国内AIGC多模态创作领域迎来新进展,网易有道旗下开源AI产品LobsterAI(龙虾)升级,正式上线图片和视频生成能力。此次升级采用矩阵式整合策略,接入四大主流多模态大模型:Seedream、Seedance、HappyHorse和MiniMax-Hailuo,提升创作效率与多样性。
4月27日,阿里千问APP灰度测试视频模型HappyHorse,用户点击首页下方按钮即可体验。该模型在叙事能力、音画同步及风格多样性上表现突出,内测期间已生成大量TVB港风、央视三国风、老电影风短片。用户可通过Prompt一键制作同款,尤其擅长剧情类视频,仅需简单描述即可自动生成多镜头内容。
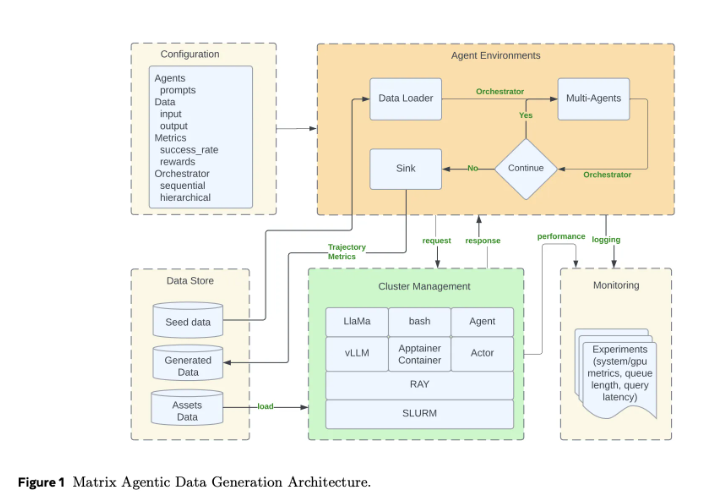
Meta AI推出Matrix框架,通过去中心化设计解决合成数据调度瓶颈。它将控制与数据流序列化为消息,分布到不同队列处理,避免中心控制器浪费GPU资源、增加协调开销的问题,提升数据新鲜度和多样性。
谷歌在诽谤诉讼中拒绝为AI“幻觉”担责。反企业多样性活动家罗比・斯塔巴克起诉称,谷歌AI错误将其与性侵指控及白人至上主义关联。此前他已对Meta提起类似诉讼,指控其AI错误指其参与国会大厦骚乱。
SliderSpace 是一种用于分解扩散模型视觉能力的技术,通过直观的滑块实现对模型的可控性和可解释性。
探索自然多样性,点击随机生成动物
基于熵的采样技术,优化模型输出的多样性和准确性
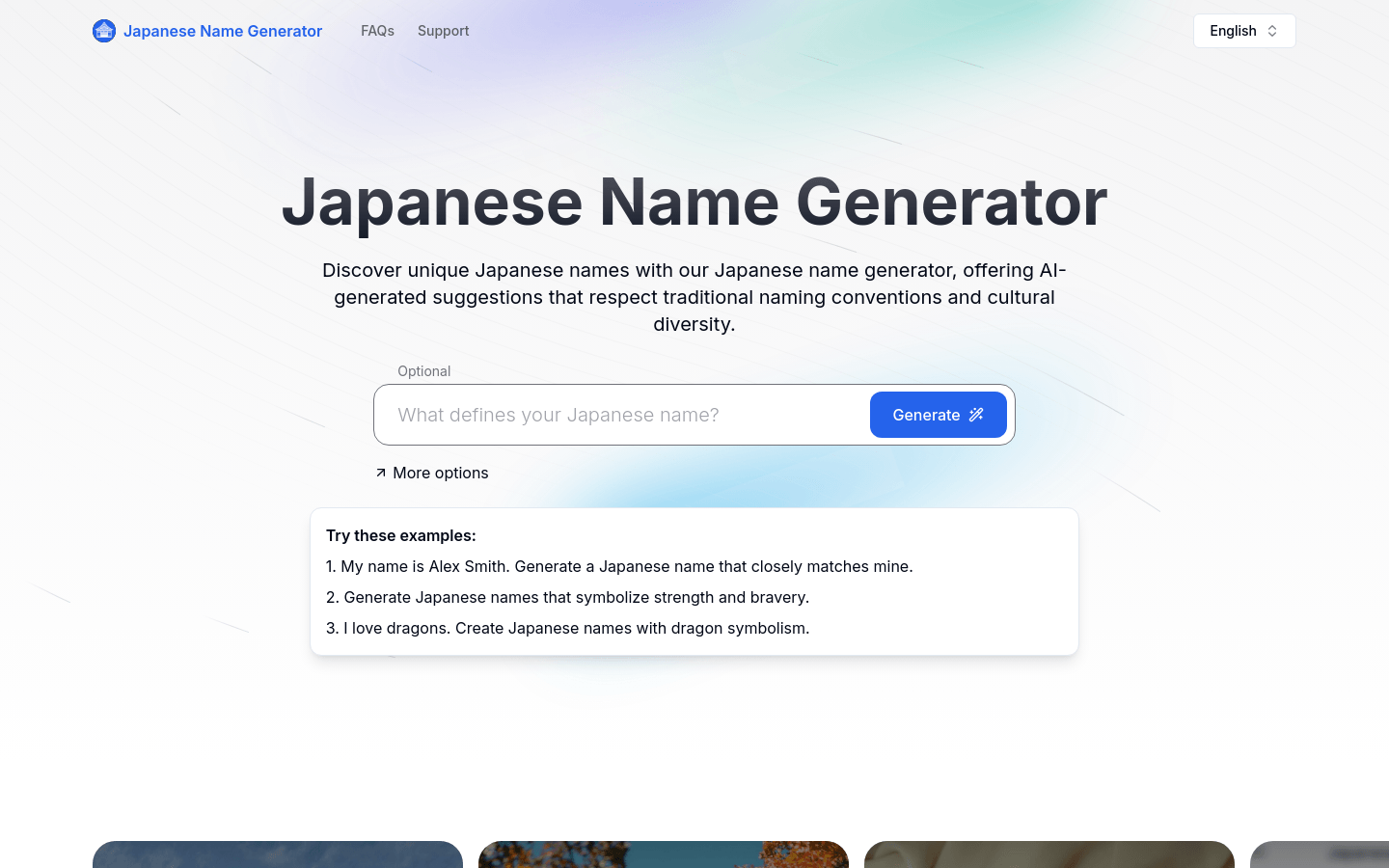
AI生成的日本名字,尊重传统和文化多样性。
Chatglm
-
Input tokens/M
Output tokens/M
Context Length
Tongyi-MAI
Z-Image是一款功能强大且高效的图像生成模型,拥有60亿参数。它能有效解决图像生成领域在效率、质量和功能多样性方面的问题,为用户提供高质量的图像生成和编辑服务。
IbrahimSalah
基于F5-TTS微调的高质量阿拉伯语语音合成模型,支持不同地区的发音和口音多样性
LingoIITGN
Ganga-2-1b是一个基于印地语数据集训练的指令微调模型,是Project Unity项目的一部分,旨在处理印度语言的多样性和丰富性。
bioscan-ml
条形码BERT是一种专门针对昆虫DNA条形码数据预训练的Transformer模型,能够对DNA序列进行特征提取和分类分析,为生物多样性研究提供技术支持。
BGLab
BioTrove-CLIP 是一套基于 CLIP 风格的生物多样性视觉语言基础模型,在包含 4000 万张图像和 3.3 万种植物和动物物种的数据集上训练。
Yntec
beLIEve 是一个融合了《我无法相信这不是摄影》v1和《真实库存照片》v3的文本生成图像模型,旨在提升细节表现和面部多样性。
nvidia
BigVGAN是基于大规模训练的通用神经声码器,能够高质量地将梅尔频谱转换为波形。v2版本通过定制CUDA内核加速推理,并扩展了训练数据多样性。
JackAILab
ConsistentID是一个多模态细粒度身份保持的肖像生成模型,能够生成具有极高身份保真度的肖像,同时不牺牲多样性和文本可控性。
IDEA-CCNL
