大模型竞赛进入“落地攻坚”阶段,火山引擎提出AI演进新范式:智能Agent成为AI落地核心载体,多模态能力与高效开发体系是关键。大模型正从问答交互转向深入汽车、制造等复杂场景,实现从“聊天”到“干活”的跨越。
Meta发布SAM Audio,全球首个统一多模态音频分离模型。用户可通过点击视频中物体、输入关键词或圈定时间片段,一键提取目标声音或过滤噪音,实现“用眼睛听声音”。该技术首次模拟人类自然感知声音的方式,支持看、说等多种交互。
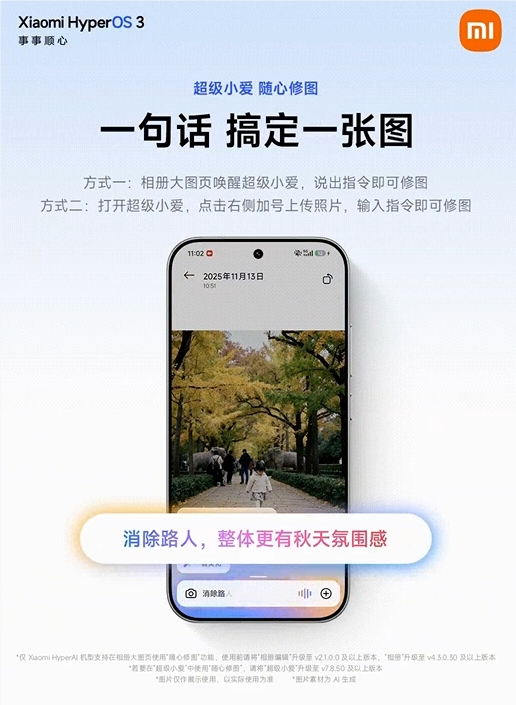
小米更新超级小爱至v7.8.50版,新增“随心修图”功能。用户可通过自然语言指令,利用AI模型自动修图,支持多模态交互识别屏幕和摄像头画面。操作方式包括在相册唤醒小爱或通过App上传照片并输入文字,系统自动完成色彩增强、背景虚化等处理。
李飞飞World Labs推出Marble 3D世界模型公测版,支持文本、图像、视频等多模态输入,快速生成可交互虚拟宇宙,助力开发者探索AI技术应用。
一款支持多种语言模型的高性能AI聊天工具,提供本地隐私保护和多模态交互功能。
MinMo是一款多模态大型语言模型,用于无缝语音交互。
VITA-1.5: 实时视觉和语音交互的GPT-4o级多模态大语言模型
多模态大型语言模型,提升视觉与语言的交互能力。
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$4
$16
$1
$10
256
Baidu
128
$2
$20
$6
$24
John1604
Qwen3 VL 4B Thinking 是一个支持图像到文本以及文本到文本转换的多模态模型,具有4B参数规模,能够满足多种图文交互需求。
pramjana
Qwen3-VL-4B-Instruct是阿里巴巴推出的40亿参数视觉语言模型,基于Qwen3架构开发,支持多模态理解和对话任务。该模型具备强大的图像理解和文本生成能力,能够处理复杂的视觉语言交互场景。
unsloth
JanusCoder-8B是基于Qwen3-8B构建的开源代码智能基础模型,旨在建立统一的视觉编程接口。该模型在JANUSCODE-800K(迄今为止最大的多模态代码语料库)上训练,能够处理各种视觉编程任务,包括数据可视化、交互式Web UI和代码驱动动画等。
Qwen
Qwen3-VL-2B-Thinking是Qwen系列中最强大的视觉语言模型之一,采用GGUF格式权重,支持在CPU、NVIDIA GPU、Apple Silicon等设备上进行高效推理。该模型具备出色的多模态理解和推理能力,特别增强了视觉感知、空间理解和智能体交互功能。
Qwen3-VL-8B-Thinking是通义千问系列中最强大的视觉语言模型,具备增强推理能力的8B参数版本。该模型在文本理解、视觉感知、空间理解、长上下文处理等方面全面升级,支持多模态推理和智能体交互。
Qwen3-VL是迄今为止Qwen系列中最强大的视觉语言模型,在文本理解与生成、视觉感知与推理、上下文长度、空间和视频动态理解以及智能体交互能力等方面都进行了全面升级。该模型采用混合专家(MoE)架构,提供卓越的多模态处理能力。
Qwen3-VL是阿里巴巴推出的最新一代视觉语言模型,在文本理解、视觉感知、空间理解、视频分析和智能体交互等方面均有显著提升。该模型支持多模态输入,具备强大的推理能力和长上下文处理能力。
