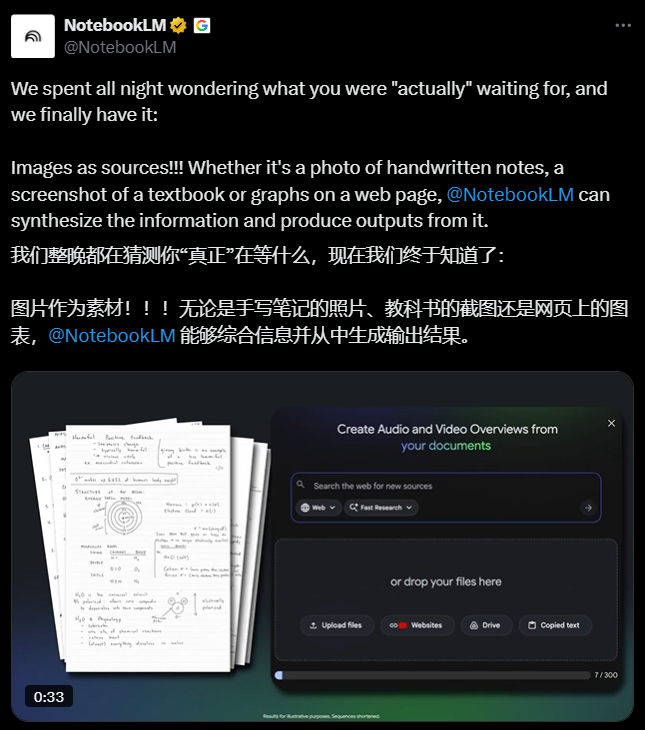
谷歌推出NotebookLM图像识别功能,支持上传板书、教材或表格图片,自动完成文字识别与语义分析,用户可直接用自然语言检索图片内容。该功能全平台免费,即将增加本地处理选项保护隐私。系统采用多模态技术,能区分手写与印刷体、解析表格结构,并与现有笔记智能关联。
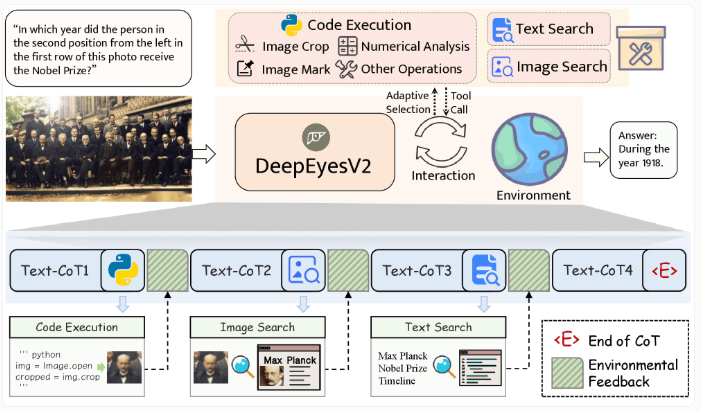
中国推出多模态AI模型DeepEyesV2,能分析图像、执行代码和网络搜索。它通过智能利用外部工具,而非依赖训练数据,性能超越大型模型。早期实验显示,仅靠强化学习无法稳定完成多模态任务,模型曾尝试编写Python代码分析图像但效果不佳。
马斯克宣布,下月起Grok将能每日处理约1亿条X平台帖子,涵盖文本、图像和视频内容。该系统基于先进算法,通过分析内容内在质量进行智能推荐,不受用户规模影响,旨在提升信息分发效率。
谷歌为Earth平台集成Gemini大模型,用户可通过自然语言对话实现地理推理,如识别风暴威胁、分析干旱风险。该功能基于地理空间推理模型,整合天气预报、卫星图像和人口数据等AI能力,提升交互效率。
AI技术解锁图像和视频的力量,无需编码,支持全球100多个组织使用。
Fixiol是一款利用先进AI技术分析屋顶图像、检测损坏、估算维修成本并生成专业报告的全能平台。
InternVL3开源:7种尺寸覆盖文、图、视频处理,多模态能力扩展至工业图像分析
一款AI视觉语言模型,提供图像分析和描述服务。
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
-
$4
$16
$1
$10
256
$2
$20
$6
$24
$8
$240
52
Bytedance
$1.2
$3.6
4
cyankiwi
ERNIE-4.5-VL-28B-A3B-Thinking AWQ - INT8是基于百度ERNIE-4.5架构的多模态大语言模型,通过AWQ量化技术实现8位精度,在保持高性能的同时大幅降低内存需求。该模型在视觉推理、STEM问题解决、图像分析等方面表现出色,具备强大的多模态理解和推理能力。
nvidia
NVIDIA-Nemotron-Nano-VL-12B-V2-FP8 是 NVIDIA 推出的量化视觉语言模型,采用优化的 Transformer 架构,在商业图像上进行了三阶段训练。该模型支持单图像推理,具备多语言和多模态处理能力,适用于图像总结、文本图像分析等多种场景。
Svngoku
Qwen3-VL-TimeTravel是基于Qwen3-VL-8B-Instruct模型,使用Unsloth库在MBZUAI/TimeTravel数据集上进行微调得到的版本。该模型专门用于生成历史文物图像的描述,在历史和文化文物分析方面具有专业能力。
ticoAg
Qwen3-VL-30B-A3B-Instruct-AWQ是Qwen3-VL系列的量化版本,具备强大的视觉语言处理能力,支持图像理解、视频分析、多模态推理等任务。该模型在文本理解、视觉感知、空间理解、长上下文处理等方面均有显著提升。
cpatonn
Apriel-1.5-15b-Thinker是ServiceNow开发的150亿参数多模态推理模型,具备文本和图像推理能力,性能可媲美比它大10倍的模型,在人工分析指数上获得52分,在企业领域基准测试中表现优异。
TIGER-Lab
Qwen2.5-VL-7B-Instruct是阿里巴巴通义千问团队开发的多模态视觉语言模型,基于70亿参数规模,专门针对视觉问答任务进行优化训练。该模型能够理解和分析图像内容,并生成准确的自然语言回答。
