MiniMax推出新一代音乐生成模型Music2.0,凭借显著提升的音乐理解与表达能力,被形容为“会唱歌的制作人”。该模型能精准捕捉人声情绪和器乐动态,在声音表现力上实现关键突破,预示着音乐创作体验的重大变革。
MiniMax公司视频生成模型Hailuo2.3在Replicate平台上线,支持文本和图像输入生成高质量视频。该模型通过NCR架构提升训练效率,以逼真物理模拟和流畅动作捕捉能力,推动AI在电影、广告等领域的动态视觉效果创新。
苹果发布SlowFast-LLaVA模型,在长视频分析任务中表现优异,超越更大参数模型。其双流架构通过慢流捕捉静态细节,快流处理动态信息,有效解决传统逐帧处理的信息冗余和上下文窗口溢出问题,为长视频内容分析提供高效解决方案。
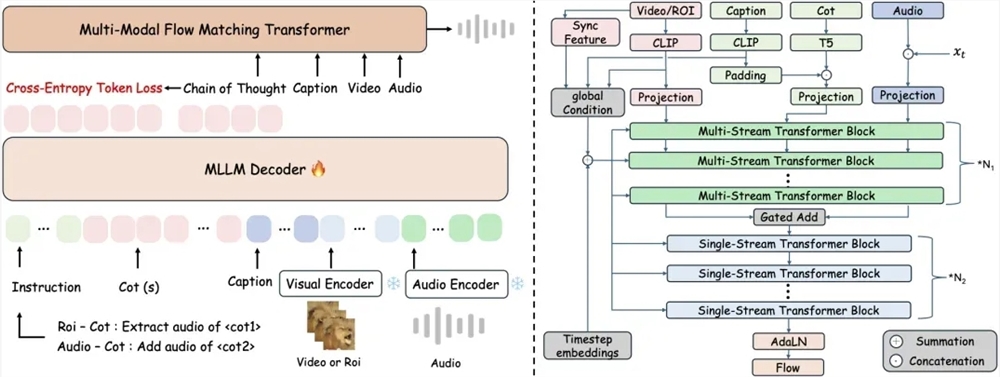
近日,阿里语音AI团队宣布开源全球首个支持链式推理的音频生成模型ThinkSound,该模型通过引入思维链(Chain-of-Thought)技术,突破传统视频转音频技术对画面动态捕捉的局限,实现高保真、强同步的空间音频生成。这一突破标志着AI音频技术从“看图配音”向“结构化理解画面”的跨越式发展。
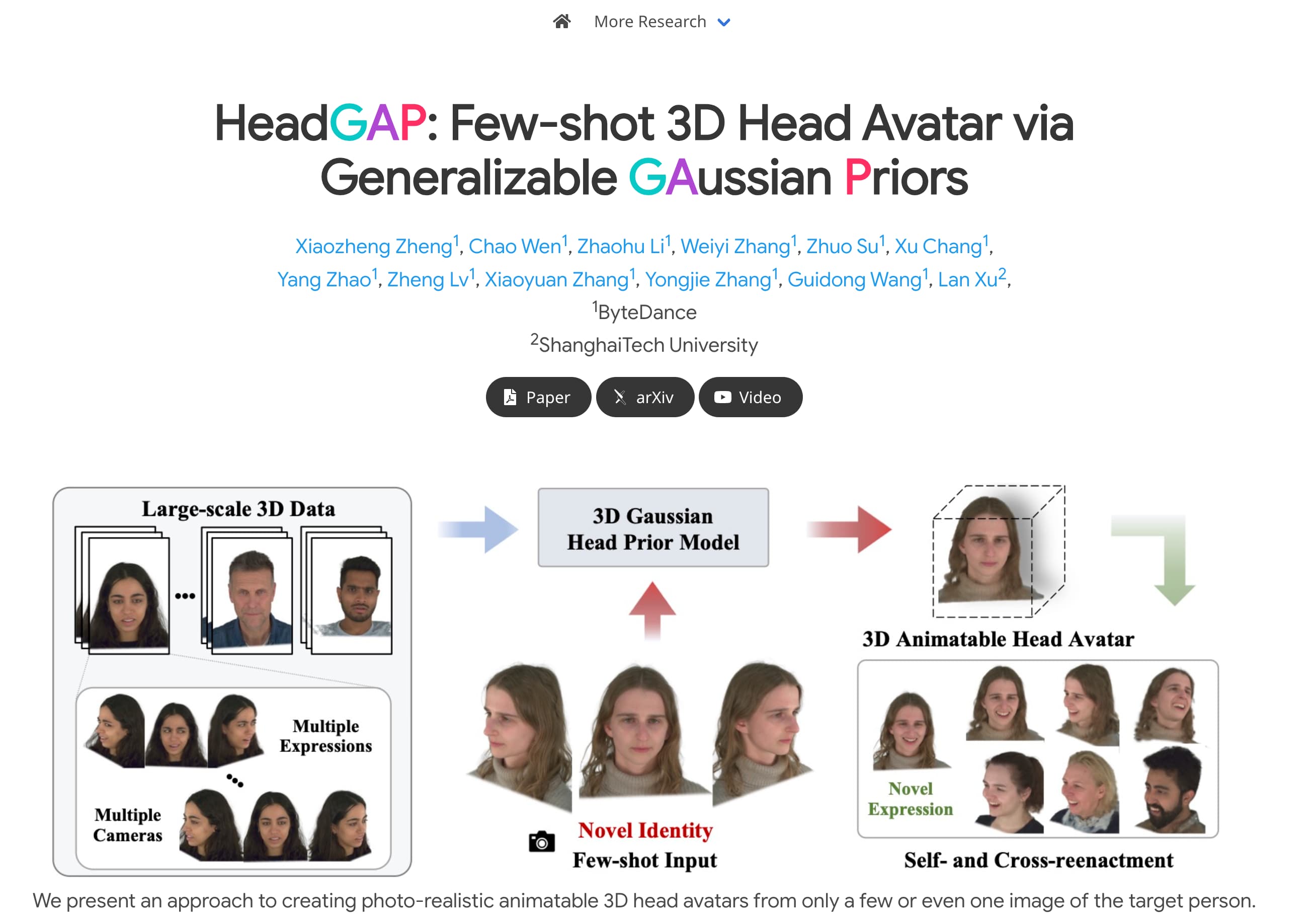
从单张图片创建逼真的3D头像
自由动态捕捉,释放想象
Openai
-
Input tokens/M
Output tokens/M
Context Length
Bytedance
Tencent
$1
$4
32
Alibaba
$2
$0.3
Google
$8.75
$70
1k
Anthropic
$21
$105
200
Stepfun
Baidu
$3
$9
128
Minimax
Moonshot
$10
$30
131
Chatglm
01-ai
Skywork
天工卷轴V1是首个开源的、以人物为核心的高级视频基础模型,基于混元视频框架,通过对千万级高质量影视片段进行微调,具备面部动态捕捉和电影级光影美学等核心优势。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)