火山引擎发布Seedance 2.0系列API服务,提供先进的视频生成技术,支持文本、图片、音频和视频四种输入方式,具备多模态内容创建与编辑能力,适用于复杂互动和动态场景。该服务旨在帮助企业及个人用户优化工作流程,探索创新应用,同时确保AI视频创作的合规性与安全性。
微软正加速自研尖端AI模型,目标在2027年前实现文本、图像和音频处理能力的行业领先,以挑战OpenAI和Anthropic。此举标志着其AI战略从依赖外部合作转向强化自主核心技术开发。
从手工作坊到智能工厂的产业升级正在音频内容产业悄然发生。面对海量IP因传统制作高成本、低效率而“沉睡”的行业困局,原“懒人听书”核心团队创立的“万象有声”推出系统性解决方案,通过AI技术赋能,有望推动音频行业迎来属于自己的“破局时刻”。
马斯克旗下xAI公司发布Grok Imagine 1.0,实现AI视频生成技术重大突破。该版本支持生成10秒720p高清视频,音频质量显著提升,大幅缩短高质量视频创作时间,标志着AI视频生成领域的重要进展。
基于OpenAI技术,可秒将文本转成含多镜头、同步音频的逼真AI视频
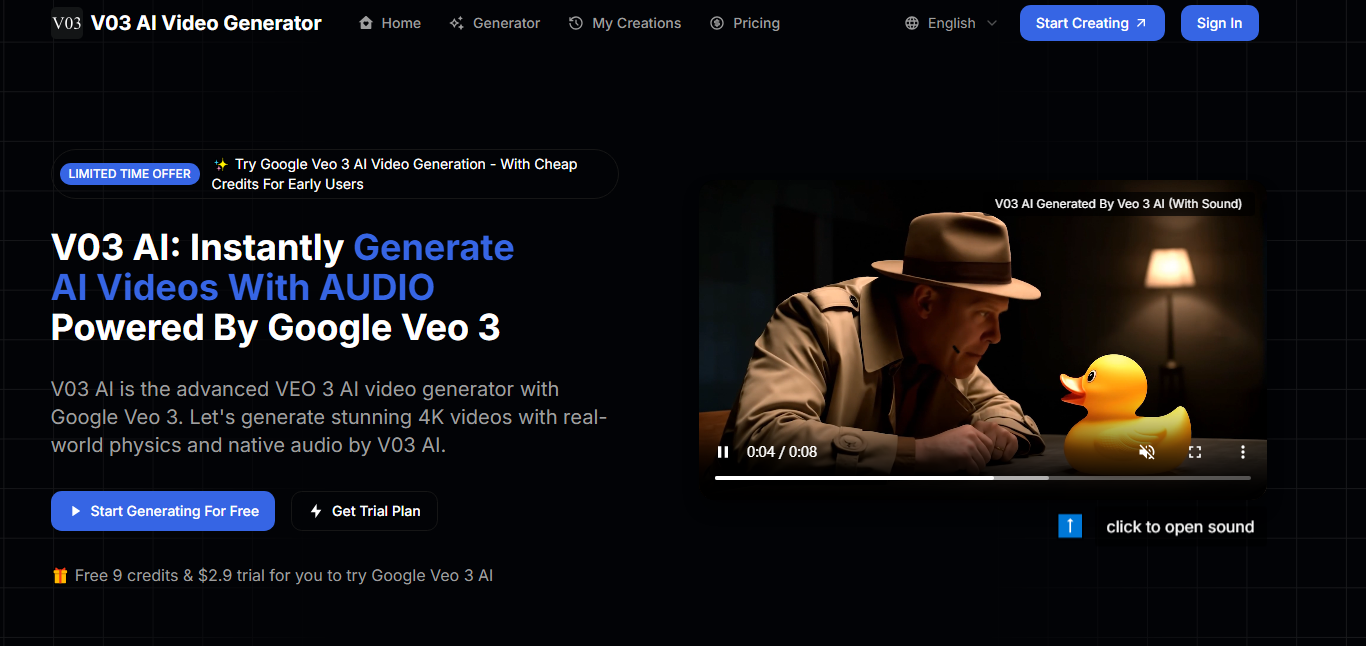
V03 AI是基于Google Veo 3 AI技术的视频生成器,支持文本到视频和图片到视频的转换,具备音频功能。
全球音频感知技术的革命性AI唇同步技术。
JoyGen 是一种音频驱动的 3D 深度感知的说话人脸视频编辑技术。
Google
$0.49
Input tokens/M
$2.1
Output tokens/M
1k
Context Length
Openai
$7.7
$30.8
200
$17.5
Alibaba
$8
$240
52
-
$15.8
$12.7
64
Baidu
Tencent
$0.4
128
Anthropic
$105
$525
Iflytek
$2
$2.4
$12
8
$140
$280
32
FabioSarracino
VibeVoice-Large-Q8是首个真正可用的8位VibeVoice模型,通过选择性量化技术在大幅减小模型尺寸的同时保持与原始模型相同的音频质量,适用于显存有限的场景。
unsloth
Gemma 3n是谷歌推出的轻量级、最先进的多模态开放模型,基于Gemini技术构建。专为低资源设备设计,支持文本、图像、视频和音频输入,生成文本输出。采用选择性参数激活技术,在4B参数规模下高效运行。
DeSTA-ntu
DeSTA2.5-Audio是一个通用的大型音频语言模型,通过自生成的跨模态对齐技术,在无需特定任务指令调优数据的情况下实现高扩展性和效率,同时保留语言能力并避免灾难性遗忘。
mispeech
MiDashengLM 是一款高效的音频理解模型,借助通用音频字幕技术,能出色完成各类音频理解任务,在性能和效率上表现卓越。该模型在多个关键音频理解任务上超越同类模型,具有高效的推理速度和全面的音频理解能力。
google
Gemma 3n是Google推出的轻量级、最先进的开源多模态模型家族,基于与Gemini模型相同的研究和技术构建。支持文本、音频和视觉输入,适用于多种任务。
