英伟达发布大模型微调指南,降低技术门槛,让普通开发者也能在消费级设备上高效完成模型定制。该指南详解如何在NVIDIA全系硬件上利用开源框架Unsloth实现专业级微调。Unsloth专为NVIDIA GPU打造,优化训练全流程,提升性能。
阿里通义实验室推出开源工具Qwen-Image-i2L,可将单张图片快速转化为可微调的LoRA模型,大幅降低个性化风格迁移门槛。用户只需上传一张图片,无需大量数据或昂贵算力,即可生成轻量级LoRA模块,并集成到其他生成模型中,实现高效“单图风格迁移”。该技术已在AI社区引发广泛关注。
亚马逊云科技在re:Invent2025大会上推出Nova Forge和Nova Act两项生成式AI服务。Nova Forge旨在解决企业将专有知识融入AI模型的难题,避免传统方法如微调闭源模型、持续训练导致能力退化或从零训练的高成本问题。
北京零一万物与恺英网络旗下杭州极逸人工智能达成深度合作,将联合研发面向游戏行业的产业大模型,并在极逸自研AIGC引擎“SOON”中落地,实现全流程一键游戏生成。零一万物提供Yi系列基座大模型与AI Infra经验,负责通用能力调优;极逸AI开放游戏数据与SOON引擎接口,主导场景化微调。
Radal是一个无代码平台,可使用您自己的数据微调小型语言模型。连接数据集,通过可视化配置训练,并在几分钟内部署模型。
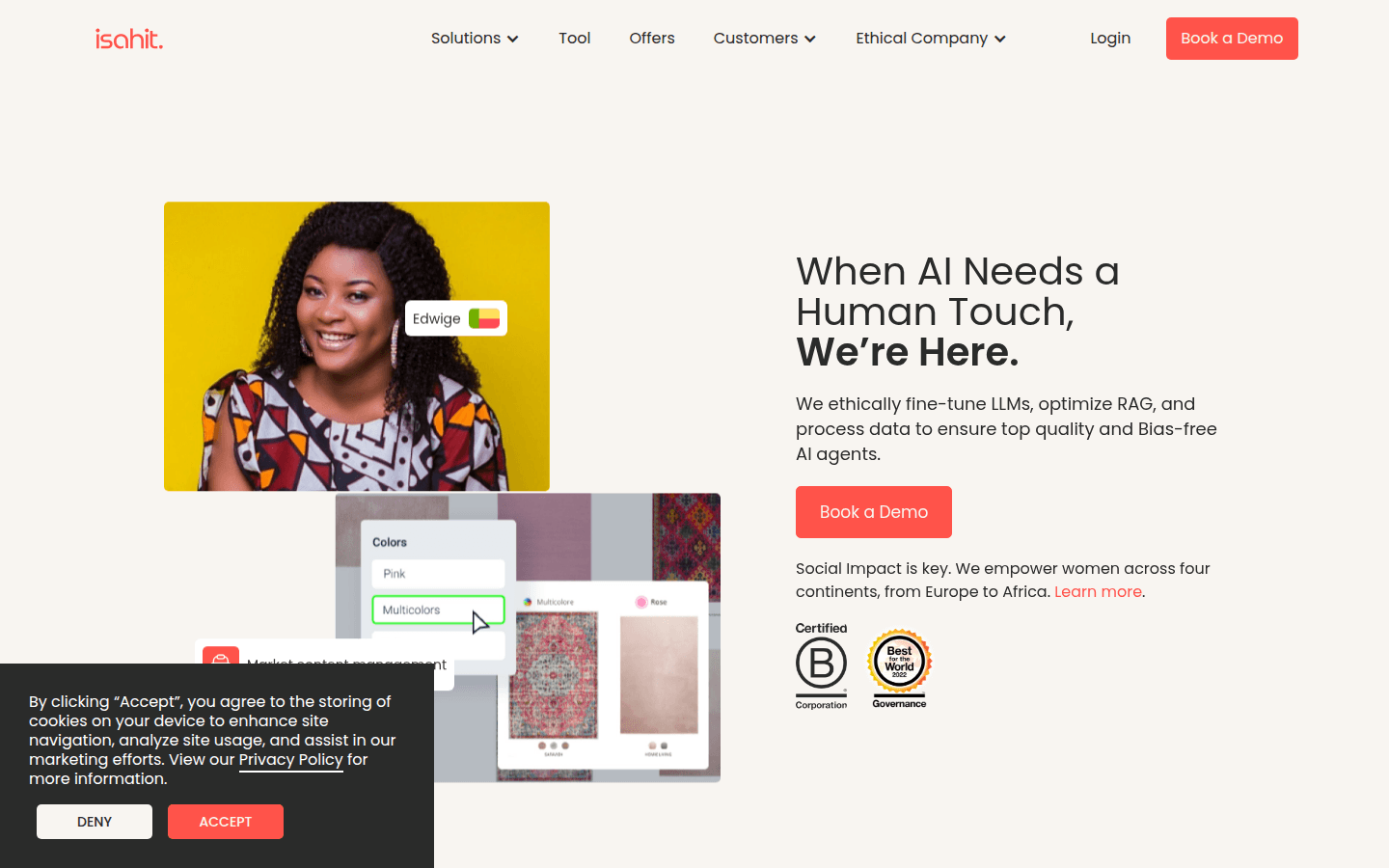
Isahit是一个管理工作人员的平台,专注于LLM微调和数据处理,确保AI代理的高质量和无偏见。
BAGEL是一款开源的统一多模态模型,您可以在任何地方进行微调、精简和部署。
使用微信聊天记录微调大语言模型,实现高质量声音克隆。
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$4
$16
$1
$10
256
$6
$24
Baidu
128
$2
$20
uaritm
Gemma-UA-Cardio 是两款专为乌克兰语心脏病学领域设计的专业大语言模型。它们基于 Google 的 Gemma 和 MedGemma 模型,经过两阶段微调(语言适配与领域专业化),能够以乌克兰语精准提供心血管医学信息、解答临床问题,是面向医疗专业人士的辅助工具。
dx8152
这是一个基于Qwen-Image-Edit-2509的LoRA微调模型,专门用于解决图像二次光照处理问题。它能够移除原始图像的光照效果,并根据参考图像的光照和色调,为目标图像重新生成逼真的照明和阴影,实现图像风格的迁移与融合。
prithivMLmods
CodeV是基于Qwen2.5-VL-7B-Instruct微调得到的70亿参数视觉语言模型,通过监督微调(SFT)和基于工具感知策略优化(TAPO)的强化学习(RL)两阶段训练,旨在实现可靠、可解释的视觉推理。它将视觉工具表示为可执行的Python代码,并通过奖励机制确保工具使用与问题证据一致,解决了高准确率下工具调用不相关的问题。
mradermacher
