AR glasses use MLLM-SC framework for semantic processing, generating attention heatmaps in 10ms to prioritize key targets and reduce background data. The system filters task-relevant multimodal data, optimizes transmission, frees 30% of 6G bandwidth, and enhances device-edge server collaboration for improved efficiency.....
Warner Bros. Discovery uses AWS Graviton processors and Amazon SageMaker AI instances to optimize AI/ML infrastructure, achieving cost savings and performance improvements for personalized content experiences.....
Kimi Linear, a hybrid linear attention architecture by Moon AI, outperforms traditional methods in long/short-range processing and reinforcement learning. It uses Kimi Delta Attention with gating to enhance RNN memory efficiency, combining three KDA and one MLA.....
OpenAI partners with MLK estate to regulate Sora's use of Dr. King's image, suspending disrespectful content generation per request to enhance historical figure protection.....
A tool designed for AI/ML model monitoring and management.
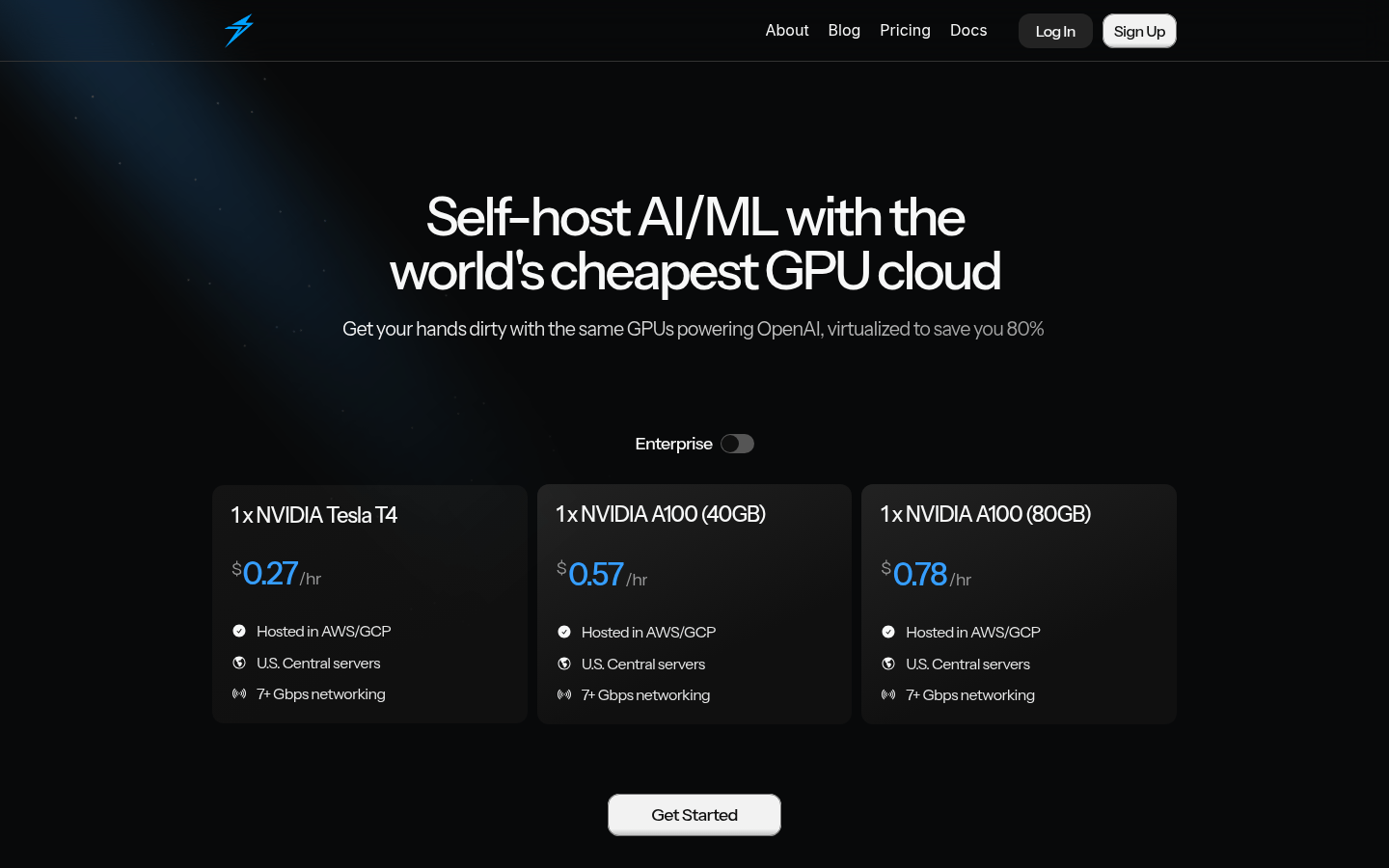
Provides the world's cheapest GPU cloud services, empowering self-hosted AI/ML development.
