清华大学智能产业研究院联合水木分子开源了生物医药大模型插件集OpenBioMed Skills,将专家决策流程转化为可执行的Agent Skill代码。首批发布的45项核心技能覆盖生物化学与药物研发、蛋白质分析设计、单细胞组学分析及数据检索等五大领域,旨在降低生物医学研发的工程门槛,推动全流程智能化。
Anthropic公司宣布其AI助手Claude已符合HIPAA医疗合规要求,可合法处理敏感健康数据,正式进军医疗领域。该服务面向医院、机构及个人用户,并整合了多种科学数据库以增强生物医学研究支持能力。
特朗普签署行政命令,拨款5000万美元推动人工智能在儿童癌症研究中的应用。此举在联邦机构加大AI采纳的背景下进行,但面临生物医学研究经费削减和部分拨款暂停的矛盾。白宫科技政策办公室主任表示,该命令由“让美国再次健康委员会”与科技政策办公室负责执行。
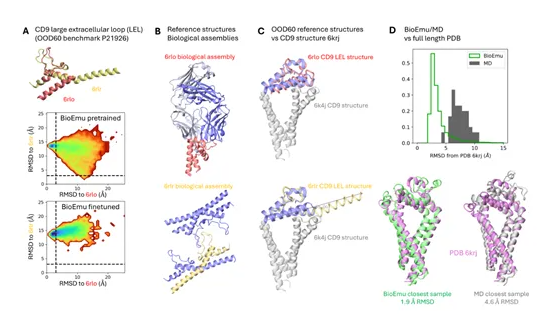
微软发布革命性BioEmu模型,将蛋白质动态模拟时间从数年缩短至数小时。该模型基于AlphaFold2改进,采用序列编码器和扩散生成技术,能生成多样化蛋白质构象。通过200毫秒分子动力学数据训练,显著提升模拟精度。这一突破将极大加速药物研发和生物医学研究,已在《自然》期刊发表。
AI系统设计新型蛋白质,助力生物和健康研究。
跳到主要内容 Chrome 应用商店探索扩展程序
Anthropic
$105
Input tokens/M
$525
Output tokens/M
200
Context Length
Alibaba
$54
$163
1k
Bytedance
$0.8
$8
256
Google
-
$140
$280
32
Tencent
$0.5
$2
224
$8.75
$70
Openai
$14
$56
$2.4
$9.6
$21
$84
128
$420
01-ai
4
Baichuan
OpenMed
专门用于疾病实体识别的模型,能够精准识别来自NCBI数据集的疾病实体,为生物医学领域的研究和临床应用提供有力支持。
这是一款专门用于化学实体识别的模型,能够精准识别生物医学文献中的化合物和物质,为生物医学研究和临床应用提供有力支持。该模型在BC4CHEMD数据集上训练,具有高精度和特定领域优化的特点。
这是一款专门用于生物医学实体识别的高精度模型,基于deberta-v3-base架构微调而成,可识别蛋白质、DNA、RNA、细胞系和细胞类型等生物医学实体,为临床和研究应用提供了企业级解决方案。
OpenMed-NER-ChemicalDetect-MultiMed-568M是一款专门用于化学实体识别的生物医学NLP模型,能够在生物医学文献中精准识别化学化合物和物质。该模型基于bge-m3架构,在BC4CHEMD数据集上训练,达到0.9459的F1分数,为生物医学研究和临床应用提供有力支持。
专用于生物医学实体识别的模型,能够精准识别多种生物医学实体,为临床和研究应用提供有力支持。
这是一个专门用于生物医学领域物种实体识别的模型,基于BiomedELECTRA架构,在SPECIES800数据集上训练,能够精准识别物种名称,为生物医学研究和应用提供支持。
这是一款专门用于基因实体识别的生物医学命名实体识别模型,基于BiomedBERT架构在GELLUS数据集上微调而成,能够精准识别与基因相关的实体,为生物医学研究和临床应用提供有力支持。
OpenMed-NER-PharmaDetect-BioPatient-108M是一款专业的化学实体识别模型,专门针对生物医学文本进行优化。该模型在BC5CDR_CHEM数据集上训练,能够精准识别和提取化学实体,适用于药物相互作用检测、患者记录药物提取等多种临床和研究应用场景。
