The Dedu team uses the AI tool Claude Code to drive transformation in data warehouse development, significantly improving the efficiency of repetitive work. However, there are pain points in practical application: the 'AI memory' is insufficient, and long conversations are prone to forgetting the context, such as the units of important fields, affecting the accuracy of development.
When Moon Shadow released the Kimi K2.6 model, the unexpected surge in traffic caused users to experience queuing and functionality failures, affecting the promotion of the new model and the experience of existing users. Meanwhile, the system encountered errors when handling high-concurrency data, leading to incorrect deductions of user benefits.
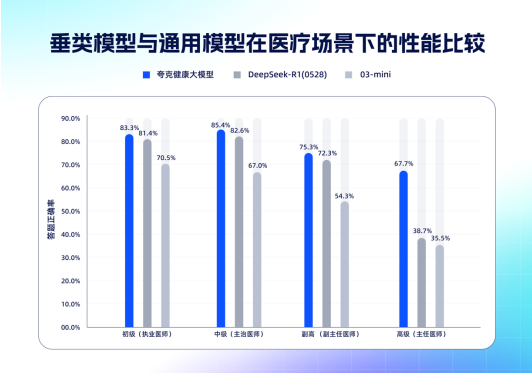
The夸克 Health Large Model has passed the written evaluation of 12 core medical disciplines by chief physicians in China, becoming the first large model to reach this level domestically. The model has been integrated into夸克AI Search, allowing users to access chief physician-level AI medical services through deep search. Its core breakthrough lies in establishing a slow-thinking capability, processing complex medical issues through chain reasoning and clinical deduction path modeling.夸克 adopts a dual data production line + dual reward mechanism training system, with a team of thousands of physicians labeling the data, including over 400 deputy chief physicians and above. The platform currently has more than 20 million monthly active medical student users.
Giant Network's social deduction game, 'Space Kill,' has officially integrated Tencent's HunYuan large language model. This innovative move marks a significant step in the exploration of AI-native gameplay within the gaming industry. Currently, 'Space Kill' has generated over 7 million AI players using this model. These virtual players will engage in intense battles with the game's 200 million real users, providing players with a completely new gaming experience.
sudeshmu
A 360-million-parameter language model based on the LLaMA architecture and using MoR (Mixture of Recursions) technology, fine-tuned on the FineWeb-Edu deduplicated dataset, achieving efficient text generation capabilities through a dynamic routing mechanism and recursive KV cache.
beetlware
A large Arabic logical reasoning model fine-tuned based on Qwen3-14B, optimized for Arabic logic and deductive reasoning while retaining general conversational capabilities.
Salesforce
E1-Math-1.5B is a language model fine-tuned based on DeepSeek-R1-Distilled-Qwen-1.5B, supporting elastic reasoning and the GRPO method, suitable for budget-constrained deduction scenarios.
prithivMLmods
Nu2-Lupi-Qwen-14B is a mathematical reasoning optimized model based on the Qwen 2.5 14B architecture, excelling in complex problem-solving and logical deduction.
OpenPipe
A model trained through reinforcement fine-tuning based on Qwen 2.5 32B Instruct, specifically designed to solve challenging deductive reasoning problems in the Temporal Clue dataset.
vngrs-ai
Kumru-2B is a lightweight, open-source large language model developed from scratch by VNGRS specifically for Turkish. This model was pre-trained on 300 billion tokens from a 500GB cleaned and deduplicated Turkish corpus. It is equipped with a modern tokenizer optimized for Turkish, supports code, math, and chat templates, and has a default native context length of 8192 tokens.
ArliAI
Llama-3.1-8B-ArliAI-RPMax-v1.1 is a variant model based on Meta-Llama-3.1-8B, focusing on creative writing and role-playing tasks. This model is trained on a carefully curated diverse dataset, emphasizing deduplication and creativity. It can adapt to various roles and scenarios and has a highly non-repetitive characteristic.
teddylee777
A Korean language model continuously pre-trained on the Llama-3-8B framework, trained with over 60GB of deduplicated text data
beomi
A Korean language model based on continued pre-training of Llama-3-8B, trained on 60GB+ deduplicated publicly available text, supporting Korean and English.
A Korean language model continuously pre-trained based on Llama-3-8B, using over 60GB of deduplicated publicly available text for training, supporting Korean and English text generation.
dell-research-harvard
This is a LinkTransformer model based on the Sentence Transformers framework, specifically designed for record linkage (entity matching) tasks, supporting operations such as clustering, deduplication, and linking.
PygmalionAI
An instruction fine-tuned model developed based on the deduplicated version of Pythia 1.4B, specializing in novel creation and dialogue generation
openaccess-ai-collective
Manticore 13B Chat is a chat conversation model optimized based on the Manticore model. It is trained using a deduplicated subset of the Pygmalion dataset and uses a pure chat-style prompt format, supporting role-playing and various dialogue tasks.
lambdalabs
An instruction generation model fine-tuned on the deduplicated version of Pythia-2.8B, optimized for synthetic instruction datasets
EleutherAI
Pythia-12B-deduped is a large language model with 12B parameters developed by EleutherAI, designed specifically for interpretability research and trained on the deduplicated Pile dataset.
Pythia-1B Deduplicated is a language model developed by EleutherAI specifically for interpretability research, trained on the deduplicated Pile dataset using Transformer architecture with 1 billion parameters
Pythia-70M-deduped is the smallest model in the Pythia scalable suite developed by EleutherAI, with 70 million parameters. This model is trained on the deduplicated Pile dataset and is specifically designed for interpretability research of language models. It provides 154 training checkpoints for scientific research.
Pythia-1.4B-deduped is a 1.2 billion parameter deduplicated version language model developed by EleutherAI and is part of the Pythia interpretability research suite. This model is trained on the globally deduplicated Pile dataset and is specifically designed for scientific research, with performance comparable to models of the same scale.
The Pythia Scaling Suite is a series of language models developed by EleutherAI, specifically designed to promote interpretability research. This suite includes 8 models of different scales, and each scale has two versions trained on the original Pile dataset and the deduplicated dataset. All models are trained on the exact same data in the same order, facilitating comparative research.
Ashishkr
Evaluates the normality of sentences by checking grammatical correctness and completeness. It is case-sensitive and deducts points for grammatical and case errors.
The remote MCP server provided by Jina AI offers functions such as web content extraction, web search, academic search, image search, query expansion, document re - sorting, and deduplication through the Reader, Embeddings, and Reranker APIs.
The remote MCP server provided by Jina AI implements functions such as web content extraction, web search, academic search, image search, text and image deduplication through various API tools.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)