Mistral AI發佈新一代文檔識別技術Mistral OCR3,在表格、掃描文檔、複雜表格及手寫識別方面表現突出,整體性能較上一代提升74%。該技術旨在高效準確提取各類文檔中的文本和嵌入式圖像,支持多格式處理,顯著提升文檔處理效率與精度。
Apache Doris 4.0 正式發佈,聚焦AI驅動、搜索增強和離線提效三大方向。新增向量索引和AI函數等特性,提升數據處理效率與用戶體驗。通過深度集成向量索引技術,高效處理文本嵌入等高維向量數據,支持用戶在同一平臺使用SQL進行結構化分析。
視覺檢索增強生成(Vision-RAG)與文本檢索增強生成(Text-RAG)在企業信息檢索中的對比研究顯示,Text-RAG需先將PDF轉爲文本再嵌入索引,但OCR技術常導致轉換不準確,影響檢索效率。Vision-RAG則直接處理視覺信息,可能更高效。研究揭示了兩種方法在應對海量文檔時的優缺點,爲企業優化搜索策略提供參考。
谷歌推出開源嵌入模型EmbeddingGemma,專爲移動設備設計。該模型擁有308百萬參數,在MTEB基準測試中被評爲500M以下最佳多語言文本嵌入模型。支持檢索增強生成和語義搜索功能,無需聯網即可在手機上運行,性能優越。
先進的多模態嵌入和重排名模型,支持文本、圖像和視頻。
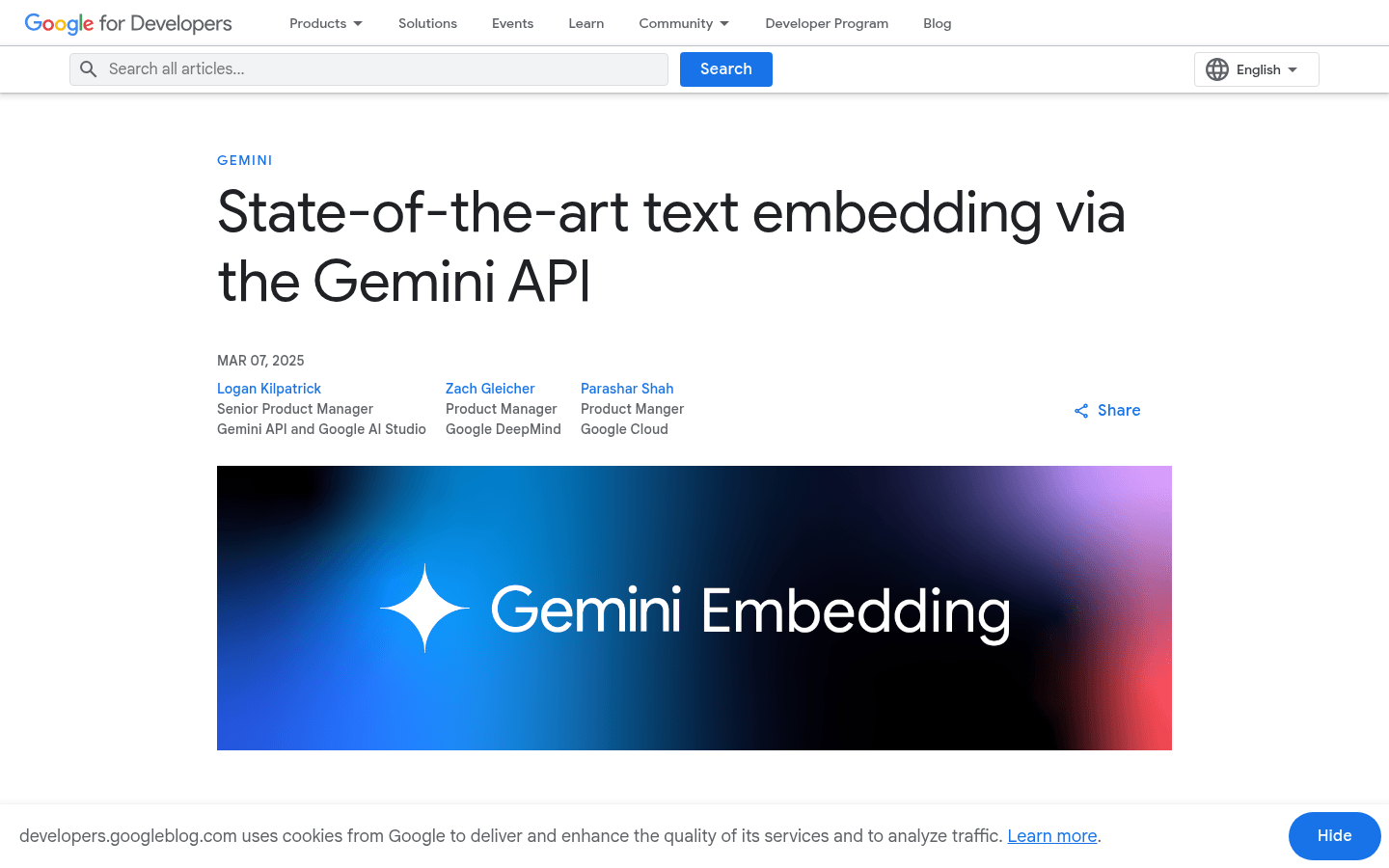
Gemini Embedding 是一種先進的文本嵌入模型,通過 Gemini API 提供強大的語言理解能力。
多語言多模態嵌入模型,用於文本和圖像檢索。
快速的本地矢量推理解決方案
Google
$0.49
輸入tokens/百萬
$2.1
輸出tokens/百萬
1k
上下文長度
Openai
$2.8
$11.2
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$6
$24
256
$4
$16
Baidu
128
Bytedance
$1.2
$3.6
4
$2
TomoroAI
TomoroAI/tomoro-colqwen3-embed-4b是一款先進的ColPali風格多模態嵌入模型,能夠將文本查詢、視覺文檔(如圖像、PDF)或短視頻映射為對齊的多向量嵌入。該模型結合了Qwen3-VL-4B-Instruct和Qwen3-Embedding-4B的優勢,在ViDoRe基準測試中表現出色,同時顯著減少了嵌入佔用空間。
sd2-community
Stable Diffusion v2-1-unclip是基於Stable Diffusion 2.1微調的擴散模型,能夠接受文本提示和CLIP圖像嵌入,用於創建圖像變體或與文本到圖像的CLIP先驗結合使用。
Tarka-AIR
Tarka-Embedding-350M-V1是一個擁有3.5億參數的文本嵌入模型,能夠生成1024維的密集文本表示。該模型針對語義相似性、搜索和檢索增強生成(RAG)等下游應用進行了優化,支持多種語言並具有長上下文處理能力。
