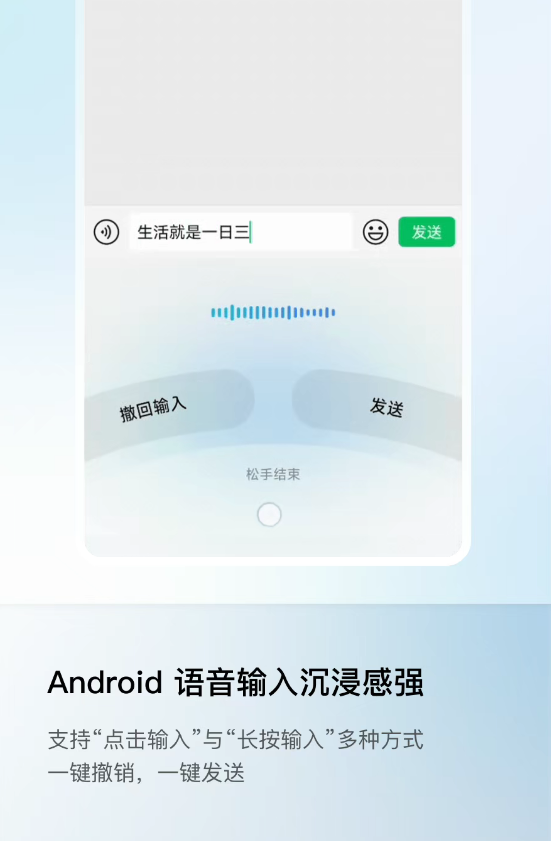
微信输入法iOS新版内测,核心升级语音输入。底层大模型优化,识别更快更准。最大亮点是原生支持多语言与多方言,用户说中文、英文或多种方言时,系统可自动识别,无需手动切换。
Speechify在Chrome扩展中新增语音检测功能,支持语音输入和语音助手,旨在提升文档处理效率。该功能利用先进语音识别技术,实时纠错并自动删除多余填充词,帮助用户在竞争激烈的语音工具市场中脱颖而出。
字节跳动推出“豆包输入法”,安卓版已上线,iOS版即将发布。它基于豆包App语音模型,提升语音识别、语义理解和键盘输入效率,支持方言、英语及中英混合输入,适应轻声、快语和嘈杂环境,核心功能是语音后自动纠错。
Meta推出Omnilingual ASR自动语音识别系统,支持转录超1600种口语语言,旨在解决AI工具语言覆盖不足问题。该系统突破传统仅专注少数主流语言的局限,推动实现“通用转录系统”目标,助力弥合全球数千种语言缺乏AI支持的差距。
一款高质量的英语自动语音识别模型,支持标点符号和时间戳预测。
开源工业级自动语音识别模型,支持普通话、方言和英语,性能卓越。
开源的工业级普通话自动语音识别模型,支持多种应用场景。
PengChengStarling 是一个基于 icefall 项目的多语言自动语音识别(ASR)模型开发工具包。
Anthropic
$105
Input tokens/M
$525
Output tokens/M
200
Context Length
$21
Alibaba
$8
$240
52
$3.9
$15.2
64
$15.8
$12.7
-
Bytedance
Xai
$1.4
$10.5
256
$2.4
$12
8
$0.3
32
$1.6
$10
$1.5
$4.5
128
$3
$9
Huawei
Openai
$0.7
$2.8
1k
Google
$0.35
131
kyr0
这是一个专为苹果硅芯片设备优化的自动语音识别模型,通过转换为MLX框架并量化为FP8格式,实现在苹果设备上的快速端上语音转录。该模型针对逐字精度进行微调,特别适用于需要高精度转录的场景。
ai-sage
GigaAM-v3是基于Conformer架构的俄语自动语音识别基础模型,拥有2.2-2.4亿参数。它是GigaAM系列的第三代模型,在70万小时俄语语音数据上使用HuBERT-CTC目标进行预训练,在广泛的俄语ASR领域提供最先进的性能。
abr-ai
这是一个由Applied Brain Research(ABR)开发的基于状态空间模型(SSM)的英文自动语音识别模型,拥有约1900万参数,能够高效准确地将英文语音转录为文本。该模型在多个基准数据集上表现出色,平均单词错误率仅为10.61%,支持实时语音识别并可在低成本硬件上运行。
adoamesh
本模型是基于OpenAI Whisper-small模型针对斯瓦希里语进行微调的自动语音识别模型。在FLEURS-SLU数据集的斯瓦希里语部分进行训练,显著提升了斯瓦希里语的转录准确率,单词错误率相比基础模型降低了68%。
thenexthub
这是一个支持多语言处理的多模态模型,涵盖自然语言处理、代码处理、音频处理等多个领域,能够实现自动语音识别、语音摘要、语音翻译、视觉问答等多种任务。
teckedd
本模型是基于OpenAI Whisper-small在Common Voice 17.0数据集上微调的自动语音识别模型,专门针对Twi语言进行优化,能够实现语音内容的准确识别。
