Mistral AI推出Voxtral系列模型,整合文本与音频处理能力。该系列包括Voxtral-Mini-3B-2507和Voxtral-Small-24B-2507两款。前者为3亿参数模型,适合快速音频转录和基础多模态理解;后者拥有240亿参数,支持复杂音频文本智能和多语言处理,适用于企业级应用。两款模型均支持30至40分钟音频上下文处理。
英伟达与Mistral AI合作,加速开发开放源模型Mistral 3系列。该系列为多语言、多模态模型,采用混合专家架构,针对英伟达平台优化,旨在提升任务处理效率。
汇丰银行与AI公司Mistral合作,引入先进AI工具提升业务效率,重点优化多语言文档处理、翻译及文件分析等内部流程,以技术创新推动运营升级。
Reverie公司发布新款语音转文本模型,支持印地语、英语及Hinglish混合语言,适应印度多语言环境。该模型已处理300万次API调用,在银行和呼叫中心等行业应用中展现出高精确度和快速响应能力。
aOCR:AI文档解析与数据提取软件,99.2%准确率,实时处理,多语言支持
一键用AI优化文本,修正错误、调整风格、多语言处理等
专业wan 2.5 AI视频生成器,音频同步,可打造惊艳视频
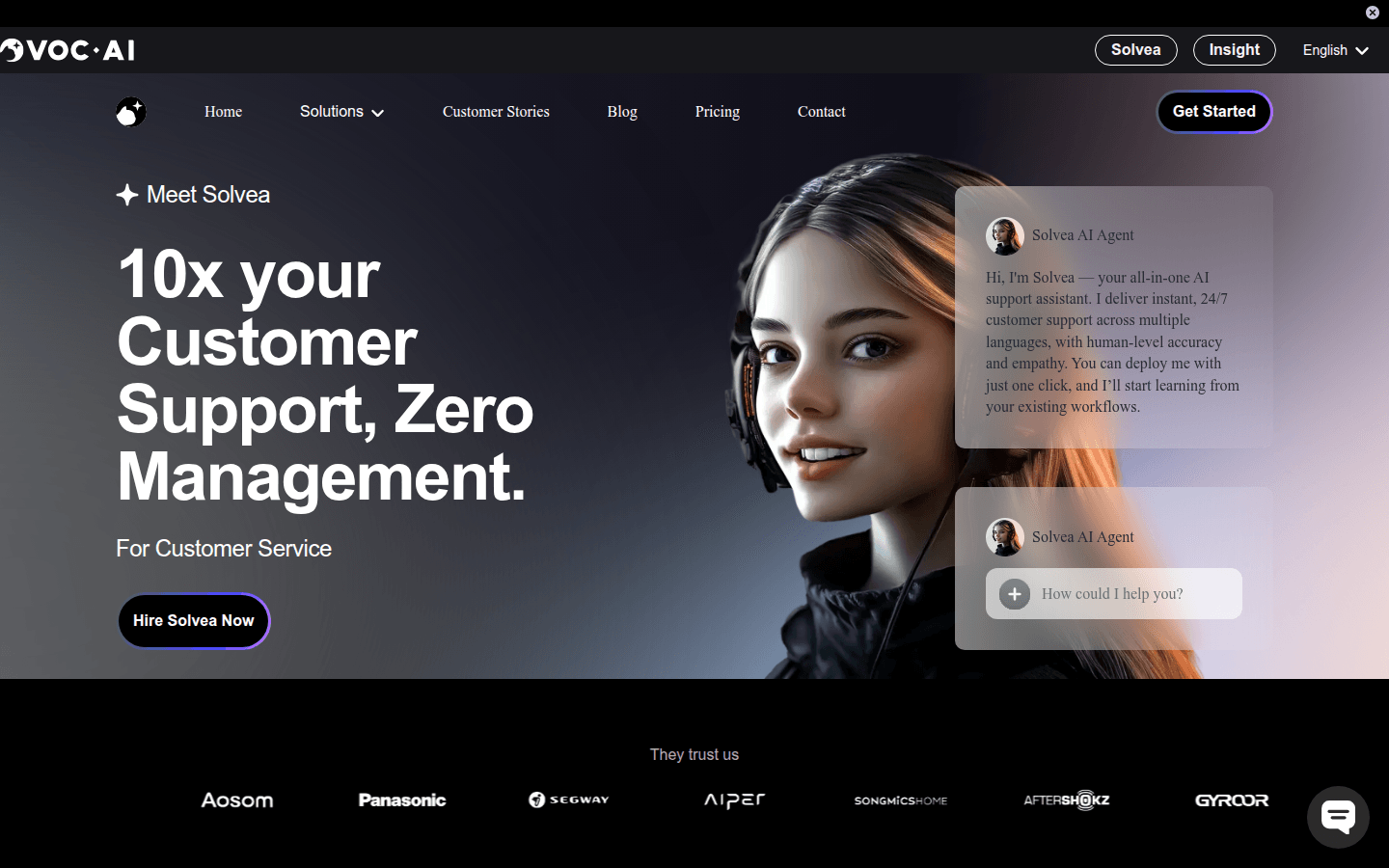
提供全天候的AI支持助手,可以处理多语言客户支持,准确度和同理心达到人类水平。
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
-
Anthropic
$105
$525
200
$0.7
$7
$35
$17.5
$21
Alibaba
$4
$16
$1
$10
256
$6
$24
$2
$20
Baidu
128
$8
$240
52
Bytedance
$1.2
$3.6
4
RinggAI
这是一个专为通话记录分析打造的混合语言AI模型,能够处理印地语、英语和混合印地英语的通话转录内容。模型基于Qwen2.5-1.5B-Instruct进行微调,具备强大的多语言理解和信息提取能力。
tencent
混元OCR是由混元原生多模态架构驱动的端到端OCR专家VLM模型,仅用10亿参数的轻量级设计,在多个行业基准测试中取得最先进成绩。该模型擅长处理复杂的多语言文档解析,在文本定位、开放域信息提取、视频字幕提取和图片翻译等实际应用场景中表现出色。
Guilherme34
Qwen3-32B是Qwen系列最新一代的大语言模型,具备强大的推理、指令遵循、智能体交互和多语言处理能力。它支持100多种语言和方言,能在思维模式和非思维模式间无缝切换,为用户提供自然流畅的对话体验。
redponike
Qwen3-VL-4B-Instruct 是通义千问系列最新的视觉语言模型,在4B参数规模下实现了卓越的视觉感知、文本理解与生成、空间推理和智能体交互能力。它支持长上下文和视频理解,具备强大的OCR和多语言处理能力。