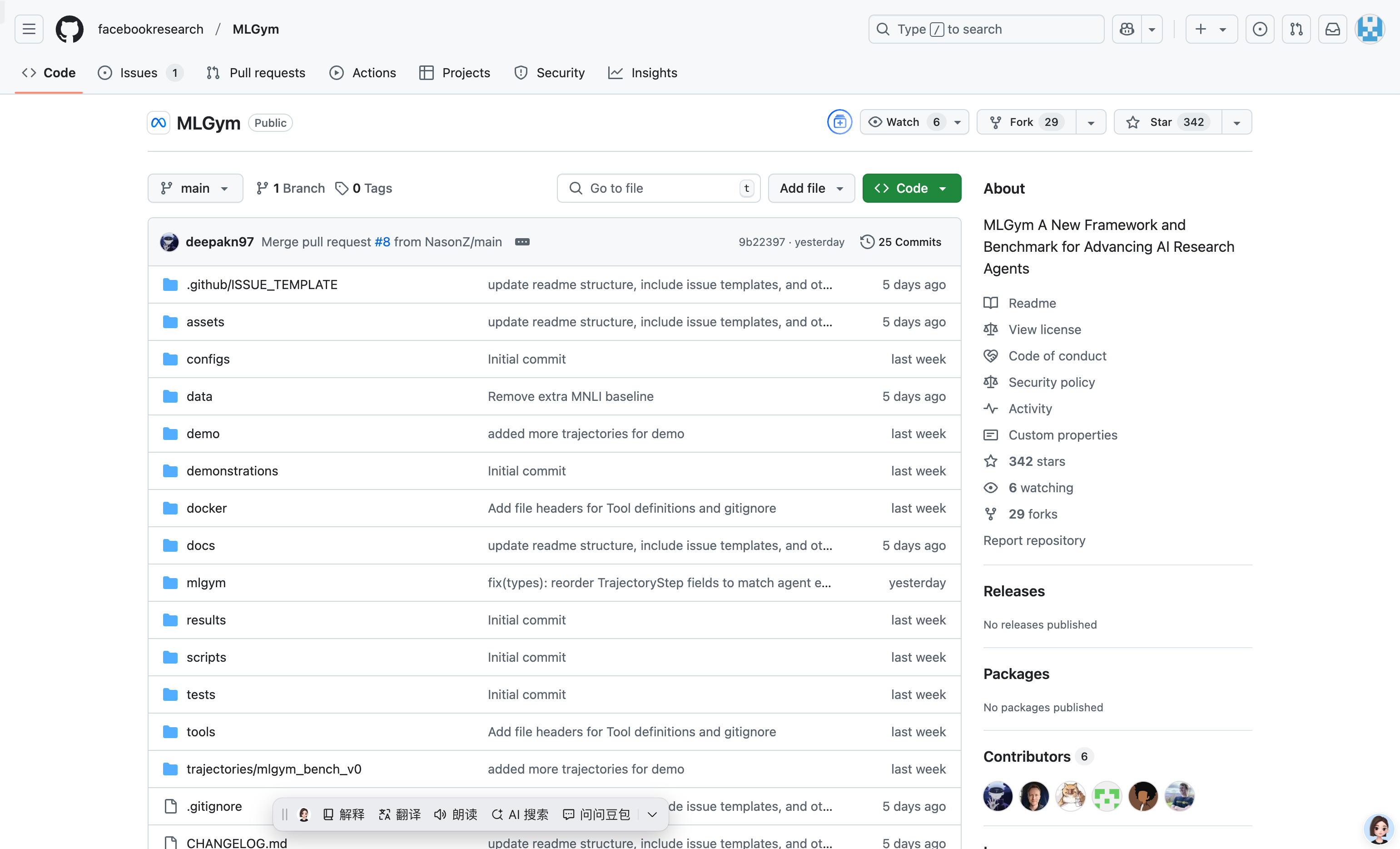
MLGym is a novel framework and benchmark for advancing AI research agents.