Ken-Z
本模型是基于OpenAI Whisper-small在拉丁语上微调的自动语音识别模型,使用67小时拉丁语音频数据训练,字符错误率(CER)为20,支持拉丁语语音转文本任务。
eustlb
这是一个基于Hugging Face Transformers库的自动语音识别模型,能够将音频内容转换为文本。该模型支持多种语言,适用于实时语音转文字、音频转录等场景。
Vikhrmodels
Borealis 是首款面向俄语的自动语音识别(ASR)音频大语言模型,经过约7000小时俄语音频数据训练。该模型支持识别音频中的标点符号,架构受Voxtral启发但有所改进,在多个俄语ASR基准测试中表现优异。
feelmadrain
这是一个基于OpenAI Whisper Small架构的俄语自动语音识别模型,在Common Voice 17.0数据集上进行了专门训练,能够准确地将俄语语音转换为文本。
BUT-FIT
SE-DiCoW是由BUT Speech@FIT联合JHU CLSP/HLTCOE和CMU LTI开发的目标说话人多说话人自动语音识别模型。该模型基于Whisper large-v3-turbo,通过自注册机制和改进的数据增强技术,在高度重叠的多说话人场景下显著提升了识别准确率。
UsefulSensors
Moonshine Tiny是由Moonshine AI(原有用传感器公司)开发的轻量级越南语自动语音识别模型,仅有27M参数,专为资源受限平台设计,在Fleurs和Common Voice 17数据集上表现出色。
FluidInference
parakeet-tdt-0.6b-v3 是一款强大的多语言自动语音识别模型,支持英语、西班牙语、法语、德语等多种欧洲语言,基于FastConformer-TDT架构,使用公开数据集训练,为跨语言语音识别提供高效解决方案。
istupakov
NVIDIA Parakeet TDT 0.6B V3是一个多语言自动语音识别模型,参数量为6亿,支持包括英语、西班牙语、法语、德语等25种欧洲语言,可将语音转换为文本。
NexaAI
基于OpenAI Whisper架构微调的自动语音识别和语音翻译模型,通过减少解码层数量实现显著速度提升,同时保持接近原版的识别质量。
AbdelrahmanHassan
本模型是基于OpenAI的Whisper Large V3模型,使用LoRA方法在埃及阿拉伯语方言数据集(Egyptian-ASR-MGB-3)上进行微调的自动语音识别模型。它专门优化了对埃及阿拉伯语方言的识别能力,显著提升了在该方言上的词错误率(WER)性能。
mradermacher
这是一个基于Gemma模型的静态量化版本,适用于自动语音识别、自动语音翻译等多种任务。
Parakeet TDT 0.6B v2 MLX是一款高效的自动语音识别模型,支持标点、大小写和精确时间戳预测,能够转录长达24分钟的音频片段,适用于商业和非商业用途。
kimthegarden
基于Whisper-small架构微调的韩语自动语音识别模型,在韩语语音识别任务上表现出色。
amedcj
针对库尔德语库尔曼吉方言的自动语音识别模型,基于Whisper架构微调
ASR MCP服务器是一个基于whisper引擎的自动语音识别服务,通过MCP工具提供语音合成功能,便于应用集成。
 TransformersEnglish
TransformersEnglish%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)