mradermacher
Lamapi/next-12b 是一个基于12B参数的大语言模型,通过多语言数据集进行微调,支持50多种语言,具备高效文本生成能力,适用于化学、代码、生物、金融、法律等多个领域的自然语言处理任务。
Lamapi/next-12b 是一个120亿参数的多语言大语言模型,提供了多种量化版本,支持文本生成、问答、聊天等多种自然语言处理任务。该模型在多个领域数据集上训练,具有高效、轻量级的特点。
unsloth
Granite-4.0-H-350M是IBM开发的轻量级指令模型,具有350M参数,在多语言处理和指令遵循方面表现出色,专为设备端部署和研究场景设计。
RedHatAI
Llama-4-Maverick-17B-128E-Instruct-NVFP4是一个经过FP4量化处理的多语言大语言模型,基于Meta-Llama-3.1架构,专为商业和研究用途设计。该模型通过将权重和激活量化为FP4数据类型,显著减少了磁盘空间和GPU内存需求,同时保持较好的性能表现。
thenexthub
这是一个支持多语言处理的多模态模型,涵盖自然语言处理、代码处理、音频处理等多个领域,能够实现自动语音识别、语音摘要、语音翻译、视觉问答等多种任务。
Mungert
Nanonets-OCR2-1.5B-exp GGUF 是一款强大的图像到markdown的OCR模型,能够将文档转换为结构化的markdown格式,并进行智能内容识别和语义标记,支持多语言文档处理。
这是PRIME-RL/P1-30B-A3B模型的静态量化版本,是一个300亿参数的大语言模型,专门针对物理、强化学习、竞赛推理等领域优化,支持英语和多语言处理。
impresso-project
Impresso NER模型是一个专门用于历史文档处理的多语言命名实体识别模型。基于堆叠式Transformer架构,能够识别数字化历史文本中的细粒度和粗粒度实体类型,包括人名、头衔、地点等。该模型针对历史文档中的OCR噪声、拼写变化和非标准语言用法进行了优化。
cpatonn
Granite-4.0-H-Tiny AWQ - INT4是基于Granite-4.0-H-Tiny基础模型经过AWQ量化处理的4比特版本,在保持性能的同时显著减少资源消耗。该模型具有70亿参数,支持多语言处理,具备丰富的功能包括文本生成、代码补全、工具调用等。
nightmedia
LFM2-8B-A1B-qx86-hi-mlx是基于MLX格式的高效推理模型,从LiquidAI/LFM2-8B-A1B转换而来。该模型采用混合专家架构,在推理任务中表现出卓越的效率,特别擅长复杂逻辑推理任务,同时支持多语言处理。
jinaai
这是jina-reranker-v3模型的GGUF量化版本,是一个具有0.6B参数的多语言列表式重排器,专门用于文档重排任务,经过量化处理以实现高效推理。