AbstractPhil
MM-VAE Lyra是一個專門用於文本嵌入轉換的多模態變分自編碼器,採用幾何融合技術。它結合了CLIP-L和T5-base模型,能夠有效處理文本嵌入的編碼和解碼任務,為多模態數據處理提供創新解決方案。
mradermacher
UME-R1-7B的靜態量化版本,支持句子相似度、嵌入、零樣本圖像分類、視頻文本到文本等多任務。提供多種量化類型以滿足不同需求,從輕量級Q2_K到高質量Q8_0版本。
Tarka-Embedding-150M-V1是一個具有1.5億參數的嵌入模型,可生成768維的密集文本表示。它針對語義相似性、搜索和檢索增強生成(RAG)等多種下游應用進行了優化,專注於捕捉深層上下文語義,以支持跨不同領域的通用文本理解。
nvidia
Llama Nemotron Embedding 1B模型是NVIDIA開發的專為多語言和跨語言文本問答檢索優化的嵌入模型,支持26種語言,能夠處理長達8192個標記的文檔,並可通過動態嵌入大小大幅減少數據存儲佔用。
codefuse-ai
F2LLM是一個基於Qwen3-0.6B微調的開源文本嵌入模型,通過在600萬高質量查詢-文檔對上進行單階段訓練,實現了與當前最優模型相匹配的嵌入性能。該模型專門用於特徵提取任務,支持英文文本處理。
MagicalAlchemist
BGE-M3是由BAAI開發的多功能文本嵌入模型,支持多語言、多粒度、多功能的文本表示學習,能夠同時處理稠密檢索、稀疏檢索和多向量檢索等多種檢索模式。
mlx-community
這是一個轉換為MLX格式的文本嵌入模型,基於Google的EmbeddingGemma-300m模型轉換而來,專門用於句子相似度計算和文本嵌入任務。模型採用BF16精度,適用於蘋果芯片設備上的高效推理。
EmbeddingGemma-300m-8bit是基於sentence-transformers庫實現的句子相似度模型,支持以MLX格式運行,專門用於計算句子嵌入和相似度。該模型從原始模型轉換而來,提供高效的文本特徵提取能力。
EmbeddingGemma 300M 4bit是Google開發的輕量級文本嵌入模型,專門針對MLX框架優化。該模型能夠將文本轉換為高質量的向量表示,適用於各種自然語言處理任務,特別是句子相似度計算和特徵提取。
ggml-org
embeddinggemma-300M是一個經過量化優化的輕量級文本嵌入模型,基於Google的embeddinggemma架構,採用QAT(量化感知訓練)和Q4_0量化技術,參數量為300M。該模型專門用於生成高質量的文本嵌入向量,支持句子相似度計算和特徵提取等任務。
second-state
基於jinaai/jina-embeddings-v3模型進行量化處理的嵌入模型,專為LlamaEdge設計,提供高效的文本嵌入能力,支持多種量化版本以滿足不同場景需求
jinaai