FlashMLA is a high-efficiency MLA decoding kernel optimized for Hopper GPUs, suitable for variable-length sequence services.
ai-sage
GigaChat3-10B-A1.8B is an efficient dialogue model in the GigaChat series. Based on the Mixture-of-Experts (MoE) architecture, it has a total of 10 billion parameters and 1.8 billion active parameters. It adopts the innovative Multi-head Latent Attention (MLA) and Multi-token Prediction (MTP) technologies, aiming to optimize inference throughput and generation speed. The model is trained on 20T tokens of diverse data and supports 10 languages including Chinese, suitable for dialogue scenarios requiring quick responses.
mlx-community
This model is an MLX format conversion version of the Ministral-3-3B-Instruct-2512 instruction fine-tuning model released by Mistral AI. It is a large language model with a parameter scale of 3B, specifically optimized for following instructions and dialogue tasks, and supports multiple languages. The MLX format enables it to run efficiently on Apple Silicon devices.
This model is an MLX format conversion version of Kimi-Linear-48B-A3B-Instruct, optimized for Apple Silicon devices such as the Apple Mac Studio. It is a large language model with 48 billion parameters, supporting instruction following and suitable for local inference and conversation tasks.
ExaltedSlayer
Gemma 3 is a lightweight open-source multimodal model launched by Google. This version is an instruction-tuned quantization-aware training model with 12B parameters, which has been converted to the MXFP4 format of the MLX framework. It supports text and image input and generates text output, with a 128K context window and support for over 140 languages.
kyr0
This is an automatic speech recognition model optimized for Apple silicon chip devices. By converting to the MLX framework and quantizing to the FP8 format, it enables fast on-device speech transcription on Apple devices. The model is fine-tuned for verbatim accuracy and is particularly suitable for scenarios requiring high-precision transcription.
ubergarm
This is the GGUF quantized version of the ai-sage/GigaChat3-10B-A1.8B-bf16 model, offering a variety of quantization options, from high-precision Q8_0 to extremely compressed smol-IQ1_KT, to meet the deployment requirements under different hardware conditions. This model supports a 32K context length, adopts the MLA architecture, and is optimized for dialogue scenarios.
This model is an 8-bit quantized version converted from allenai/Olmo-3-7B-Instruct, specifically optimized for the Apple MLX framework. It is a large language model with 7 billion parameters, supporting instruction following and dialogue tasks.
The 4-bit quantized version of VibeThinker-1.5B, optimized for Apple chips based on the MLX framework, is a dense language model with 1.5 billion parameters, specifically designed for mathematical reasoning and algorithm coding problems.
GigaChat3-10B-A1.8B-base is the basic pre-trained model of the GigaChat series, adopting the Mixture of Experts (MoE) architecture with a total of 10 billion parameters and 1.8 billion active parameters. The model integrates Multi-Head Latent Attention (MLA) and Multi-Token Prediction (MTP) technologies, and has the advantage of high throughput during inference.
McG-221
This model is an MLX format model converted from summykai/gemma3-27b-abliterated-dpo using version 0.28.3 of mlx-lm. It is a 27B parameter Gemma 3 large language model fine-tuned with DPO (Direct Preference Optimization), optimized for efficient operation on Apple Silicon (MLX framework).
inferencerlabs
Kimi - K2 - Thinking 3.825bit MLX is a quantized model for text generation. It achieves different perplexity performances in tests through different quantization methods. Among them, q3.825bit quantization can reach a perplexity of 1.256.
This model is an MLX format conversion version of the instruction fine-tuned version of Falcon-H1-34B-Instruct, optimized specifically for Apple Silicon (M series chips). It is based on the original Falcon-H1-34B-Instruct model and converted to an 8-bit quantization format compatible with the MLX framework through the mlx-lm tool, aiming to achieve efficient local inference on macOS devices.
Ali-Yaser
This model is a fine-tuned version based on meta-llama/Llama-3.3-70B-Instruct. It is trained using the mlabonne/FineTome-100k dataset, which contains 100k token data. The model is fine-tuned using the Unsloth and Huggingface TRL libraries and supports English language processing.
Leohan
A text generation model developed based on the MLX library, focusing on natural language processing tasks and providing developers with an efficient text generation solution.
A text generation model implemented based on the MLX library, supporting inference in multiple quantization methods, with distributed computing capabilities, and can run efficiently in the Apple hardware environment.
