近日,AIbase从社交媒体平台获取最新信息,了解到一家专注于日语微调的HuggingFace模型提供者——Shisa.AI,其最新发布的日英双语模型引发业界广泛关注。本文将为您详细解读Shisa.AI的最新成果及其在日语AI领域的突破性进展。Shisa V2405B:日本最强开源模型诞生据AIbase了解,Shisa.AI最新发布了基于Llama3.1的Shisa V2405B模型,这一开源模型被誉为“日本有史以来训练的最强大型语言模型”。该模型不仅在日语任务上表现出色,还保留了强大的英语处理能力,展现了日英双语模型的卓越性能。测试数据
最近在东京举办的 Gemma 开发者日上,谷歌正式推出了新的日语版本 Gemma AI 模型。这款模型的表现可以与 GPT-3.5媲美,但它的参数量只有仅仅20亿,非常小巧,适合在移动设备上运行。这次发布的 Gemma 模型,在日语处理上表现出色,同时也保持了其在英语上的能力。对于小型模型来说,这一点特别重要,因为在进行新语言的微调时,它们可能会面临 “灾难性遗忘” 的问题,即新学到的知识会覆盖之前学到的信息。但是 Gemma 成功克服了这个难题,展现了强大的语言处理能力。更值得一提的是
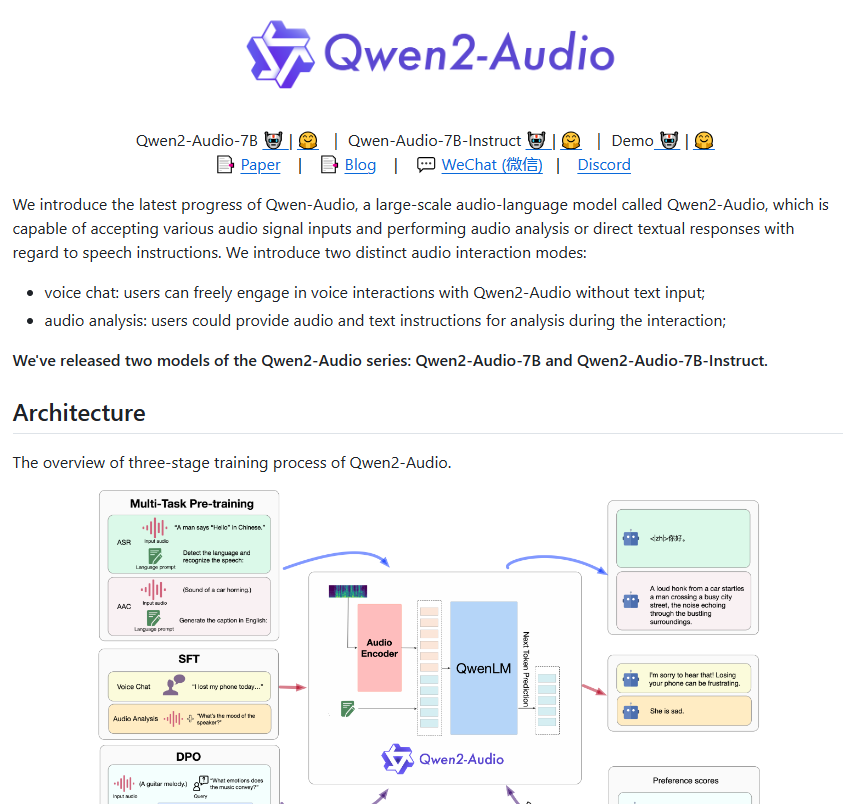
阿里巴巴近期发布了全新开源语音模型Qwen2-Audio,这款模型在语音识别、翻译和音频分析方面表现出色,实现了显著性能提升。Qwen2-Audio提供基础版和指令微调版,支持多种语言,如中文、粤语、法语、英语和日语,为情感分析和翻译应用提供了便利。相较于Qwen-Audio,Qwen2-Audio在架构和性能上进行了全面优化,预训练阶段采用更自然的语言提示,提升理解和泛化能力。指令跟随能力增强,能更准确理解用户指令。模型引入语音聊天和音频分析模式,输出符合人类期望。在性能测试中,Qwen2-Audio超越OpenAI的Whisper-large-v3,在语音识别和翻译准确性上表现出强劲竞争力。
["猎户星空发布猎户星空大模型(Orion-14B)","模型拥有 140 亿参数规模,覆盖了常见语言和专业术语","支持超长文本,推理速度达到 31token/s","优秀的多语言能力,特别在日语和韩语方面表现出色","提供了微调模型和多款应用,助力企业提升效率和决策能力"]
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$4
$16
$1
$10
256
$2
$20
Baidu
128
$6
$24
Bytedance
$1.2
$3.6
4
$3.9
$15.2
64
prj-beatrice
本模型是基于rinna/japanese-hubert-base通过CTC进行日语音素识别的微调模型,可有效提升日语语音识别的准确性。
Aratako
基于Qwen3-30B-A3B-NSFW-JP微调的角色扮演专用大语言模型,支持日语长文本生成
kawaimasa
专为日语小说创作支持而微调的大规模语言模型
基于Qwen3-8B进行角色扮演场景微调的模型,适用于日语角色扮演对话生成。
专为日语小说创作辅助而微调的大规模语言模型预览版本
EQUES
OpenRS3-GRPO-ja是基于SakanaAI/TinySwallow-1.5B-Instruct模型在日语数学指令数据集上微调的版本,采用GRPO方法训练,专注于数学推理任务。
基于sbintuitions/sarashina2.2-3b-instruct-v0.1微调的专用于角色扮演的日语大语言模型
hhim8826
基于OpenAI Whisper Large V3 Turbo微调的日语动漫语音识别模型,优化了动漫对话和表达方式的识别能力。
llm-jp
由日本国立信息学研究所开发的大规模日语-英语混合MoE语言模型,支持8x13B参数规模,经过指令微调优化
基于modernbert-ja-310m微调的日语小说质量评估奖励模型,用于预测用户对小说文本的评价。
基于modernbert-ja-130m微调的日语小说质量评估奖励模型,用于预测用户对小说文本的评价分数。
基于sbintuitions/sarashina2.1-1b微调的日语小说质量评估模型,用于预测用户对小说文本的评价。
YoichiTakenaka
基于微调后的 DeBERTa 模型,用于进行日语文本情感预测的 Python 包。
rinna
这是基于rinna/qwen2.5-bakeneko-32b-instruct模型的量化版本,使用llama.cpp进行量化处理,专门针对日语优化的32B参数大语言模型。模型经过持续预训练和指令微调,可兼容众多基于llama.cpp的应用程序。
由日本国立情报学研究所大语言模型研发中心开发的72亿参数指令微调大语言模型,专门针对日语和英语优化,支持多语言文本生成和代码理解任务。
lightblue
这是DeepSeek R1模型的日语版本,专门针对日语推理任务进行微调,能够可靠且准确地以日语响应提示。
vlzcrz
基于openai/whisper-small在Common Voice 17.0数据集上微调的日语语音识别模型
reazon-research
基于wav2vec 2.0 Large架构,在大型日语ASR语料库ReazonSpeech v2.0上微调而成的日语自动语音识别模型
AXCXEPT
基于Meta AI的Llama 3.2微调的日语优化模型,支持多语言文本生成
google
Gemma 2 JPN是基于日语文本微调的Gemma 2 2B模型,具有出色的日语处理能力,适用于多种文本生成任务。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)