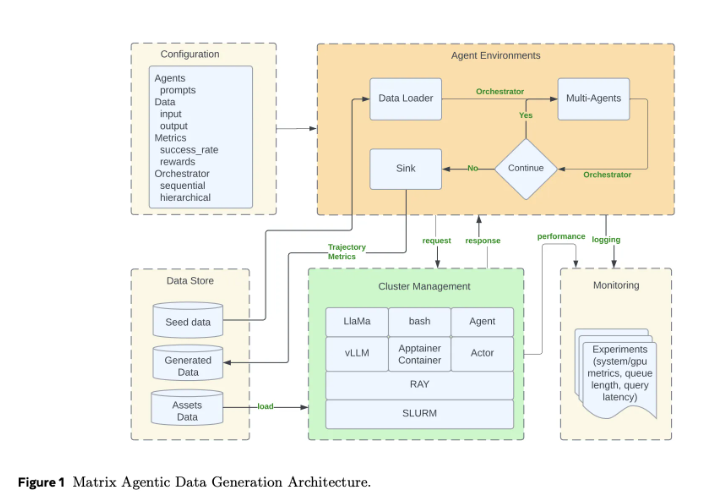
Meta AI推出Matrix框架,通过去中心化设计解决合成数据调度瓶颈。它将控制与数据流序列化为消息,分布到不同队列处理,避免中心控制器浪费GPU资源、增加协调开销的问题,提升数据新鲜度和多样性。
OpenAI与谷歌同步削减AI服务免费额度:Sora视频生成降至每日6段,超限需付费;谷歌Nano Banana Pro图片生成从3张减至2张。两家均保留随时再降权限,仅付费订阅暂未调整。反映GPU资源紧张加剧。
OpenAI与AWS签署价值380亿美元、为期七年的合作协议,将获得数十万台英伟达GPU计算资源,托管于亚马逊全球数据中心。此举强化了OpenAI在AI领域的基础设施布局,超越传统云服务租赁模式。
OpenAI视频生成应用Sora上线一月引爆全球,因用户激增与算力压力,项目负责人宣布将逐步减少每日30次免费额度,推出付费选项与创作者分成计划,标志其正式迈入商业化阶段。免费额度收缩是GPU资源告急下的必然选择。
使用云 GPU 资源在本地 ComfyUI 上运行您的工作流程
Run:ai为AI和深度学习工作负载优化和编排GPU计算资源。
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
-
Bytedance
$0.8
$2
128
Alibaba
$0.4
$8.75
$70
400
$1.75
$14
$0.35
64
$0.63
$3.15
131
Chatglm
$1.8
$5.4
16
Tencent
32
$0.3
$0.5
224
$17.5
$56
Downtown-Case
GLM-4.5-Base是一款经过量化处理的文本生成模型,基于zai-org/GLM-4.5-Base模型进行优化,专门为128GB内存搭配小型GPU的设备设计。采用ik_llama.cpp的新型IQ2_KL量化方法,在保持性能的同时显著降低资源需求,适合文本生成任务。
QuantTrio
基于Qwen3技术的量化修复大语言模型,专为高效代码生成和编程任务设计。该模型采用AWQ量化技术,在保持高性能的同时显著降低计算资源需求,支持多GPU环境下的快速部署和推理。
Intel
这是一个基于DeepSeek-R1-0528-Qwen3-8B模型,使用Intel的AutoRound算法进行INT4量化的开源大语言模型。该模型在保持较高性能的同时,显著降低了模型大小和推理资源需求,适用于在CPU、Intel GPU或CUDA等设备上进行高效推理。
erfanvaredi
这是core42团队开发的jais-13b-chat的双重量化版本,旨在让GPU资源有限的设备也能运行该模型。
hivemind
这是EleutherAI GPT-J 60亿参数模型的8位量化版本,专为在有限GPU资源(如Colab或1080Ti)上运行和微调而优化。
Hyperbolic GPU MCP服务器是一个基于Node.js的工具,允许用户通过API管理和租用Hyperbolic云平台上的GPU资源,包括查看可用GPU、租用实例、SSH连接及运行GPU工作负载等功能。
一个MCP服务器,用于在Google Colab的GPU运行时(T4/L4)上分配资源并执行Python代码,使AI助手能够远程运行GPU加速的计算任务。
 GgufMultiple Languages
GgufMultiple Languages%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)