火山引擎发布多项AI更新,豆包视觉模型升级,Seedream4.5增强图像创作功能,Seedance1.5Pro推出视频生成模型,加速企业AI普惠。
《纽约时报》起诉AI搜索公司Perplexity,指控其未经授权大量复制并传播其新闻、视频等版权内容,要求法院禁止侵权行为并赔偿损失。这是该报继去年起诉OpenAI和微软后,第二起针对生成式AI的版权诉讼。诉状指出,Perplexity的检索增强生成技术输出内容与原文几乎一致,仅今年8月就向纽时网站发起超17.5万次爬取请求。
快手Kling AI 2.6版本发布,首次集成音频生成功能,支持中英双语对白、歌唱与音效,实现文本、视频、音频一键同步生成。技术采用扩散变换器与3D时空联合注意力架构,提升复杂指令遵守率15%,并增强跨镜头角色一致性。视频输出保持10秒1080P高清,生成成本降低30%。
Quora旗下AI平台Poe推出群聊功能,支持最多200人同时与多种AI模型互动,涵盖文本、图像、视频和音频生成。此举与OpenAI的ChatGPT群聊试点同步,推动AI交互变革,增强用户与亲友或同事的协作交流。
在一个智能白板上生成、编辑和增强图像、视频和文本,一站式创意平台。
AI视频增强器,可将视频提升至8K,一键去模糊、修复和上色。
智能编辑视频和照片的免费AI编辑工具,支持翻译、照片增强、背景移除、图片放大及自动生成字幕。
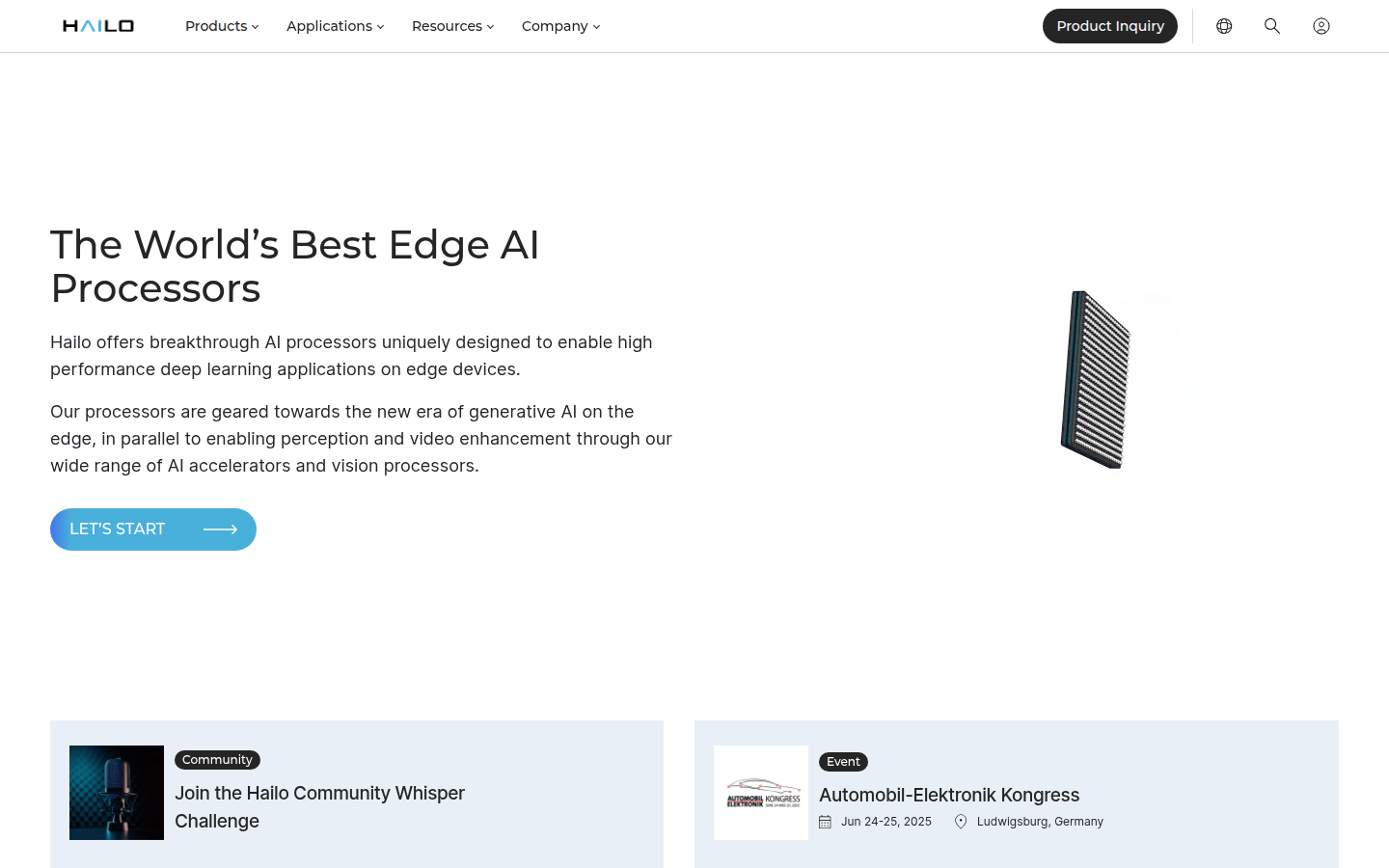
提供AI边缘处理器,专为实现高性能深度学习应用而设计。
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
Google
$2.1
$17.5
Alibaba
$4
$16
$1
$10
256
$2
$20
-
$8
$240
52
$3.9
$15.2
64
$15.8
$12.7
$0.8
128
Bytedance
Baidu
32
Tencent
$1.6
24
unsloth
Qwen3-VL是Qwen系列中最强大的视觉语言模型,实现了全方位的综合升级,包括卓越的文本理解与生成能力、更深入的视觉感知与推理能力、更长的上下文长度、增强的空间和视频动态理解能力,以及更强的智能体交互能力。
Qwen3-VL是Qwen系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力,以及出色的智能体交互能力。该版本为2B参数的思考增强版,专门优化了推理能力。
Qwen3-VL是通义大模型系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力以及出色的智能体交互能力。该模型采用混合专家(MoE)架构,是增强推理的思维版。
bullerwins
Qwen3-VL是通义系列迄今为止最强大的视觉语言模型,实现了全面升级,包括卓越的文本理解与生成能力、更深入的视觉感知与推理能力、更长的上下文长度、增强的空间和视频动态理解能力,以及更强的智能体交互能力。
Qwen3-VL-2B-Thinking是Qwen系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、增强的空间和视频动态理解能力,以及更强的智能体交互能力。该模型采用2B参数规模,支持指令版和增强推理的思考版。
Qwen3-VL-32B-Thinking是Qwen系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力,以及出色的智能体交互能力。该版本采用增强推理的思维架构,支持从边缘到云的密集架构和混合专家模型架构。