这是一个专注于网络安全领域的20B参数开源大语言模型,基于GPT-OSS架构,并融合了多个网络安全指令数据集进行微调。模型提供了多种量化版本,便于在资源受限的环境中部署,可用于生成网络安全相关的文本、代码和分析报告。
redis
这是一个基于Alibaba-NLP/gte-reranker-modernbert-base模型,在LangCache句子对数据集上使用sentence-transformers库微调的跨编码器模型。它专门用于计算文本对之间的语义相似度得分,旨在为LangCache语义缓存系统提供高效的文本匹配和重排序能力。
这是一个由Redis微调的交叉编码器模型,专门用于语义缓存场景下的句子对重排序。它基于Alibaba-NLP的gte-reranker-modernbert-base模型,在LangCache句子对数据集上进行训练,能够高效计算两个文本之间的语义相似度得分,用于判断它们是否表达相同或相似的含义。
open-thoughts
OpenThinker-Agent-v1-SFT 是基于 Qwen/Qwen3-8B 进行有监督微调(SFT)得到的智能体模型。它是 OpenThinker-Agent-v1 完整训练流程(SFT + RL)的第一阶段模型,专门针对智能体任务(如终端操作和代码修复)进行优化。
OpenThinker-Agent-v1 是一个基于 Qwen3-8B 进行后续训练的开源智能体模型,专为终端操作和软件工程任务而设计。它首先在高质量监督微调数据集上进行训练,然后通过强化学习进一步优化,在 Terminal-Bench 2.0 和 SWE-Bench 等智能体基准测试中表现出色。
这是一个由Redis开发的、针对LangCache语义缓存任务进行微调的CrossEncoder模型。它基于成熟的`cross-encoder/ms-marco-MiniLM-L6-v2`模型,在超过100万对LangCache句子对数据集上训练,专门用于计算两个文本之间的语义相关性得分,以优化缓存命中率。
DavidAU
Qwen3-4B-Hivemind-Instruct-NEO-MAX-Imatrix-GGUF 是一款基于 Qwen3 架构的 4B 参数指令微调大语言模型,采用 NEO Imatrix 与 MAX 量化技术,具备 256k 的超长上下文处理能力。该模型在多个基准测试中表现出色,是一款性能强劲的通用型模型。
rujutashashikanjoshi
这是一个基于YOLOv12 Medium架构,在自定义数据集上微调的目标检测模型。该模型专门用于高效、准确地检测图像或视频中的无人机目标,为计算机视觉应用提供支持。
mlx-community
本模型是 Mistral AI 发布的 Ministral-3-3B-Instruct-2512 指令微调模型的 MLX 格式转换版本。它是一个参数规模为 3B 的大型语言模型,专门针对遵循指令和对话任务进行了优化,并支持多种语言。MLX 格式使其能够在 Apple Silicon 设备上高效运行。