intexcp
ru-en-RoSBERTa是一个在多语言任务中表现出色的模型,基于RoBERTa架构,专门针对俄语和英语任务进行优化。该模型在多种自然语言处理任务上进行了全面测试,包括分类、聚类、重排序和检索等,展现了强大的跨语言理解能力。
Apertus是一款参数规模达70B和8B的全开放多语言语言模型,支持超1000种语言和长上下文处理,仅使用完全合规且开放的训练数据,性能可与闭源模型相媲美。
Apertus是一款由瑞士AI开发的全开放多语言大语言模型,参数规模达80亿和700亿,支持超过1000种语言和长上下文处理,仅使用完全合规的开放训练数据,性能可与闭源模型相媲美。
lmstudio-community
KAT-Dev是由Kwaipilot开发的多语言自然语言处理模型,支持多种语言交互任务,提供高效准确的语言处理能力。该版本经过MLX团队8位量化优化,专门针对苹果硅芯片进行了性能优化。
amd
本模型是Meta发布的Llama 3.1系列中的80亿参数版本,经过AMD Quark量化工具处理和后处理,优化了在特定硬件上的部署与推理效率。它是一款多语言文本生成模型,支持多种语言,并在MMLU等基准测试中表现出色。
FastApply MCP Server是一个企业级代码智能平台,通过本地AI模型、AST语义搜索、安全扫描和智能模式识别,提供全面的代码分析、搜索和重构能力,支持多语言开发和大规模代码库处理。
Lara Translate MCP Server是一个基于模型上下文协议(MCP)的翻译服务中间件,为AI应用提供与Lara Translate API的桥梁连接。
Votars MCP是一个支持多语言实现的工具,用于与Votars AI平台集成,处理语音转录和AI任务。
Markdownify MCP UTF-8增强版是一个支持多语言内容转换的Markdown处理服务,优化了UTF-8编码支持,提供PDF/图片/音视频/Office文档等多种格式的Markdown转换能力,并针对Windows系统进行了特别优化。
一个基于MCP协议的Google新闻搜索服务器,通过SerpAPI提供多语言、多地区的新闻搜索服务,支持智能分类和多种新闻类型处理。
一个用于获取、跟踪和处理Bybit平台公告的MCP服务器,支持多语言筛选、类型过滤和分页查询,并以清晰的Markdown格式返回结果。
一个基于MCP协议的多语言代码注释清除服务,支持批量处理多种编程语言文件,采用TDD开发确保质量。
基于大语言模型的多语言本地化翻译工具,支持多种文件格式的智能处理和批量翻译
一个实现MCP协议的服务器,通过OpenRouter API连接Cursor,提供代码审查和AI聊天功能,支持多语言项目分析和上下文处理。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)