Qwen
Qwen3-VL是通义系列最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、增强的空间和视频理解能力,以及强大的智能体交互能力。该模型为2B参数的思考版,专门增强推理能力。
Qwen3-VL-2B-Instruct-FP8是Qwen系列中最强大的视觉语言模型的FP8量化版本,采用块大小为128的细粒度fp8量化,性能与原始BF16模型几乎相同。该模型具备卓越的文本理解和生成能力、深入的视觉感知与推理能力、长上下文支持以及增强的空间和视频动态理解能力。
hyperchainsad
这是一个基于Wan2.2-T2V-A14B基础模型训练的文本到视频LoRA模型,使用AI Toolkit工具包进行训练,专门用于增强文本到视频的转换能力。
spamnco
这是一个基于Wan2.1-T2V-14B模型训练的LoRA适配器,专门用于文本到视频转换任务,为图像生成提供增强功能。该模型使用AI Toolkit训练,需要特定的触发词'diddly'来激活图像生成。
Qwen3-VL是Qwen系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频动态理解能力,以及出色的智能体交互能力。该版本采用混合专家模型架构,支持增强推理思维功能。
QuantTrio
Qwen3-VL是通义系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、增强的空间和视频动态理解能力以及强大的智能体交互能力。
Qwen3-VL是通义系列中最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、增强的空间和视频动态理解能力,以及强大的智能体交互能力。
OpenGVLab
VideoChat-R1_5-7B是基于Qwen2.5-VL-7B-Instruct构建的视频文本交互模型,支持多模态任务,特别擅长视频问答功能。该模型通过强化微调增强时空感知能力,并采用迭代感知机制来强化多模态推理。
Qwen3-VL是通义系列最强大的视觉语言模型,具备卓越的文本理解与生成能力、深入的视觉感知与推理能力、长上下文支持、强大的空间和视频理解能力,以及出色的智能体交互能力。此版本为235B参数的思考增强版,支持更复杂的推理任务。
Lightricks
基于扩散模型的视频空间分辨率增强工具,专门针对LTX视频模型生成的潜在视频表示进行超分辨率训练
Isotr0py
Ovis2-1B是多模态大语言模型(MLLM)Ovis系列的最新成员,专注于视觉与文本嵌入的结构对齐,具有小模型高性能、强化推理能力、视频与多图处理以及多语言OCR增强等特性。
yeliudev
VideoMind是一个多模态智能体框架,通过模拟类人的认知过程来增强视频推理能力。
VideoMind是一个多模态智能体框架,通过模拟人类思维过程来增强视频推理能力。
VideoMind是一个多模态智能体框架,通过模拟人类思维的处理流程(如任务拆解、时刻定位与验证和答案合成)来增强视频推理能力。
Luma AI的MCP服务器,通过Dream Machine API实现文本/图像生成视频、视频增强及创意内容管理功能
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)