sabaridsnfuji
日本收据视觉语言模型lfm2-450M是一款专门用于理解和处理日本收据的视觉语言模型。它基于LiquidAI的LFM2-VL-450M基础模型构建,能够分析收据图像,提取结构化信息,回答关于收据内容的问题,并以日语和英语提供详细描述。
Kakyoin03
本模型是基于Llama-3.2-11B-Vision-Instruct微调的专业汽车损伤检测模型,专门用于自动分析受损车辆图像,能够精准识别和描述车辆损伤类型、位置和严重程度。
gsarch
ViGoRL是一个基于强化学习的视觉推理模型,通过将文本推理步骤与视觉坐标明确关联,实现精确的视觉定位和区域级推理。该模型采用多轮视觉定位技术,动态缩放图像区域进行细粒度分析。
lmstudio-community
MedGemma-4B-IT是由Google开发的医疗领域专用多模态模型,支持图像文本到文本的转换任务。该模型针对医疗影像和文本分析进行了优化,在放射学、临床推理、皮肤病学等多个医疗子领域具有重要应用价值。
mlx-community
MedGemma-4B-IT-4bit 是一个专为医学领域设计的视觉语言模型,支持图像和文本处理,适用于医学图像分析等任务。
unsloth
MedGemma是基于Gemma 3的医疗专用多模态模型,擅长医学文本和图像理解,支持胸部X光、皮肤科、眼科等多种医学影像分析。
InternVL3-78B-Instruct是一个先进的多模态大语言模型,在多模态感知、推理和语言处理等方面表现出色。该模型通过原生多模态预训练方法,将视觉和语言学习整合到统一训练阶段,在工具使用、GUI代理、工业图像分析、3D视觉感知等多个领域展现出卓越能力。
ByteDance
海豚是一种创新的多模态文档图像解析模型,采用'先分析后解析'的范式处理复杂文档元素。
InternVL3-14B-Instruct 是一个先进的多模态大语言模型(MLLM),展示了卓越的多模态感知和推理能力,支持工具使用、GUI代理、工业图像分析、3D视觉感知等多种任务。
InternVL3-2B-Instruct是先进的多模态大语言模型,相比前代有更出色的多模态感知和推理能力,扩展了工具使用、GUI代理、工业图像分析、3D视觉感知等方面。采用原生多模态预训练方法,将语言和视觉学习整合到单个预训练阶段。
InternVL3-78B是一款先进的多模态大语言模型,具备卓越的多模态感知和推理能力,在工具使用、GUI代理、工业图像分析、3D视觉感知等领域表现出色,整体文本性能也十分优秀。
InternVL3-14B是一个先进的多模态大语言模型,在InternVL 2.5基础上显著提升了多模态感知和推理能力,并拓展了工具使用、GUI代理、工业图像分析、3D视觉感知等领域的应用。
InternVL3-2B是一款先进的多模态大语言模型,具备强大的多模态感知、推理及语言处理能力,广泛应用于图像分析、工具使用等多个领域。
Qwen2.5-VL是Qwen家族最新推出的视觉语言模型,具备强大的视觉理解和多模态处理能力,支持图像、视频分析和结构化输出。
AWS MCP Servers是一套基于Model Context Protocol的专用服务器,提供多种AWS相关功能,包括文档检索、知识库查询、CDK最佳实践、成本分析、图像生成等,旨在通过标准化协议增强AI应用与AWS服务的集成。
一个基于xAI Grok API的MCP服务器,提供AI图像分析功能,支持URL和本地文件的图像描述、元数据提取和OCR文字识别