Jina Code Embeddings 是一款專為代碼檢索設計的嵌入模型,基於Qwen2.5-Coder-0.5B構建,支持15種以上編程語言,適用於文本到代碼、代碼到代碼、代碼到文本、代碼到補全等多種代碼檢索任務以及技術問答。
SamilPwC-AXNode-GenAI
PwC-Embedding-expr 是基於 multilingual-e5-large-instruct 嵌入模型訓練的韓語優化版本,通過精心設計的增強方法和微調策略提升在韓語語義文本相似度任務上的性能。
MongoDB
mdbr-leaf-ir 是 MongoDB Research 開發的專為信息檢索任務設計的高性能緊湊型文本嵌入模型,特別適用於 RAG 管道的檢索階段。該模型採用知識蒸餾技術,支持非對稱架構、MRL 截斷和向量量化,在 BEIR 基準測試中表現出色。
sangambhamare
基於SBERT架構的馬拉地語句子嵌入模型,可將文本映射到768維向量空間
IAMJB
RadEvalModernBERT是一個專門針對醫學放射學領域優化的BERT模型,基於現代臨床放射學報告進行訓練,能夠有效處理醫學文本嵌入提取和相似度計算任務。
huynguyendbs
Qwen3-Embedding-8B是阿里巴巴通義千問團隊開發的80億參數文本嵌入模型,基於MLX庫優化實現,專門用於句子相似度計算和文本特徵提取任務。
rag-mcp是一個過度設計的檢索增強生成系統,通過Python服務器提供多種文本搜索模式(語義搜索、問答搜索、風格搜索),使用PostgreSQL和pgvector存儲文本嵌入向量,支持與AI代理交互,架構複雜但可擴展。
mcp-rag-server是一個基於Model Context Protocol (MCP)的服務,支持檢索增強生成(RAG),能夠索引文檔併為大型語言模型提供相關上下文。
一個基於MongoDB Atlas向量搜索和Voyage AI嵌入技術的文檔檢索系統,支持語義搜索和文本匹配,包含文檔分塊、嵌入生成和存儲功能。
一個基於Qdrant向量數據庫的機器控制協議(MCP)服務器,支持文本存儲、語義搜索及FastEmbed嵌入模型集成。
一個基於TypeScript的MCP服務器,用於與Vectra知識庫交互,提供創建集合、嵌入文本/文件、查詢知識庫等功能。
一個強大的Parquet文件處理MCP服務器,提供文本嵌入生成、文件分析、DuckDB/PostgreSQL轉換及Markdown處理功能
一個基於MCP框架的Qdrant向量數據庫服務,提供文本向量化存儲與相似性搜索功能。
該項目提供了一個基於Qdrant的開發容器環境,用於文件嵌入和向量相似性搜索,支持文本、Markdown和PDF文件的自動索引與檢索。
Brain Server是一個基於MCP協議的知識嵌入與向量搜索服務,提供高質量文本向量化、語義搜索和知識管理功能,支持多種嵌入模型和Docker部署。
 Transformers其他
Transformers其他%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)