Gemma 3n是Google推出的轻量级、最先进的开源多模态模型家族,基于与Gemini模型相同的研究和技术构建,支持文本、音频和视觉输入。
saurabhati
DASS是一种基于状态空间架构的音频分类模型,通过知识蒸馏技术从更大的教师模型中学习,在显著减小模型参数量的同时实现了卓越的音频分类性能。
RedHatAI
这是一个基于OpenAI Whisper-large-v3-turbo的量化版本语音识别模型,通过INT8权重量化和激活量化技术,在保持高准确率的同时显著提升推理效率,适用于音频转文本任务。
这是OpenAI whisper-large-v3模型的量化版本,通过INT8权重量化技术显著提升推理性能,专门用于高效的音频文本转换任务。
FunAudioLLM
InspireMusic是一个专注于音乐生成、歌曲生成和音频生成的统一框架,通过音频标记化技术整合自回归变换器与基于流匹配模型,支持高质量长音频生成。
declare-lab
TangoFlux是一个高效的文本转音频生成系统,结合流匹配与CLAP偏好优化技术,能够快速生成高质量音频。
nvidia
NVIDIA低帧率语音编解码器是一种神经音频编解码器,利用有限标量量化和与大型语音语言模型的对抗训练技术,以1.89 kbps的比特率和每秒21.5帧实现高质量音频压缩,支持多种语言。
jadechoghari
QAMDT是一种面向文本生成音乐的质量感知扩散模型,通过创新训练技术提升音频保真度和音乐表现力。
Tango 2是基于Tango改进的文本转音频生成模型,通过直接偏好优化(DPO)技术实现音频生成的对齐训练
sail-rvc
这是一个基于RVC(Retrieval-based Voice Conversion)技术的语音转换模型,可以将输入音频转换为皮卡丘风格的语音。
这是一个基于RVC(Retrieval-based Voice Conversion)技术的语音转换模型,能够将输入音频转换为类似奥巴马的声音。
这是一个基于RVC(Retrieval-based Voice Conversion)技术的语音转换模型,能够将输入音频转换为特定风格的语音。
这是一个基于RVC(Retrieval-Based-Voice-Conversion)技术的语音转换模型,能够将输入音频转换为特定音色的输出音频。
基于RVC技术的语音转换模型,支持将输入音频转换为特定音色的输出音频
这是一个基于RVC(Retrieval-based Voice Conversion)技术的音频转换模型,能够将输入音频转换为特定风格的语音。
RAGStack-Lambda是一个基于AWS Lambda的无服务器AI文档与媒体处理平台,支持上传文档、图片、视频和音频,通过OCR、转录和向量化技术构建知识库,并提供带来源追溯的AI聊天功能。采用按需付费的零闲置成本架构。
一个基于MCP协议的AI语音呼叫系统,通过VoIP技术让Claude等AI助手能够自动拨打电话并进行智能对话,支持多种SIP协议和音频编解码器。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)