Kimi-K2-Thinking is a large language model in MLX format converted by mlx-community from the original model of moonshotai. The conversion is carried out using version 0.28.4 of mlx-lm, retaining the chain of thought reasoning ability of the original model.
Marvis-AI
This is a text-to-speech model optimized based on the MLX framework, converted from the original model Marvis-AI/marvis-tts-100m-v0.2. It uses 6-bit quantization technology and is specifically optimized for Apple Silicon hardware, providing efficient speech synthesis capabilities.
Qwen3-Coder-480B-A35B-Instruct is a large code generation model with 480 billion parameters, supporting 8.5-bit quantization and optimized based on the MLX framework. This model is specifically designed for code generation tasks and can run efficiently on devices with sufficient memory.
catalystsec
This project performs 4-bit quantization on the MiniMax-M2 model using the DWQ (Dynamic Weight Quantization) method with the help of the mlx-lm library. This model is a lightweight version of MiniMax-M2, significantly reducing the model size while maintaining good performance.
This is a 6-bit quantized version converted from the Kimi-Linear-48B-A3B-Instruct model, optimized for the Apple MLX framework. The model retains the powerful instruction-following ability of the original model, while significantly reducing storage and computational requirements through quantization technology, making it suitable for efficient operation on Apple hardware.
An audio transcription MCP service based on MLX Whisper, supporting transcription of local files, Base64 audio, and YouTube videos, optimized for Apple M-series chips.
The MCP server of MLflow Prompt Registry enables access to and management of prompt templates from MLflow.
An MCP service implementation based on the Balldontlie API, providing query functions for player, team, and game information in the NBA, NFL, and MLB.
A server project based on the Model Context Protocol (MCP) that provides access to baseball statistical data through the MLB Stats API and the pybaseball library, including data sources such as Statcast, Fangraphs, and Baseball Reference, and supports data visualization.
PromptLab is an intelligent system that optimizes basic user queries into AI system prompts through MLflow integration, providing dynamic template matching and parameter extraction functions.
A server project compatible with the MCP protocol, providing atomic-scale simulation functions through ASE, pymatgen, and machine learning interatomic potentials (MLIPs). It is currently under active development.
A Python - based ML model provenance management service built with FastAPI and SQLAlchemy, providing functions such as dataset management, entity tracking, activity logging, proxy management, and provenance relationship tracking.
This project provides a natural language interaction interface for MLflow through the Model Context Protocol (MCP), allowing users to query and manage machine learning experiments and models in English. It includes server - side and client - side components.
This project provides MCP protocol support services for the MLflow Prompt Registry, enabling the functions of retrieving and managing prompt templates from MLflow, and is mainly used for conveniently invoking preset prompts in Claude Desktop.
This project provides a Model Context Protocol (MCP) service for MLflow through a natural language interface, simplifying the management and query of machine learning experiments and models.
An MLB data service based on the MCP protocol, providing comprehensive access to baseball statistical data, including team standings, schedules, player information, etc., and supporting AI application integration.
Implementation of the MCP service for the MLflow Prompt Registry, supporting the retrieval and management of prompt templates from MLflow, facilitating users to quickly invoke preset workflows in Claude Desktop.
MCP Servers is a collection of servers and services for a Model Composition Platform (MCP), aiming to promote the integration and deployment of various AI/ML models and services. The project adopts a modular architecture, supporting standardized communication and scalable design, and includes various server types such as weather services.
The Cloudera ML Model Control Protocol (MCP) is a Python toolkit that provides functions for integrating with the Cloudera Machine Learning platform, including services such as file management, job scheduling, model management, and experiment tracking.
A document search assistant integrated with Claude AI. It enhances Claude's document retrieval capabilities through the MCP server and supports intelligent search and explanation of documents for multiple AI/ML libraries.
This project provides interaction functions for MLflow through a natural language interface. It includes server - side and client - side components, supports querying experiments, model registration, and system information, and simplifies MLflow management operations.
Project summary
An MLB data API encapsulation service based on the MCP framework, providing functions such as schedule query, game result query, team information query, and player query.
This is an MCP server based on FastAPI, providing baseball data query functions from MLB and Fangraphs through the pybaseball library, including player data, team statistics, and league leaderboards.
A secure MCP server implementation for executing controlled command-line operations, providing comprehensive security features, including command whitelisting, path validation, and execution control.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)