理想汽车OTA8.1版本更新,核心亮点是VLA司机大模型在语言智能方面的重要迭代。此次升级通过强化学习技术,使辅助驾驶更具人性化,提升了出行安全、舒适感和驾驶便捷性,为用户带来更直观的安心体验。
阿里通义Qwen团队推出Soft Adaptive Policy Optimization(SAPO),旨在解决大语言模型强化学习中策略优化不稳定的问题。相比传统硬剪切方法,SAPO通过自适应调整更新幅度,避免过于严格限制,提升训练稳定性和效率。
英伟达与香港大学联合发布Orchestrator模型,拥有8亿参数,能协调多种工具和大型语言模型解决复杂问题。该模型在工具使用基准测试中,以更低成本实现更高准确性,并能根据用户偏好智能选择工具。其训练采用名为ToolOrchestra的新强化学习框架,旨在提升小型模型的协调能力。
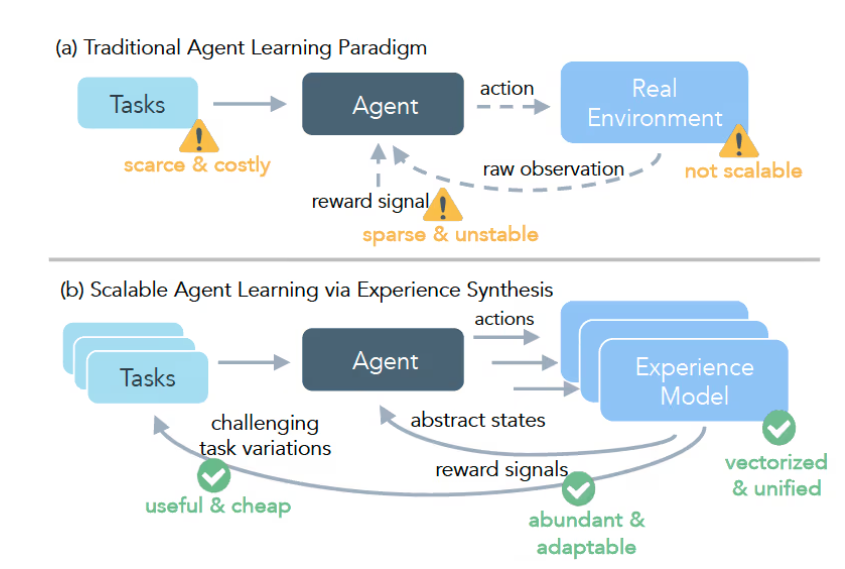
Meta与多所大学合作开发DreamGym框架,通过模拟强化学习环境解决大语言模型训练的高成本与反馈不可靠问题。该框架能动态调整任务难度,帮助模型逐步掌握复杂应用,提升训练效率与可靠性。
That Ish是一款俚语词典应用,助你紧跟潮流,自信交流。
Jolii是一款AI语言学习APP,借助影视音乐,个性化教学助你轻松学语言。
AI驱动语言学习,多门外语轻松掌握,免费且符合CEFR标准
DeepPDF是一个AI研究助手,用于深度学习PDF文档,提供聊天、摘要、翻译比较以及关键术语、图片和公式分析功能。
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
Anthropic
$105
$525
200
$0.7
$7
$35
$17.5
$21
Alibaba
$4
$16
$1
$10
256
Baidu
-
128
$6
$24
$2
$20
$8
$240
52
Bytedance
$1.2
$3.6
4
prithivMLmods
CodeV是基于Qwen2.5-VL-7B-Instruct微调得到的70亿参数视觉语言模型,通过监督微调(SFT)和基于工具感知策略优化(TAPO)的强化学习(RL)两阶段训练,旨在实现可靠、可解释的视觉推理。它将视觉工具表示为可执行的Python代码,并通过奖励机制确保工具使用与问题证据一致,解决了高准确率下工具调用不相关的问题。
ActIO-UI-7B-RLVR 是由 Uniphore 发布的 70 亿参数视觉语言模型,专门用于计算机界面自动化任务。它基于 Qwen2.5-VL-7B-Instruct,通过监督微调和可验证奖励的强化学习进行优化,在 GUI 导航、元素定位和交互规划等任务上表现出色,在 WARC-Bench 基准测试中达到了开源 7B 模型的领先水平。
squ11z1
Hypnos-i2-32B是世界首个采用多物理熵(超导体、真空、核衰变)训练的320亿参数语言模型。它通过输入级量子正则化技术,从三个独立的量子熵源中学习真正的量子随机性,使其注意力机制对对抗性扰动具有鲁棒性,并能有效抵抗模式崩溃。
allenai
Olmo 3是由Allen Institute for AI开发的一系列语言模型,包含7B和32B两种规模,具有指令式和思考式两种变体。该模型在长链式思维方面表现出色,能有效提升数学和编码等推理任务的性能。采用多阶段训练方式,包括有监督微调、直接偏好优化和可验证奖励的强化学习。
Olmo-3-7B-Think-DPO是Allen Institute for AI开发的7B参数语言模型,具有长链式思考能力,在数学和编码等推理任务中表现出色。该模型经过监督微调、直接偏好优化和基于可验证奖励的强化学习等多阶段训练,专为研究和教育用途设计。
Olmo 3 7B RL-Zero Math是Allen AI开发的专为数学推理任务优化的70亿参数语言模型,采用RL-Zero强化学习方法在数学数据集上进行训练,能有效提升数学推理能力。
Olmo 3 7B RL-Zero Mix是Allen AI开发的7B参数规模的语言模型,属于Olmo 3系列。该模型在Dolma 3数据集上进行预训练,在Dolci数据集上进行后训练,并通过强化学习优化数学、编码和推理能力。
Synthyra
Profluent - E1 是对 Profluent Bio 公司 E1 模型的忠实实现,由 Synthyra 发布。它是一个专注于蛋白质序列处理的预训练语言模型,集成了 Hugging Face AutoModel 兼容性,并提供高效的嵌入功能,旨在简化生物信息学任务中的蛋白质序列分析和表示学习。