OpenCV MCP Server是一个基于Python的计算机视觉服务,通过Model Context Protocol (MCP)提供OpenCV的图像和视频处理能力。它为AI助手和语言模型提供从基础图像处理到高级对象检测的全套计算机视觉工具,包括图像处理、边缘检测、人脸识别、视频分析和实时对象跟踪等功能。
MCP Vision Relay 是一个 MCP 服务器,通过封装本地安装的 Gemini 和 Qwen 命令行工具,为 Claude、Codex 等仅支持文本的 MCP 客户端提供图像分析能力,使其能够处理本地路径、URL 或 base64 编码的图片。
Vulcan File Ops是一个基于Model Context Protocol(MCP)的高性能文件操作服务器,可将桌面AI助手(如Claude Desktop、ChatGPT Desktop等)转变为强大的开发伙伴。它提供安全的文件读写、批量操作、文档处理、图像分析和Shell命令执行功能,具有企业级安全控制、动态目录注册和智能工具过滤特性,让用户完全控制本地文件系统访问。
exif-mcp是一个基于exifr库的MCP服务器,用于离线提取和分析图像元数据,支持多种图像格式和元数据段,适用于图像库分析、开发调试等场景。
Moondream MCP Server是一个基于Moondream视觉模型的图像分析服务,提供图像描述生成、物体检测和视觉问答功能,可轻松集成到Claude和Cline等AI助手中。
MCP Gemini API服务器是一个为Cursor和Claude设计的Google Gemini API代理服务,提供文本生成、图像分析、视频分析和网络搜索等功能。
Grok MCP插件是一个为Cline提供Grok AI强大功能的接口插件,支持文本生成、图像分析和函数调用。
Deep Research是一个基于代理的工具,提供网页搜索和高级研究功能,支持PDF分析、图像描述和YouTube转录提取,可作为MCP服务器运行。
一个基于GPT-4o-mini模型的图像分析MCP服务器,可处理URL或本地路径的图像内容分析
Grok MCP插件是一个为Cline提供Grok AI强大功能的接口,支持文本生成、图像分析和函数调用。
一个基于Google Gemini和Vertex AI的AI视觉分析MCP服务器,支持图像和视频的多模态分析,提供对象检测、图像比较等功能,可集成到多种MCP客户端中。
基于AI的图像解说生成服务
Oxenstierna项目旨在通过集成瑞典国家档案馆的多种API(如OAIPMH、IIIF和搜索API),提供对档案内容的搜索、获取和分析功能,包括HTR(手写文本识别)流程和图像处理。
DINO-X MCP是一个通过DINO-X和Grounding DINO 1.6 API赋能大型语言模型进行细粒度目标检测和图像理解的项目。它能够实现精确的对象定位、计数、属性分析以及场景理解,支持自然语言驱动的视觉任务和工作流集成。
一个基于OpenRouter视觉模型的MCP图像分析服务器
Rijksmuseum MCP服务器通过自然语言交互提供博物馆艺术藏品访问,支持搜索、分析和图像查看功能。
Winston AI MCP Server 是一个多功能AI检测服务器,提供文本/图像AI生成检测、抄袭检测和文本对比功能,支持多种集成方式和API访问。
Moondream MCP Server是一个强大的模型上下文协议服务器,通过Moondream视觉模型为应用程序提供高级图像分析功能,并与Claude和Cline无缝集成。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)