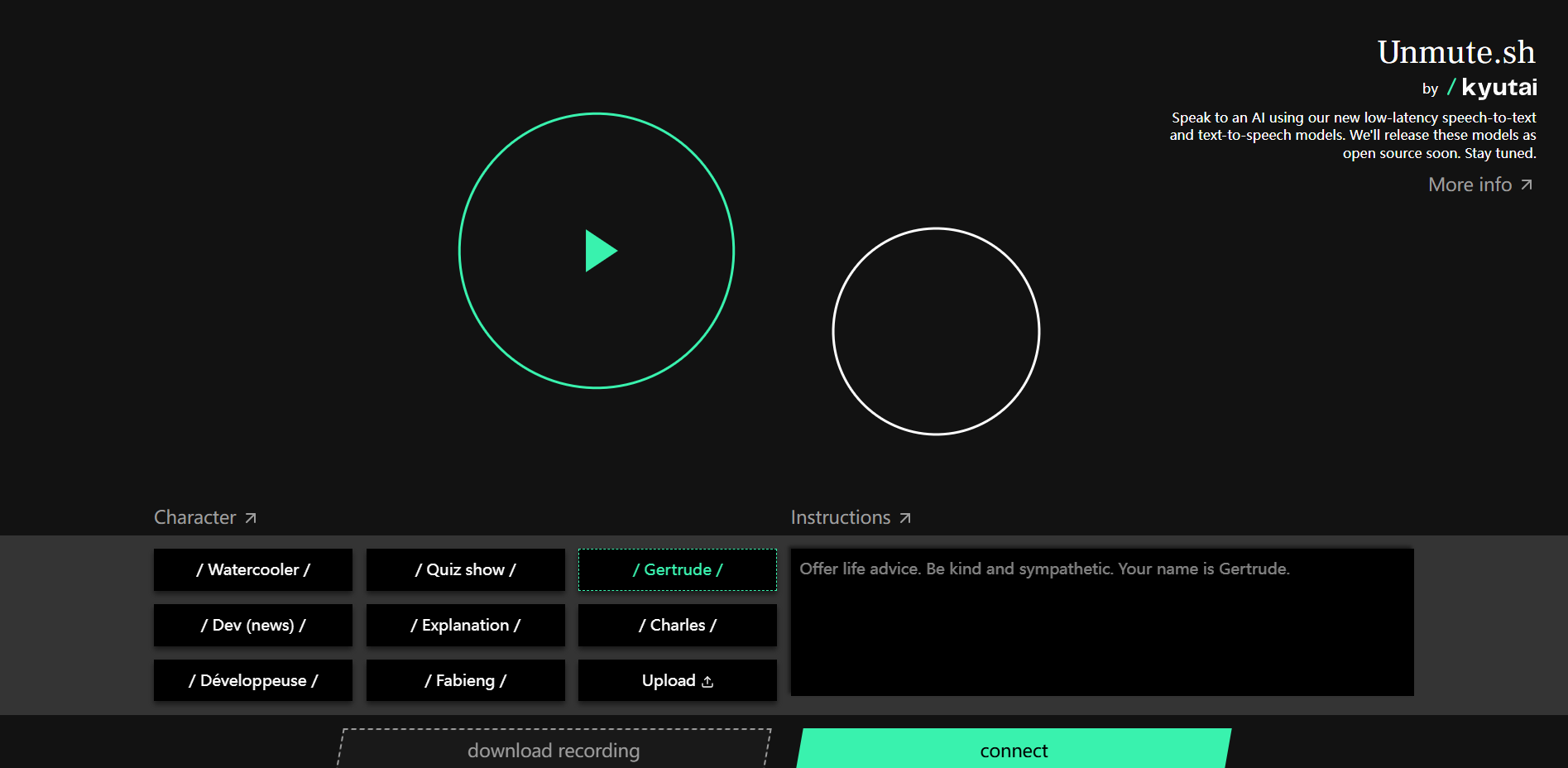
使用低延迟语音识别和合成模型与 AI 对话。
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$4
$16
$1
$10
256
Baidu
128
$6
$24
$2
$20
pnnbao-ump
VieNeu-TTS是首个可在个人设备上运行的越南语文本转语音模型,具备即时语音克隆能力。基于NeuTTS Air微调,能够生成自然逼真的越南语语音,在CPU上具备实时性能。
TheStageAI
TheWhisper-Large-V3-Turbo 是 OpenAI Whisper Large V3 模型的高性能微调版本,由 TheStage AI 针对多平台实时、低延迟和低功耗语音转文本推理进行优化。支持流式转录、单词时间戳和可扩展性能,适用于实时字幕、会议和设备端语音界面等场景。
TheWhisper-Large-V3是OpenAI Whisper Large V3模型的高性能微调版本,由TheStage AI针对多平台(NVIDIA GPU和Apple Silicon)的实时、低延迟和低功耗语音转文本推理进行了优化。
nineninesix
KaniTTS是一款专为实时对话式AI应用优化的高速、高保真文本转语音模型,采用两阶段管道结合大型语言模型和高效音频编解码器,实现卓越的速度和音频质量。该模型支持西班牙语,具有4亿参数,采样率为22kHz。
KaniTTS是一款专为实时对话式人工智能应用优化的高速、高保真阿拉伯语文本转语音模型。它采用两阶段流水线架构,结合大语言模型与高效音频编解码器,实现卓越的速度和音频质量,能够满足对话式AI、无障碍辅助、研究等多领域的语音合成需求。
KaniTTS是一款专为实时对话式AI应用优化的高速、高保真文本转语音模型,通过独特的两阶段架构结合大语言模型与高效音频编解码器,实现低延迟与高质量语音合成,实时因子低至0.2,比实时速度快5倍。
KaniTTS是一款专为实时对话式AI应用优化的高速、高保真文本转语音模型。它采用两阶段流水线架构,结合大语言模型和高效音频编解码器,实现了卓越的速度和音频质量,支持多种语言并适用于边缘/服务器部署。
neuphonic
NeuTTS Air是世界上首个具备即时语音克隆功能的超逼真、端侧文本转语音(TTS)语言模型。基于0.5B参数的大语言模型骨干构建,能为本地设备带来自然的语音、实时性能、内置安全性和说话人克隆功能。
NeuTTS Air是全球首个具有即时语音克隆功能的超逼真设备端文本转语音模型,基于0.5B参数的大语言模型骨干构建,能在本地设备上实现自然语音生成、实时性能和说话人克隆功能。
NeuTTS Air是世界上首个具备即时语音克隆功能的超逼真、设备端文本转语音(TTS)语言模型。基于0.5B大语言模型骨干网络构建,能为本地设备带来自然的语音、实时性能、内置安全功能和说话人克隆能力。
UsefulSensors
Moonshine Tiny是由Moonshine AI(原有用传感器公司)开发的轻量级越南语自动语音识别模型,仅有27M参数,专为资源受限平台设计,在Fleurs和Common Voice 17数据集上表现出色。
webbigdata
VoiceCore是一款可商用的日语语音AI代理模型,专注于让AI通过语音与人类进行自然交流,具备情感表达和非语言声音能力,支持多种语音风格选择。
ai4bharat
基于Wav2Vec2架构的印地语自动语音识别模型,由AI4Bharat开发