microsoft
Fara-7B是微软研究院开发的专为计算机使用场景设计的小型语言模型,仅有70亿参数,在同规模模型中实现卓越性能,能够执行网页自动化、多模态理解等计算机交互任务。
bartowski
这是Qwen3-VL-2B-Instruct模型的量化版本,使用llama.cpp工具和imatrix方法生成了多种量化级别的模型文件,便于在不同硬件环境下高效运行。该模型是一个2B参数的多模态视觉语言模型,支持图像和文本的交互。
Qwen3-VL-2B-Instruct是Qwen系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持以及强大的空间和视频动态理解能力。该模型采用2B参数规模,支持指令交互,适用于多模态AI应用。
noctrex
本项目提供了慧慧Qwen3-VL-30B-A3B-Instruct模型的量化版本,旨在提升模型在特定场景下的性能与效率。这是一个基于Qwen3-VL架构的视觉语言模型,支持图像和文本的多模态交互。
Qwen3-VL是通义系列最强大的视觉语言模型,在文本理解与生成、视觉感知与推理、上下文长度、空间和视频理解能力等方面全面升级,具备卓越的多模态交互能力。
OpenGVLab
VideoChat-R1_5-7B是基于Qwen2.5-VL-7B-Instruct构建的视频文本交互模型,支持多模态任务,特别擅长视频问答功能。该模型通过强化微调增强时空感知能力,并采用迭代感知机制来强化多模态推理。
TIGER-Lab
本项目基于Qwen2.5-VL-7B-Instruct模型,专注于视觉问答任务,能够精准回答图像相关问题,具备较高的准确性和相关性。这是一个多模态视觉语言模型,支持图像理解和基于图像的问答交互。
InternVL3.5是开源多模态模型家族的新成员,显著提升了InternVL系列的通用性、推理能力和推理效率,支持GUI交互等新功能,达到开源多模态大语言模型的先进水平。
InternVL3.5-14B是InternVL系列的开源多模态模型,显著提升了通用性、推理能力和推理效率,支持GUI交互等新功能,缩小了与商业模型的性能差距。
InternVL3.5-4B是开源多模态模型系列中的中等规模版本,在通用性、推理能力和推理效率上取得显著进展,支持GUI交互等新能力。该模型采用级联强化学习框架和视觉分辨率路由器技术,实现了高效的多模态理解与推理。
InternVL3.5-1B是InternVL系列的开源多模态模型,参数量为1.1B,包含0.3B视觉参数和0.8B语言参数。该模型显著提升了通用性、推理能力和推理效率,支持GUI交互等新功能。
nvidia
OmniVinci是NVIDIA开发的全模态理解大语言模型,具备视觉、文本、音频处理和语音交互能力,支持多模态推理和理解。
fixie-ai
Ultravox是一个多模态语音大语言模型,能够同时处理语音和文本输入,为语音交互场景提供强大支持。
ToolChat是一个通过MCP服务器与大型语言模型(LLM)交互的工具,支持配置多工具服务器并调用特定功能,还能处理多模态输入如图片和文档。
 Transformers
Transformers%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)