ss-lab
这是一个基于Meta LLaMA 3 8B模型,使用Unsloth框架进行高效微调,并转换为GGUF格式的轻量级文本生成模型。模型针对Alpaca数据集进行了优化,适用于本地部署和推理,特别适合在资源受限的环境中使用。
本项目提供了一个基于微软Phi-3.5-mini-instruct模型进行微调的文本生成模型,已转换为GGUF格式,适用于llama.cpp推理框架。模型在philschmid/guanaco-sharegpt-style数据集上进行了微调,优化了指令遵循和对话能力,适用于资源受限环境下的高效文本生成任务。
Shawon16
这是一个基于VideoMAE架构的视频理解模型,在Kinetics数据集上预训练,并在一个未知的、可能与手语识别相关的数据集上进行了微调。模型在评估集上取得了78.11%的准确率,适用于视频分类任务。
这是一个基于VideoMAE-base架构微调的视频理解模型,专门针对手语识别任务进行优化。模型在WLASL数据集上训练了200个epoch,采用TimeSformer架构处理视频序列。
这是一个基于VideoMAE-base架构微调的视频理解模型,专门针对手语识别任务进行优化。模型在WLASL100数据集上训练了200个epoch,具备视频动作识别能力。
RinggAI
这是一个专为通话记录分析打造的混合语言AI模型,能够处理印地语、英语和混合印地英语的通话转录内容。模型基于Qwen2.5-1.5B-Instruct进行微调,具备强大的多语言理解和信息提取能力。
这是一个基于VideoMAE-base架构在未知数据集上微调的视频理解模型,专门用于手语识别任务。模型在20个训练周期后达到了18.64%的准确率。
这是一个基于VideoMAE架构的视频理解模型,在Kinetics数据集预训练的基础上进行了微调,专门用于手语识别任务。模型在评估集上表现有待提升,准确率为0.0010。
OpenManus是一个无需邀请码即可实现各种想法的开源项目,由MetaGPT团队成员在3小时内构建完成。它提供了一个简单的实现,允许用户创建自己的智能代理,并支持多种语言和配置。项目欢迎建议、贡献和反馈,未来计划包括更好的规划、实时演示、回放功能、RL微调模型和全面的基准测试。
Unsloth MCP Server是一个用于高效微调大语言模型的服务器,通过优化算法和4位量化技术,实现2倍训练速度提升和80%显存节省,支持多种主流模型。
Unsloth MCP Server是一个用于高效微调大语言模型的服务器,通过优化技术实现2倍速度提升和80%内存节省。
Unsloth MCP Server是一个用于高效微调大语言模型的服务,基于Unsloth库实现2倍加速和80%内存节省,支持多种模型和量化技术。
 TransformersMultiple Languages
TransformersMultiple Languages%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)