Taiyi-Diffusion-XL是一个专注于增强中文文生图生成能力的同时保留英文理解能力的双语扩散模型。基于Stable-Diffusion-XL架构,通过高质量双语数据集训练,在图像质量、多样性和文本对齐方面表现出色,为AIGC和数字艺术创作提供新的选择。
ESGBERT
基于EnvironmentalBERT-base微调的生物多样性文本分类模型,专注于ESG/自然领域的生物多样性文本检测
LykosAI
基于GPT2的提示词扩展模型,用于增强文本生成提示的质量和多样性
sazyou-roukaku
BracingEvoMix是基于OpenBraβ和OpenBra的文本到图像生成模型系列,专注于降低高风险模型混入概率,并在亚洲人脸多样性和照片真实感方面表现优异。
InstaDeepAI
基于3,202个遗传多样性人类基因组预训练的25亿参数DNA序列基础模型,可精确预测分子表型
基于3,202个遗传多样性人类基因组预训练的5亿参数DNA序列分析模型
naclbit
基于稳定扩散 v1 的动漫/漫画风格图像生成模型,训练数据约1920万张图像,追求艺术风格多样性与解剖学质量的平衡。
NoYo25
BiodivBERT是一个基于BERT的领域特定模型,专为生物多样性文献设计。
microsoft
KRISSBERT是一个基于知识增强自监督学习的生物医学实体链接模型,通过利用无标注文本和领域知识训练上下文编码器,有效解决实体名称多样性变异和歧义性问题。
PLTM MCP服务器为Claude Desktop提供78个工具,基于物理学通用原理进行AGI实验,包括记忆操作、多样性检索、元认知和知识获取等功能,旨在通过临界性和自组织等原理推动系统向更高阶智能演进。
Model Context Protocol (MCP) 是一个开源协议,提供了一系列参考实现和社区开发的服务器,旨在为大型语言模型(LLM)提供安全、可控的工具和数据源访问。这些服务器展示了MCP的多样性和可扩展性,涵盖了从文件系统操作到数据库集成、从网络搜索到AI图像生成等多种功能。
一个基于Python的生物多样性模型协议服务器项目,支持快速部署和开发调试。
Model Context Protocol (MCP) 是一个开源协议,提供了一系列参考实现和社区开发的服务器,使大型语言模型(LLM)能够安全、可控地访问工具和数据源。该项目包含多种类型的服务器实现,涵盖文件系统、数据库、Git、Slack等多个领域,展示了MCP的多样性和可扩展性。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
'%3e%3cpath%20d='M55.2622%2038L48.2289%2022L44.1206%2031.3333H47.2539L45.7872%2034.6667H38.7622L46.0956%2018H37.6706C36.7539%2018%2036.0039%2018.75%2036.0039%2019.6667V36.3333C36.0039%2037.25%2036.7539%2038%2037.6706%2038H55.2622Z'%20fill='white'/%3e%3cpath%20d='M64.3368%2018H50.3535L59.1535%2038