宇树科技获授权新专利,通过扩散策略提升机器人决策能力,解决动作理解偏差问题。技术核心包括场景理解、交互预测与扩散决策,旨在增强机器人对未来状态的准确认知。
扩散大语言模型(dLLM)正引领AI思维模式变革。它采用迭代去噪策略,像反复思考的智者,在多个时间维度中推敲,最终输出更精准结果,颠覆了传统逐字生成模式。
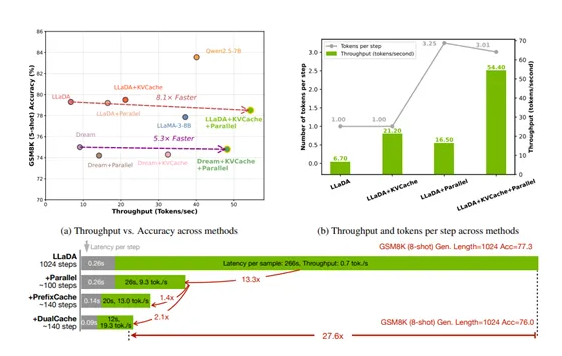
英伟达联合港大、MIT推出Fast-dLLM技术,显著提升扩散语言模型推理效率。该技术通过创新的块状KV缓存机制,将LLaDA模型推理速度提升27.6倍,同时采用置信度解码策略保证生成质量。测试显示,在数学推理等任务中,模型吞吐量达54.4tokens/s,准确率保持78.5%,实现速度与质量的双重突破。
香港理工大学与OPPO研究院联合推出开源视频超分辨率框架DLoRAL,基于扩散模型实现一步生成高清视频。该框架采用双LoRA架构:C-LoRA保持帧间一致性,D-LoRA增强空间细节;通过双阶段训练策略优化时间连贯性和高频信息。相比传统方法,DLoRAL在保持流畅性的同时提升10倍推理速度,显著改善画质细节,为视频高清化提供高效开源解决方案。
一种基于视频扩散模型的多任务灵巧手操控通用机器人策略
Alibaba
-
Input tokens/M
Output tokens/M
Context Length
Baidu
32
Google
Tencent
$0.8
$2
30
Chatglm
Gjm1234
Wan2.2是基础视频模型的重大升级版本,专注于将有效MoE架构、高效训练策略和多模态融合等创新技术融入视频扩散模型,为视频生成领域带来更强大、更高效的解决方案。
JetLM
SDAR是一种新型大语言模型,集成了自回归和离散扩散建模策略,结合了AR模型高效训练和扩散模型并行推理的优势。在通用任务上与SOTA开源AR模型相当,在科学推理任务上表现出色,成为最强大的扩散语言模型。
nbirukov
基于扩散策略的视觉运动控制模型,将机器人控制视为生成扩散过程,能够生成平滑的多步动作轨迹,在富接触操作任务中表现出色。
jclinton1
Diffusion Policy 是一个基于扩散策略的机器人控制模型,通过 PyTorch 实现并集成到 Hugging Face 的模型中心。
Diffusion Policy 是一个基于扩散模型的策略学习框架,适用于机器人控制任务。
一个基于扩散策略的机器人控制模型,通过PyTorchModelHubMixin集成发布
rail-berkeley
Octo小型版是一个用于机器人控制的扩散策略模型,采用Transformer架构,能够根据视觉输入和语言指令预测机器人动作。
lerobot
Diffusion Policy 是一种基于动作扩散的视觉运动策略学习模型,专为 PushT 环境设计。
Octo小型版是一个基于扩散策略训练的机器人控制模型,能够预测未来4步的7维动作,适用于多源机器人数据集。
Octo是一个基于扩散策略训练的机器人控制基础模型,能够预测未来动作并处理多模态输入。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)