Profluent-E1 是对 Profluent 官方 E1 模型的忠实实现,集成了 Hugging Face AutoModel 兼容性,专注于蛋白质序列的表示学习。它能够生成高质量的蛋白质序列嵌入,支持掩码语言建模、序列分类和标记分类等任务,并提供了便捷的嵌入提取和微调功能。
BAAI
Emu3.5是北京智源人工智能研究院开发的原生多模态模型,能够跨视觉和语言联合预测下一状态,实现连贯的世界建模和生成。通过端到端预训练和大规模强化学习后训练,在多模态任务中展现出卓越性能。
Mungert
PokeeResearch-7B是由Pokee AI开发的70亿参数深度研究代理模型,结合了AI反馈强化学习(RLAIF)和强大的推理框架,能够在工具增强的大语言模型中实现可靠、对齐和可扩展的研究级推理,适用于复杂的多步骤研究工作流程。
mradermacher
这是PRIME-RL/P1-30B-A3B模型的静态量化版本,是一个300亿参数的大语言模型,专门针对物理、强化学习、竞赛推理等领域优化,支持英语和多语言处理。
Nanbeige
Nanbeige4-3B-Thinking是第四代Nanbeige大语言模型家族中的30亿参数推理模型,通过提升数据质量和训练方法实现了先进的推理能力。该模型在数学、科学、创意写作、工具使用等多个领域表现出色,支持多阶段课程学习和强化学习训练。
Zigeng
dParallel是一种面向大语言模型的可学习并行解码方法,通过挖掘模型内在并行性实现快速采样。该方法能够显著减少解码步骤,同时保持模型性能,在GSM8K和MBPP等基准测试中实现了8.5-10.5倍的加速。
nvidia
Qwen3-Nemotron-32B-RLBFF是基于Qwen/Qwen3-32B微调的大语言模型,通过强化学习反馈技术显著提升了模型在默认思维模式下生成回复的质量。该模型在多个基准测试中表现出色,同时保持较低的推理成本。
Kwaipilot
KAT-Dev-72B-Exp是一款用于软件工程任务的720亿参数开源大语言模型,在SWE-Bench Verified基准测试中达到74.6%的准确率,是KAT-Coder模型的实验性强化学习版本。
通义深度研究30B是一款具有300亿参数的大语言模型,专为长周期、深度信息搜索任务设计。该模型在多个智能搜索基准测试中表现出色,采用创新的量化方法提升性能,支持智能预训练、监督微调与强化学习。
MBZUAI-Paris
Frugal-Math-4B是一款针对数学推理优化的4B参数语言模型,通过强化学习验证奖励(RLVR)方法训练,能够在保持高准确性的同时生成简洁、可验证的数学解决方案,显著减少推理冗长性。
dParallel是一种面向大语言模型的可学习并行解码方法,通过挖掘模型内在并行性实现快速采样,能在保持性能的同时显著减少解码步骤,在GSM8K和MBPP等基准测试中实现8.5-10.5倍的加速效果。
foreverlasting1202
QuestA是一个通过问题增强方法提升大语言模型推理能力的创新框架。它在强化学习训练过程中融入部分解决方案,显著提升了模型在数学推理等复杂任务上的表现,特别是在小参数模型上实现了最优结果。
本项目通过解析PSR.exe生成的MHT文件,让大语言模型学习用户工作流程。
Wrike MCP服务器是一个轻量级实现,用于连接Wrike项目管理平台与语言学习模型(LLM),提供API接口实现任务查询、评论添加和任务创建等功能。
MCP翻译服务器是一个专注于满汉双向翻译的高性能系统,集成了先进的形态分析和深度学习技术,提供全面的低资源语言翻译解决方案。
Mind Map MCP Server是一个实验性的代码智能平台,采用神经科学启发的软件分析方式,提供跨语言API检测、高级代码分析和大脑联想学习等功能。
该项目是一个独立的FastMCP服务器,用于与Cal.com API交互,使语言学习模型(LLM)能够通过工具管理Cal.com的事件类型和预订等功能。
MCP Server是一个基于Go语言的MCP工具项目,提供IP地址处理、时间服务、海报生成等多种功能,主要用于个人学习。
该项目是用于测试和探索模型上下文协议(MCP)服务器实现的GitHub仓库,包含多种编程语言学习、DevOps工具、游戏开发及AI相关的子项目。
医学背景开发者学习多编程语言
 TransformersEnglish
TransformersEnglish%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)