谷歌推出自研AI图像生成模型Nano Banana 2 Lite,主打速度与低成本。核心亮点为超低延迟,仅4秒即可生成高质量图像,较标准版显著提速。该特性使其特别适用于专业场景下需要快速迭代方案或大批量产出图像的创意工作。
北大与DeepSeek联合开源大模型推理加速框架DSpark,针对自回归生成中每词元均需全算力导致的高并发延迟与算力浪费,提供突破性解决方案。
Google发布全新开源大模型Gemma412B,采用“Unified”无编码器架构,突破端侧全模态AI。该模型无需传统视觉、音频外部编码器,直接输入文字、图像、音频、视频四种模态数据至同一Transformer主干网络处理,消除了外挂“翻译”模块带来的显存占用和高延迟问题。
OpenAI于5月27日深夜至28日凌晨修复了ChatGPT及API服务响应缓慢问题。故障始于27日凌晨,表现为用户提问后回复延迟显著增加,官方于22时47分确认出现“高延迟”故障。经紧急排查修复,服务已恢复正常。
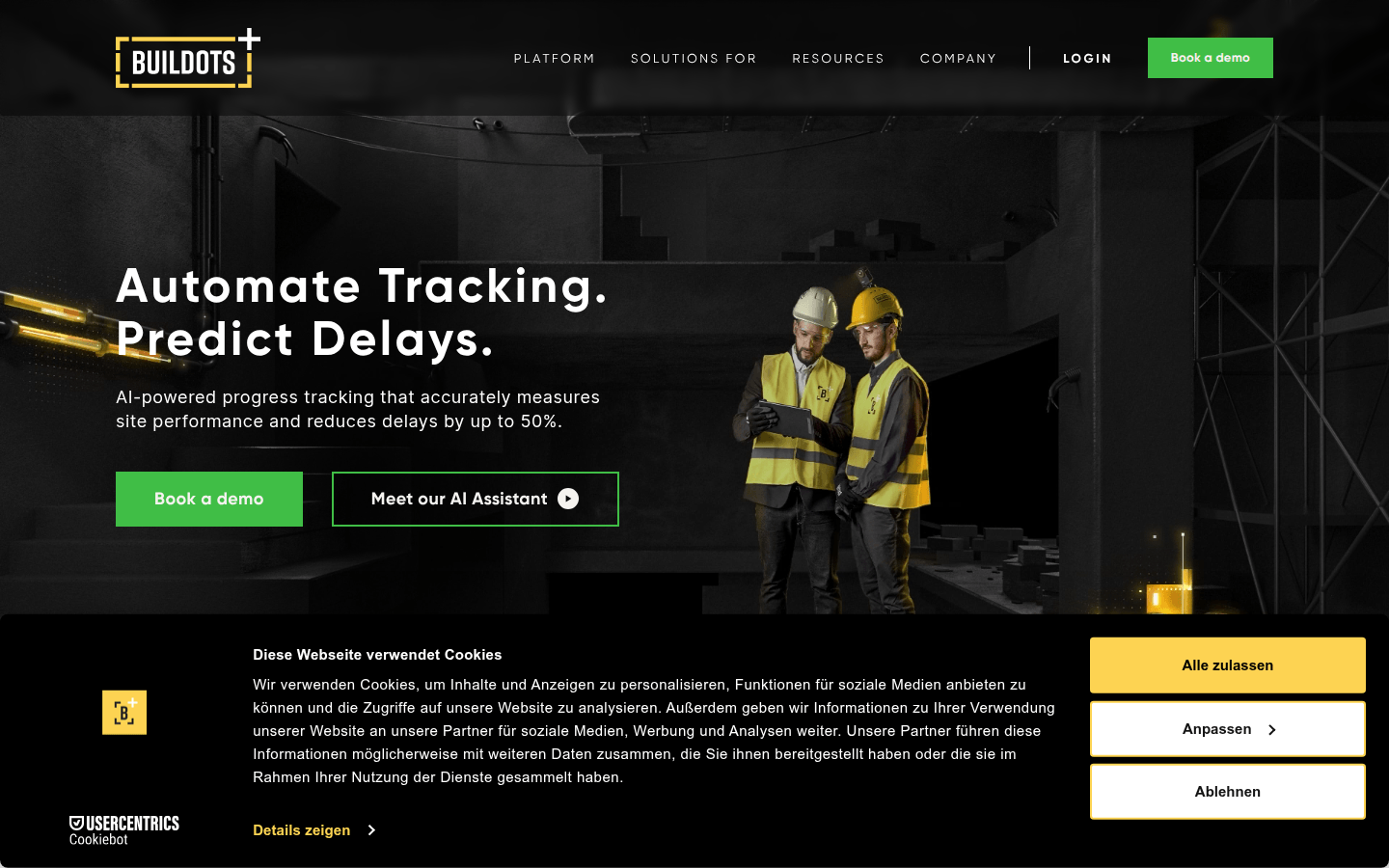
AI 助力的进度跟踪,精准测量工地表现,减少延迟高达50%。
Mistral Small 3 是一款开源的 24B 参数模型,专为低延迟和高效性能设计。
一个具有先进语音活动检测、唤醒词激活和即时转录功能的稳健、高效、低延迟的语音到文本库。
低延迟、高质量的端到端语音交互模型
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
Google
$0.49
$2.1
$7.7
$30.8
200
$0.7
Anthropic
$7
$35
$17.5
$21
$105
Baidu
-
128
Alibaba
$8
$240
52
Bytedance
$1.2
$3.6
4
$2
256
$0.8
$0.15
$1.5
Xai
$1.4
$10.5
Tencent
$0.4
drbaph
Z-Image(造相)是一个拥有60亿参数的高效图像生成基础模型,专门解决图像生成领域的效率和质量问题。其蒸馏版本Z-Image-Turbo仅需8次函数评估就能达到或超越领先竞品,在企业级H800 GPU上可实现亚秒级推理延迟,并能在16G VRAM的消费级设备上运行。
redponike
MiniMax-M2是一款专为高效编码和智能体工作流打造的混合专家模型,具备2300亿总参数和100亿激活参数。该模型在编码和智能体任务中表现卓越,同时具有低延迟、低成本和高吞吐量的特点,能有效提升工作效率。
TheStageAI
TheWhisper-Large-V3-Turbo 是 OpenAI Whisper Large V3 模型的高性能微调版本,由 TheStage AI 针对多平台实时、低延迟和低功耗语音转文本推理进行优化。支持流式转录、单词时间戳和可扩展性能,适用于实时字幕、会议和设备端语音界面等场景。
TheWhisper-Large-V3是OpenAI Whisper Large V3模型的高性能微调版本,由TheStage AI针对多平台(NVIDIA GPU和Apple Silicon)的实时、低延迟和低功耗语音转文本推理进行了优化。
gravitee-io
这是一个专门用于压缩短用户提示(≤64个标记)的序列到序列模型,在现代GPU上可实现亚100毫秒的低延迟运行,作为轻量级预处理阶段为高容量大语言模型提供支持。
nineninesix
KaniTTS是一款专为实时对话式AI应用优化的高速、高保真文本转语音模型,通过独特的两阶段架构结合大语言模型与高效音频编解码器,实现低延迟与高质量语音合成,实时因子低至0.2,比实时速度快5倍。
rtr46