FreedomIntelligence
Soundwave是一款突破语音与文本界限的语音转文本模型,仅通过1万小时数据训练就在语音翻译和AIR-Bench语音任务中展现出卓越性能。
jiviai
AudioX是由Jivi AI开发的多语言自动语音识别模型,针对印度语言优化,支持印地语、古吉拉特语和马拉地语。
speechbrain
这是一个基于25000小时英文语音数据集训练的大规模自动语音识别模型,采用Conformer架构,由三星AI剑桥中心贡献。模型参数量达4.8亿,在多个测试集上表现出色,验证集WER为6.8%,测试集WER为7.5%。
AudioX是由Jivi AI开发的多语言自动语音识别模型,专门针对印度南方语言优化,支持泰米尔语、泰卢固语、卡纳达语和马拉雅拉姆语。
AiLab-IMCS-UL
基于whisper-large-v3微调的拉脱维亚语自动语音识别模型,由AiLab.lv训练,支持拉脱维亚语语音转文本任务。
Paranchai
基于 airesearch/wav2vec2-large-xlsr-53-th 微调的语音情感识别模型,在评估集上达到85.79%准确率
基于airesearch/wav2vec2-large-xlsr-53-th微调的泰语语音情感识别模型,支持愤怒、快乐、平静三种情感分类
mcp-hfspace是一个连接Hugging Face Spaces的MCP服务器,支持图像生成、语音处理、视觉模型等多种AI功能,简化了与Claude Desktop的集成。
一个基于Whisper模型的语音录制和转录MCP服务器,可作为Goose AI扩展或独立服务运行。
一个基于Whisper模型的语音录制和转录MCP服务器,可作为Goose AI扩展或独立运行,支持多种录音场景和模型配置。
TeamSpeak MCP是一个基于Model Context Protocol的服务器控制工具,专门用于让AI模型(如Claude)管理TeamSpeak语音服务器。它提供39种功能工具,涵盖用户管理、频道控制、权限配置等全方位操作,支持多种部署方式(PyPI/Docker/本地),实现自动化TeamSpeak管理。
TeamSpeak MCP是一个基于Model Context Protocol的服务,用于通过AI模型(如Claude)控制TeamSpeak服务器,提供全面的频道管理、用户权限控制、语音调节等功能。
一个基于ClickSend API的MCP服务器,提供短信发送和文本转语音电话功能,支持AI模型程序化操作通讯服务。
基于大模型的智能对话机器人项目,支持多平台接入和多种AI模型,具备文本、语音、图像处理及插件扩展能力,可定制企业AI应用。
MCP Server Whisper是一个基于OpenAI Whisper和GPT-4o模型的音频处理服务器,提供高级音频转录、格式转换、批量处理和文本转语音等功能,通过Model Context Protocol标准实现与AI助手的无缝交互。
MCP-hfspace是一个简化连接Hugging Face Spaces的服务器工具,支持图像生成、语音处理、视觉模型等多种AI功能,与Claude Desktop无缝集成。
ExotelMCP是一个模型上下文协议(MCP)服务器,提供Claude AI与Exotel通信API的无缝集成,支持短信、语音通话和快速音频工具服务。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)