H64.3368C65.2535%2038%2066.0035%2037.25%2066.0035%2036.3333V19.6667C66.0035%2018.75%2065.2535%2018%2064.3368%2018ZM63.0868%2034.6667H59.7535V21.3333H63.0868V34.6667Z'%20fill='%23FFCC66'/%3e%3cpath%20d='M89.3379%2026.75V29.25H81.8379V36.75H91.8379V24.25H81.8379V26.75H89.3379ZM84.3379%2034.25V31.75H89.3379V34.25H84.3379Z'%20fill='white'/%3e%3cpath%20d='M103.504%2036.75V29.25H96.0039V26.75H103.504V24.25H93.5039V31.75H101.004V34.25H93.5039V36.75H103.504Z'%20fill='white'/%3e%3cpath%20d='M115.17%2026.75V24.25H105.17V36.75H115.17V34.25H107.67V31.75H115.17V29.25H107.67V26.75H115.17Z'%20fill='white'/%3e%3cpath%20d='M80.1712%2029.25V29.175L78.9962%2028L80.1712%2026.825V20.425L78.9962%2019.25H69.3379V36.75H78.9962L80.1712%2035.575V29.25ZM77.6712%2034.25H71.8379V29.25H77.6712V34.25ZM77.6712%2026.75H71.8379V21.75H77.6712V26.75Z'%20fill='white'/%3e%3c/g%3e%3cg%20clip-path='url(%23clip1_644_3948)'%3e%3cpath%20d='M169.59%2022.9827L169.59%2023.6491H177.409L168.175%2032.8822L169.118%2033.8248L178.351%2024.5917L178.352%2032.4106H179.685V22.3164L179.018%2022.3157H169.59V22.9827Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_644_3948'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(36%2018)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_644_3948'%3e%3crect%20width='20'%20height='20'%20fill='white'%20transform='translate(164%2018)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)