meiki.text.detect.v0.1是专门针对视频游戏和漫画文本检测的高精度、低延迟OCR模型,在日语相关内容上表现优异。该模型基于D-FINE检测器架构,采用MobileNet v4 small作为骨干网络,提供两种分辨率变体以适应不同应用场景。
KaniTTS Pretrain v0.3是一款高速、高保真的文本转语音模型,专为实时对话式人工智能应用优化,采用两阶段管道架构,结合大语言模型和高效音频编解码器,实现极低延迟和高品质语音合成。
nvidia
Nemotron-Flash-3B 是英伟达推出的新型混合小型语言模型,专门针对实际应用中的低延迟需求设计。该模型在数学、编码和常识推理等任务中展现出卓越性能,同时具备出色的小批量低延迟和大批量高吞吐量特性。
KaniTTS是一款高速、高保真的文本转语音模型,专为实时对话式人工智能应用而优化。该模型采用两阶段处理流程,结合大语言模型和高效音频编解码器,在Nvidia RTX 5080上生成15秒音频的延迟仅需约1秒,MOS自然度评分达4.3/5,支持英语、中文、日语等多种语言。
FlashVL
FlashVL是一种优化视觉语言模型(VLMs)以用于实时应用的新方法,旨在实现超低延迟和高吞吐量,同时不牺牲准确性。
TEN-framework
TEN VAD 是一个低延迟、轻量级、高性能的流式语音活动检测系统,适用于实时语音处理场景。
microsoft
Phi-4是微软研究院开发的一款140亿参数的开源语言模型,专注于高质量数据和高级推理能力,适用于内存/计算受限环境和延迟敏感场景。
webis
该模型是基于BERT的ColBERT模型,用于高效段落搜索,通过上下文延迟交互实现。
Zyphra
Zamba2-2.7B是一个由状态空间和Transformer模块组成的混合模型,采用Mamba2模块和共享注意力模块,具有高性能和低延迟特点。
onnx-community
YOLOv10是一种实时端到端目标检测模型,具有高效的延迟-精度和尺寸-精度权衡。
snap-research
EfficientFormer-L3是由Snap Research开发的轻量级视觉Transformer模型,专为移动设备优化,在保持高性能的同时实现低延迟。
EfficientFormer-L1是由Snap Research开发的视觉Transformer模型,专为移动设备优化,在保持高性能的同时实现极低延迟。
一个高性能的SQLite MCP服务器,采用创新的Codemode代码生成方法,使LLM通过生成Go代码执行数据库操作,相比传统工具调用显著提升效率和降低延迟。
RegenNexus UAP是一个通用适配器协议,用于连接设备、机器人、应用和AI代理,提供低延迟、高安全性的通信,支持多种硬件和MCP集成。
Memory MCP是一个为AI助手提供持久记忆的MCP服务器,通过热缓存和冷存储两层架构,实现高频知识的零延迟自动注入和语义搜索,让Claude记住项目上下文,减少重复解释。
AgentREPL.jl 是一个通过 MCP 协议为 AI 代理提供持久化 Julia REPL 会话的工具,解决了 Julia 启动和编译延迟问题,使 AI 代理能高效执行代码。
Shebe是一个基于BM25算法的快速代码全文搜索服务,专为Claude Code设计,提供低延迟、高效率的代码内容检索,支持多语言代码库搜索和符号引用查找。
 TransformersOther
TransformersOther%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
