蚂蚁灵波科技开源世界模型LingBot-World,在视频质量、动态程度等关键指标媲美Google Genie3,为具身智能、自动驾驶等领域提供高保真、可实时操控的“数字演练场”。
Medeo AI推出全新视频代理版本,以智能代理架构为核心,通过自然语言交互实现视频动态编辑与高效迭代,显著降低创作门槛,引发海外市场关注。
机器人公司1X发布“1X世界模型”AI模型,旨在让Neo人形机器人通过理解物理动态实现自主学习,超越预设程序。该模型结合视频数据与提示词,使机器人具备学习未训练任务的能力,推动商业化进程。
阅文集团与生数科技达成合作,将多模态视频生成大模型Vidu接入“阅文漫剧助手”,旨在高效转化网络文学IP为动态视觉内容,推动AIGC产业化发展。
将静态图像转换为动态视频的 AI 工具。
免费AI视频生成器,超1000模板,一键将照片转为动态视频
使用Wan AI技术和Wan 2.2动画模型,将静态图像无缝转化为动态视频。
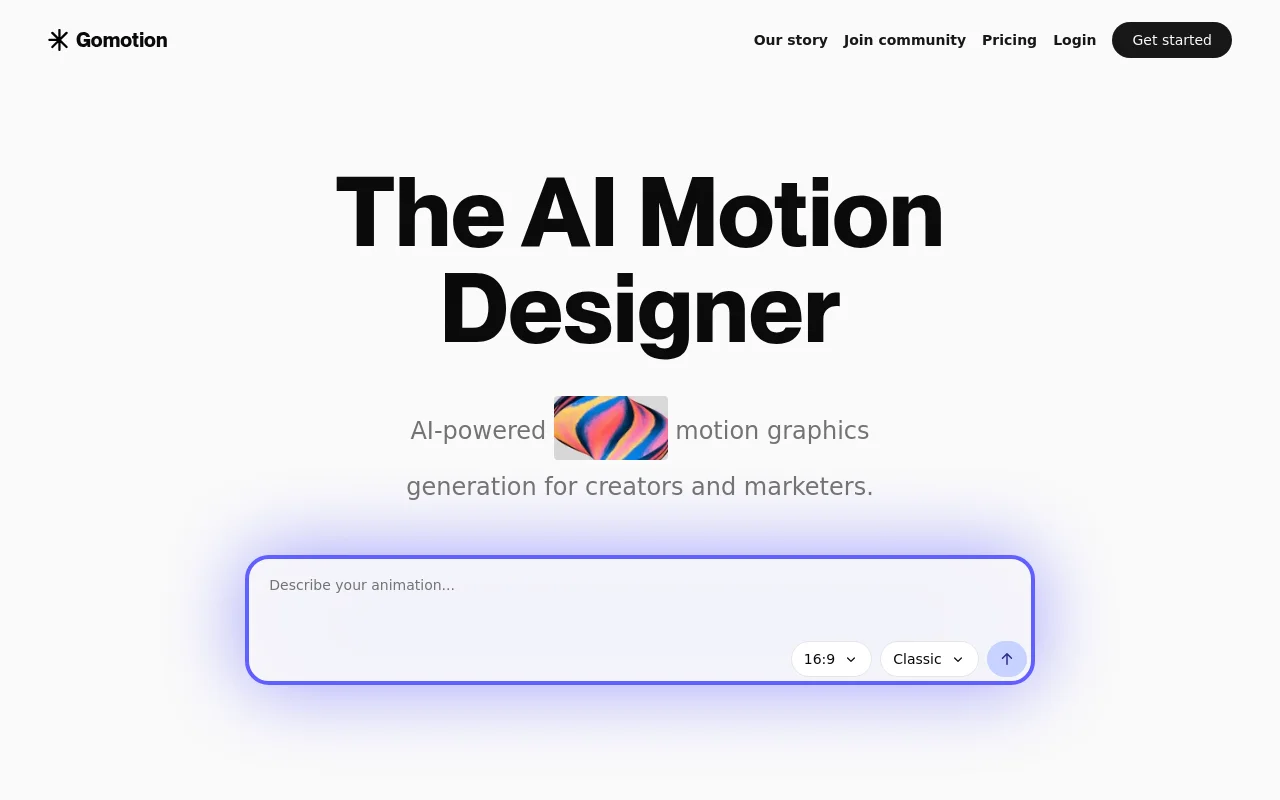
Gomotion是一个AI驱动的视频生成工具,可以从简单的文本提示中生成震撼的动态设计视频。
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
-
Google
$2.1
$17.5
Alibaba
$2
$20
$8
$240
52
$3.9
$15.2
64
$15.8
$12.7
Bytedance
$0.8
256
Baidu
Tencent
24
32
$0.3
unsloth
Qwen3-VL是通义系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力以及出色的智能体交互能力。
Qwen3-VL-32B-Thinking是Qwen系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文处理、空间和视频动态理解能力,以及出色的智能体交互能力。
Qwen3-VL-8B-Thinking是通义千问系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力,以及出色的智能体交互能力。
Qwen3-VL是通义系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力,以及出色的智能体交互能力。
Qwen3-VL是通义系列中最强大的视觉语言模型,在文本理解与生成、视觉感知与推理、上下文长度、空间和视频动态理解以及智能体交互能力等方面全面升级。该模型提供密集架构和混合专家架构,支持从边缘设备到云端的灵活部署。
Qwen3-VL是Qwen系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力,以及出色的智能体交互能力。
Qwen3-VL是Qwen系列中最强大的视觉语言模型,实现了全方位的综合升级,包括卓越的文本理解与生成能力、更深入的视觉感知与推理能力、更长的上下文长度、增强的空间和视频动态理解能力,以及更强的智能体交互能力。