这是一款专门用于疾病实体识别的生物医学模型,基于BiomedELECTRA-large架构,拥有3.35亿参数。该模型在BC5CDR数据集上训练,能够精准识别疾病实体,为临床和研究应用提供高精度的命名实体识别能力。
这是一款专门用于基因实体识别的模型,基于xlm-roberta-large架构,拥有560M参数。该模型在GELLUS数据集上训练,能够精准识别与基因相关的实体,为生物医学和遗传学研究提供有力支持。
专为疾病实体识别设计的Transformer模型,能够从NCBI数据集中精准识别疾病实体,为生物医学领域的研究和临床应用提供支持。
这是一款专门用于基因/蛋白质实体识别的模型,能够精准识别和提取生物医学文本中的基因和蛋白质提及信息。该模型在BC2GM数据集上训练,具有高精度和特定领域优化,为临床和研究应用提供可靠支持。
OpenMed-NER-DNADetect-BioMed-109M 是一款专门用于生物医学命名实体识别(NER)的模型。它基于 BiomedELECTRA 架构微调,擅长从临床文本和研究论文中准确识别蛋白质、DNA、RNA、细胞系和细胞类型等关键生物医学实体。该模型在 JNLPBA 数据集上训练,具有高精度和易于集成的特点,适用于药物发现、临床记录分析和生物医学知识图谱构建等场景。
这是一款专门用于疾病实体识别的生物医学命名实体识别模型,基于PubMed数据训练,能够从NCBI数据集中精准识别疾病实体,为生物医学领域的研究和临床应用提供有力支持。
OpenMed-NER-ProteinDetect-MultiMed-568M是一款专为生物医学实体识别打造的先进模型,基于bge-m3架构,拥有568M参数。该模型在FSU数据集上训练,能够精准识别多种生物医学实体,包括蛋白质、蛋白质复合物、蛋白质家族等,在临床和研究应用中具有极高的实用价值。
这是一款专门用于化学实体识别的生物医学命名实体识别模型,基于BiomedBERT架构在BC4CHEMD数据集上训练,能够精准识别生物医学文献中的化合物和物质,为药物发现和临床研究提供支持。
这是一款专业的化学实体识别模型,能够精准识别生物医学文献中的化合物和物质,为生物医学研究和临床应用提供有力支持。该模型在BC4CHEMD数据集上训练,具有高精度和特定领域优化的特点。
专门用于化学实体识别的模型,能够从BC5CDR数据集中精准识别和提取生物医学实体,在临床和研究应用中具有极高的可靠性。
nlpie
PPACE是一款80亿参数的大语言模型,专为生物医学资助项目摘要的自动分类而设计,支持世界卫生组织研究优先级分类。
ContactDoctor
基于Llama-3-8B-Instruct微调的多模态生物医学模型,支持文本与图像处理,适用于生物医学领域的研究与临床应用。
一个集成了Reactome、KEGG、UniProt、OMIM等14个生物医学数据库API的MCP服务器,提供100多种工具用于基因、蛋白质、通路、疾病、药物和临床试验等研究数据的查询与分析。
PubMed MCP服务器是一个基于Model Context Protocol的接口服务,为AI代理和研究工具提供PubMed生物医学文献数据库的全面访问能力。支持文献搜索、元数据获取、引用分析、研究计划生成和数据可视化等功能,通过NCBI E-utilities API实现高效集成。
BioContextAI知识库MCP是一个为生物医学研究设计的模型上下文协议服务器,提供AI系统与生物医学资源之间的标准化连接层,支持多种生物医学数据库和工具的集成访问。
 TransformersMultiple Languages
TransformersMultiple Languages%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)