'%3e%3cpath%20d='M55.2622%2038L48.2289%2022L44.1206%2031.3333H47.2539L45.7872%2034.6667H38.7622L46.0956%2018H37.6706C36.7539%2018%2036.0039%2018.75%2036.0039%2019.6667V36.3333C36.0039%2037.25%2036.7539%2038%2037.6706%2038H55.2622Z'%20fill='white'/%3e%3cpath%20d='M64.3368%2018H50.3535L59.1535%2038H64.3368C65.2535%2038%2066.0035%2037.25%2066.0035%2036.3333V19.6667C66.0035%2018.75%2065.2535%2018%2064.3368%2018ZM63.0868%2034.6667H59.7535V21.3333H63.0868V34.6667Z'%20fill='%23FFCC66'/%3e%3cpath%20d='M89.3379%2026.75V29.25H81.8379V36.75H91.8379V24.25H81.8379V26.75H89.3379ZM84.3379%2034.25V31.75H89.3379V34.25H84.3379Z'%20fill='white'/%3e%3cpath%20d='M103.504%2036.75V29.25H96.0039V26.75H103.504V24.25H93.5039V31.75H101.004V34.25H93.5039V36.75H103.504Z'%20fill='white'/%3e%3cpath%20d='M115.17%2026.75V24.25H105.17V36.75H115.17V34.25H107.67V31.75H115.17V29.25H107.67V26.75H115.17Z'%20fill='white'/%3e%3cpath%20d='M80.1712%2029.25V29.175L78.9962%2028L80.1712%2026.825V20.425L78.9962%2019.25H69.3379V36.75H78.9962L80.1712%2035.575V29.25ZM77.6712%2034.25H71.8379V29.25H77.6712V34.25ZM77.6712%2026.75H71.8379V21.75H77.6712V26.75Z'%20fill='white'/%3e%3c/g%3e%3cg%20clip-path='url(%23clip1_644_3948)'%3e%3cpath%20d='M169.59%2022.9827L169.59%2023.6491H177.409L168.175%2032.8822L169.118%2033.8248L178.351%2024.5917L178.352%2032.4106H179.685V22.3164L179.018%2022.3157H169.59V22.9827Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_644_3948'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(36%2018)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_644_3948'%3e%3crect%20width='20'%20height='20'%20fill='white'%20transform='translate(164%2018)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)