Qwen3-VL是Qwen系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力,以及出色的智能体交互能力。该版本为2B参数的思考增强版,专门优化了推理能力。
Qwen
Qwen3-VL-30B-A3B-Thinking是通义系列中最强大的视觉语言模型,具备出色的文本理解和生成能力、深入的视觉感知和推理能力、长上下文支持、强大的空间和视频动态理解能力,以及智能体交互能力。
Qwen3-VL是通义系列中最强大的视觉语言模型,具备出色的文本理解和生成能力、深入的视觉感知和推理能力、长上下文支持、强大的空间和视频动态理解能力,以及智能体交互能力。本仓库提供GGUF格式权重,支持在CPU、GPU等设备上高效推理。
Qwen3-VL-32B-Instruct是通义系列中最强大的视觉语言模型,具备出色的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力,以及智能体交互能力。
Qwen3-VL-8B-Instruct是通义系列中最强大的视觉语言模型,具备卓越的文本理解和生成能力、深入的视觉感知和推理能力、长上下文支持以及强大的空间和视频动态理解能力。
Qwen3-VL-32B-Thinking是Qwen系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力,以及出色的智能体交互能力。
Qwen3-VL是迄今为止Qwen系列中最强大的视觉语言模型,在文本理解与生成、视觉感知与推理、上下文长度、空间和视频动态理解以及智能体交互能力等方面都进行了全面升级。该模型采用混合专家(MoE)架构,提供卓越的多模态处理能力。
Qwen3-VL是通义大模型系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力以及出色的智能体交互能力。该模型采用混合专家(MoE)架构,是增强推理的思维版。
Qwen3-VL是通义系列中最强大的视觉语言模型,在文本理解与生成、视觉感知与推理、上下文长度、空间和视频动态理解以及智能体交互能力等方面都进行了全面升级。该模型提供密集架构和混合专家架构,支持从边缘设备到云端的灵活部署。
bullerwins
Qwen3-VL是通义系列迄今为止最强大的视觉语言模型,实现了全面升级,包括卓越的文本理解与生成能力、更深入的视觉感知与推理能力、更长的上下文长度、增强的空间和视频动态理解能力,以及更强的智能体交互能力。
AI视频生成MCP服务器,支持文本和图像输入生成动态视频,提供多种参数控制和模型选择。
一个基于MCP协议的Manim动画生成服务器,可执行Manim脚本并返回渲染后的视频,支持动态生成动画并与Claude集成。
一个基于MCP协议的Manim动画生成服务器,可接收脚本并返回渲染后的视频,支持动态生成数学动画并与Claude集成。
 Transformers
Transformers%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)